
1.第一范式(1NF)(列不能再拆分)
原子性,字段不可分(列的信息),只要是关系型数据库,就自动满足1NF;
2.第二范式(2NF)(主键唯一,且被依赖)
在第一范式基础上建立的,即满足第二范式的必须先满足第一范式。要求DB表中的每个实例或行必须可以被唯一区分,通常设计一个主键来实现,其他属性完全依赖主键。
3.第三范式(3NF)(表与其他表间没有关联)
必须满足第二范式,要求一个数据库表中不包含已在其他表中已包含的非主键字段。即:表的信息,如果能够被推导出来,就不应该单独设计一个字段来存放(能尽量外键join就用外键join)。很多时候,为满足第三范式往往会把一张表分成多张表,如:
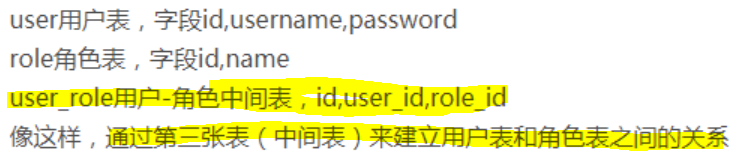
4.反范式
通过增加冗余或重复的数据来提高数据库的读性能。
具体做法:在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,减少了查询时的关联,提高查询效率,因为在数据库的操作中查询的比例要远远大于DML的比例。但是反范式化一定要适度,并且在原本已满足三范式的基础上再做调整。
实际,比如:可以减少关联查询时,jion表的次数,如:在3中,增加字段role_name。
5.范式化优点及缺点:
优点:
.更新操作通常比反范式化要快;
.范式化的表通常更小,没有数据冗余,更省数据库空间,同时可以放在内存,所以执行操作会更快。
.很少有多余数据意味着检索列表数据更少需要distinct或group by语句。
.数据较好的范式化,只有很少或没有重复数据,所以,只需要修改更少的数据。
缺点:
.范式化schema通常需要关联,可能使一些索引策略无效。
.范式等级越高,设计出来的表越多,可能会增加查询需要的时间。
6.反范式化优点及缺点:
优点:
.可以很好避免关联。
.如果不需要关联表,对大部分查询最差情况,没有使用索引,全表扫描,当数据比内存大时,可能比关联快,避免随机IO
7.实际经验
实际中,不会极端使用范式化或反范式化schema,可能使用部分范式化schema、缓存表、及其他技巧。
最常见反范式化数据方法:复制或缓存,在不同表中存储相同的特定列,比如:实际业务涉及的表非常多,表间连接会比较多,对表的操作要尽量快,通常会使用反范式设计,用空间换时间,把数据冗余在多张表中,查询时可以减少或避免表间关联。
参考:https://blog.csdn.net/weixin_33811961/article/details/92142509

 浙公网安备 33010602011771号
浙公网安备 33010602011771号