
一、项目目录
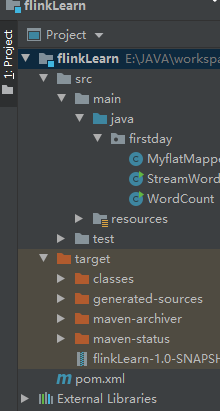
二、有两个类,第一个是StreamWordCount,第二个是MyflatMapper,还有pom.xml文件然后maven compile编译,然后maven package打包,FileZilla Client传输文件到虚拟机
package firstday; import org.apache.flink.api.java.DataSet; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.api.java.operators.DataSource; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.api.java.utils.ParameterTool; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * description: StreamWordCount <br> * date: 2021/12/18 16:13 <br> * author: 纯正肉包 <br> * version: 1.0 <br> * //执行任务,因为是流式数据,所以即使是hello都是一样的,但是来的时间不一样,所以也是不重复的 * //默认并行度是你的cpu的内核数 * //因为文件是有限的,所以还是有限流 * //所以kafuka消息队列,有一个,消费一个,和web系统的相互连接 * //linux自带的netcat * //nc,-lk(listen,接口 * //parametertool,从程序启动参数中提取配置项 * //启动参数就在main方法的args里 * //flink部署:有yearn模式,yearn需要hadoop * //jobManager是运行在一个节点的一个jvm线程 * //flink有一个对外内存,我们之前说把流数据定义在本地内存,就是放在这个对外内存的taskManager * //实际上的taskManager作为干活的人,实际生产环境要比jobManager更大,jobManager只是负责线程调度 * //numberofSlot,就是有几个节点就配置几个taskManager,进行多线程调用 * //rest&Webfront.访问8081就能看到集群的页面 * //在代码中默认parallelism是你的内核数,但是到集群环境里,默认你得taskManager配的 * //优先级,代码--全局conf--dashboard仪表盘的。从高到低 * //text作为一个文本流,所以读入时候只能串行读入 * //过程可以在dashboard中的show plan中看到 */ public class StreamWordCount { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env= StreamExecutionEnvironment.getExecutionEnvironment(); // String inputPath="E:\\JAVA\\workspacenew\\flinkLearn\\src\\main\\resources\\hello.txt"; // DataStreamSource<String> source = env.readTextFile(inputPath); // //对于流是动态的,所以你不能使用groupby了,这里使用的是分区,按照key的hashcode进行分区,也就是第0个字段的 // SingleOutputStreamOperator<Tuple2<String, Integer>> resultStream = source.flatMap(new MyflatMapper()).keyBy(0).sum(1); // // 流是数据是需要事件触发的。 //使用kafuka消费队列 //使用netcat,从socket文本流读取数据 ParameterTool parameterTool = ParameterTool.fromArgs(args); String host = parameterTool.get("host"); int port = parameterTool.getInt("port"); DataStreamSource<String> inputDataString=env.socketTextStream(host,port); SingleOutputStreamOperator<Tuple2<String, Integer>> resultStream = inputDataString.flatMap(new MyflatMapper()).keyBy(0).sum(1); resultStream.print(); // resultStream.print(); //执行任务 // parallellism,实际功率,taskslot是针对一个taskManager,分布式中有两个结点,就应该是二 //上到集群默认并行度就是你配置文件写的 //优先级:代码>全局>web页面提交>配置文件为准 //和最大的有关 env.execute(); } }
package firstday; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.util.Collector; /** * description: MyflatMapper <br> * date: 2021/12/18 15:43 <br> * author: 纯正肉包 <br> * version: 1.0 <br> */ public class MyflatMapper implements FlatMapFunction<String, Tuple2<String, Integer>> {//两个泛型,一个输入类型,一个输出类型 public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception { //按照空格分词 String[] words=value.split(" "); for (String word:words){ out.collect(new Tuple2<String, Integer>(word,1)); } //分组,统计每个单词的个数 } }
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>flinkLearn</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.12</artifactId> <version>1.10.1</version> </dependency> </dependencies> </project>
三、启动standalone集群
启动flink:bin/start-cluster.sh
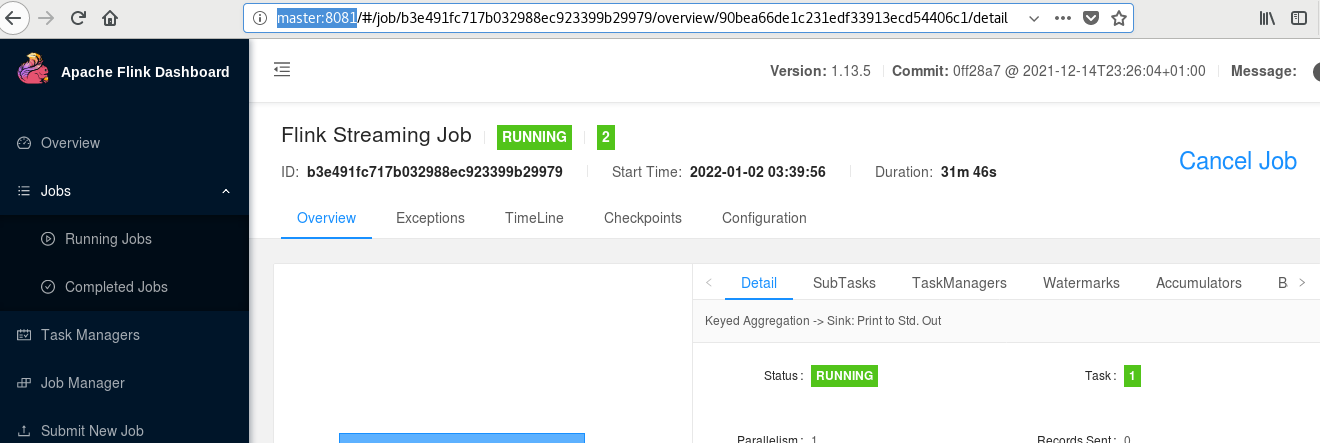
打开窗口:http://master:8081
在linux虚拟机命令行输入:nc -lk 7777 表示一个socket数据流,等下用于测试
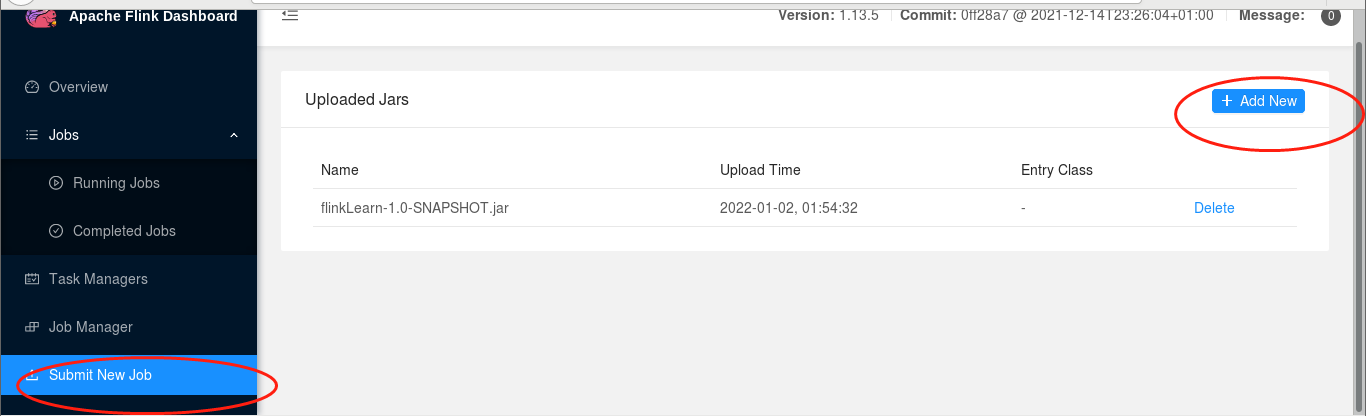
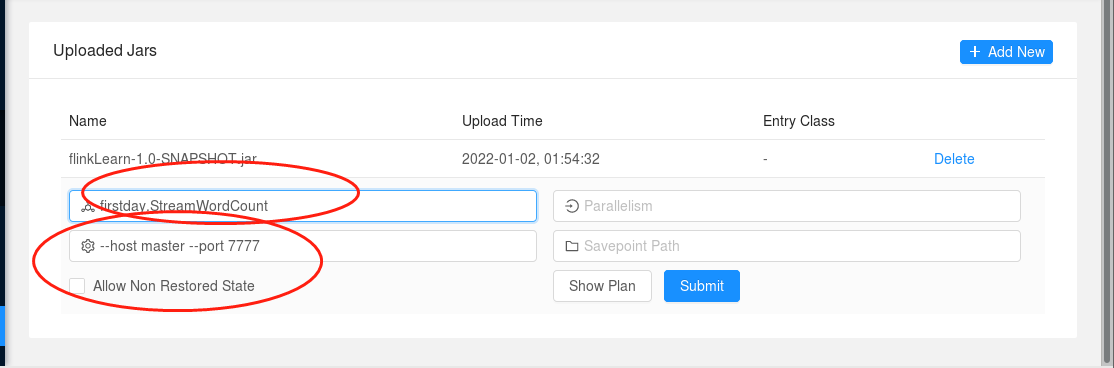
然后按照下图部署你的jar包。然后再你刚才输入nc的那个窗口输入数字就行了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号