
1.读取,文件在本地的E盘,一定要加这个file:\\不然不知道是从HDFS还是从本地
val dataPath:String="file:\\E:\\JAVA\\workspacenew\\hudiLearn\\hudi-spark\\src\\main\\resources\\dwv_order_make_haikou_1.txt" val hudiTableName:String="tbl_didi_haikou" val hudiTablePath:String="/hudi-warehouse/tbl_didi_haikou" def readCsvFile(spark: SparkSession, Path: String): DataFrame ={ spark.read .option("seq","\\t") .option("header","true") .option("inferSchema","true") .csv(Path) } def main(args: Array[String]): Unit = { val spark:SparkSession=SparkUtils.createSparkSession(this.getClass) val didiDF:DataFrame=readCsvFile(spark,dataPath) didiDF.printSchema() didiDF.show(10,truncate = false) }
2.遇到的坑
虽然你linux中配置了集群,但是仍然要在本地再重新装一个hadoop,hadoop只有linux,所以你就把你的虚拟机的hadoop包放在windows上解压,同时需要下载两个东西
一个是winutiles,一个是hadoop.dll文件,各个版本对应的在下面这个地址
https://raw.githubusercontent.com/cdarlint/winutils/master/hadoop-2.7.7/
Windows 的 IDEA 中运行 Spark 程序总是报错:Could not locate executable null\bin\winutils.exe in the Hadoop binaries
解决这个bug就需要你安装本地hadoop,并且配置几个文件,安装本地hadoop要给他配置环境变量,以及path中的bin路径。修改几个文件,建议直接搜hadoop的windows安装就行了
参见这两个博客
https://www.freesion.com/article/81981088147/
3.然后就遇到了
No FileSystem for scheme: hdfs
这个需要你有两个包
hadoop-common和hadoop-hdfs,去maven搜名字就行了,在pom.xml中配置
使用idea自带的远程工具,连接你的虚拟机找到core-site和yarn-site复制和hafs-site.xml复制,在core-site中添加下面的代码配置
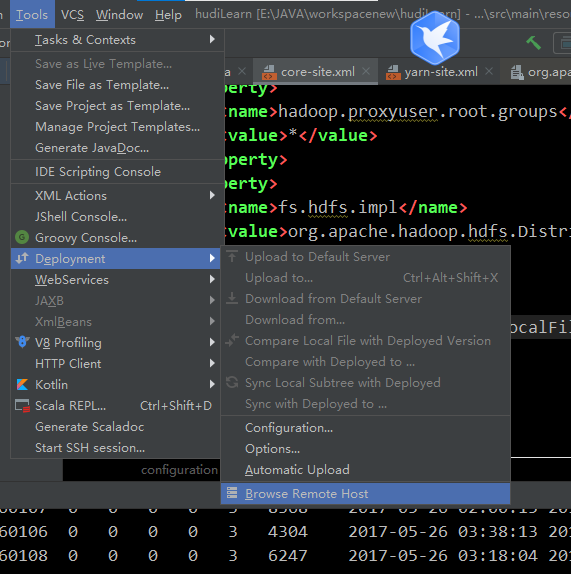
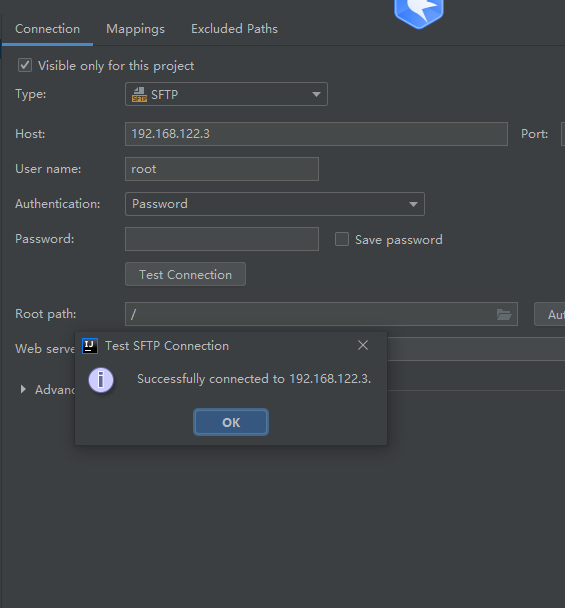
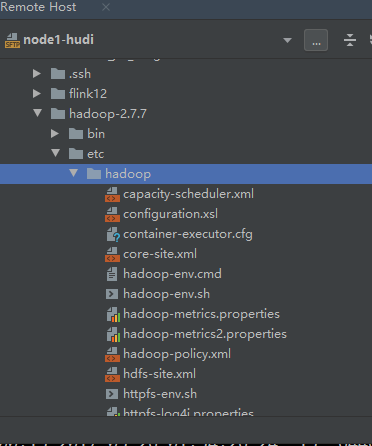
<property>
<name>fs.hdfs.impl</name>
<value>org.apache.hadoop.hdfs.DistributedFileSystem</value>
</property>
<property>
<name>fs.file.impl</name>
<value>org.apache.hadoop.fs.LocalFileSystem</value>
</property>
4. is not a valid DFS filename.
这是不知道文件来自那里,在windows文件地址前面加file:\\


 浙公网安备 33010602011771号
浙公网安备 33010602011771号