
一、需要的软件
1、虚拟机管理软件:VMware
2、系统:CentOS 7
3、ssh软件:FileZilla Client
5、Jdk版本:jdk8
6、scala:scala-2.12.11.tgz
7、三节点,已经安装好master和s1和s2虚拟机,如果没有安装,可以到我的上一篇hadoop安装看看
二、安装步骤(一定是要配置好三节点的,这个是前提,或者你拥有hadoop环境也行。跟着我的一套搭下来,没问题的。我这也是standalone配过的。当然我的hadoop版本比较低,现在高版本的flink已经不内置了对应的hadoop包,具体安装步骤就是下载你的hadoop,然后下载flink-scala,然后在flink官网下载hadoop对应的一个额外配置文件,下载以后用idea打开,修改城你的hadoop版本,然后打包成jar,传到虚拟机放到flink的lib目录下。具体看这个吧
https://haokan.baidu.com/v?pd=wisenatural&vid=9730347504551466498)
1、下载对应的安装包,我的是scala2.12.11,hadoop2.7,对应flink1.7版本的,记得下载尾缀为tgz的,下载好以后用FileZilla Client传输到虚拟机
https://archive.apache.org/dist/flink/flink-1.7.2/

2、下载以后解压
tar -zxvf flink-1.7.2-bin-hadoop27-scala_2.11.tgz
3、解压以后配置一下环境变量
vim /etc/profile
在文件末尾直接变量
HADOOP_CLASSPATH='${HADOOP_HOME}/bin/hadoop classpath'
保存:wq
使环境变量生效:source /etc/profile
4、有时候虚拟机内存小,会有问题。yarn会检查虚拟机内存和你运行命令时设置的运行内存,会有问题报错。
所以配置一下yarn-site.xm
cd cd hadoop-2.7.7/etc/hadoop
vim yarn-site.xml
在configuration里追加
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
5、先启动hadoop集群,配置了环境变量,所以在root根目录启动就行,如果不行,进入hadoop那个解压缩的文件,再执行
start-all.sh
jps,检查一下
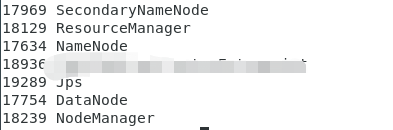
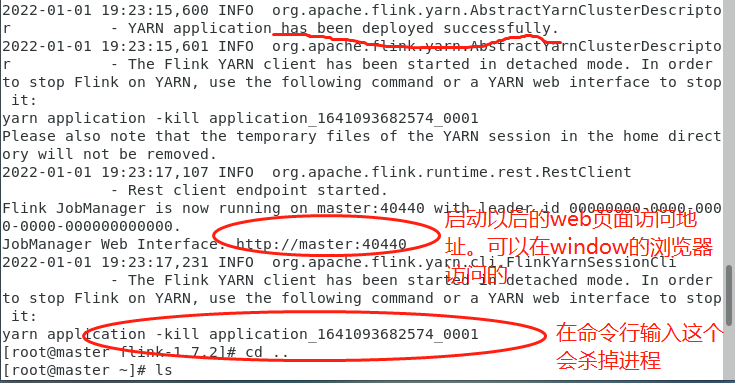
6、然后进入到你解压的flink文件输入启动命令(三台虚拟机都要开着)
bin/yarn-session.sh -n 2 -jm 2048m -tm 1024m -d
-n 2 是俩结点
-jm 是jobManager的内存大小,也就是我的master结点内存
-tm 是taskManager的内存大小,也就是我的slaves结点的内存
-d 是后台启动的意思
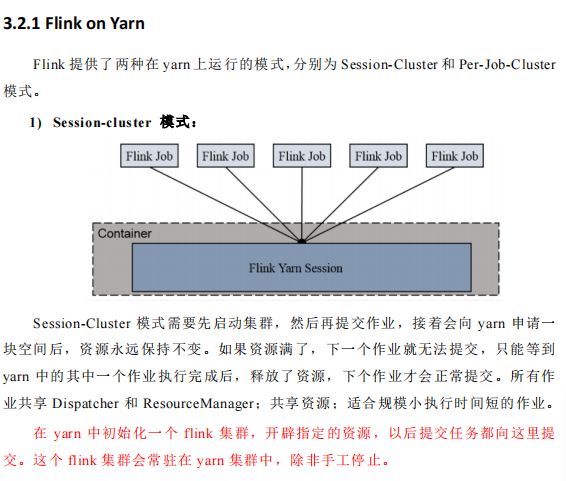
三、第二种启动模式
输入命令
bin/flink rum -m yarn-cluster -yjm 1024 -ytm 1024 ./examples/batch/worldCount.jar

 浙公网安备 33010602011771号
浙公网安备 33010602011771号