
一、需要的软件
1、虚拟机管理软件:VMware
2、系统:CentOS 7
3、ssh软件:FileZilla Client
5、Jdk版本:jdk8
6、scala:scala-2.12.11.tgz
7、三节点,已经安装好master和s1和s2虚拟机,如果没有安装,可以到我的上一篇hadoop安装看看
二、scala安装
首先到官网下载scala的tar压缩包,然后通过FileZilla Client传入到虚拟机master的root目录下,下载网址为
https://www.scala-lang.org/download/all.html

我是装在root目录下的
解压:tar -zxvf scala-2.12.11.tgz
重命名:mv scala-2.12.11 scala
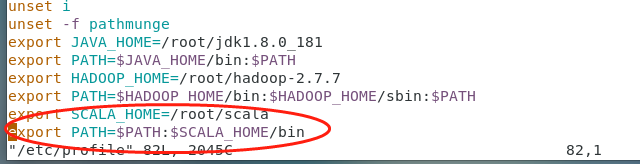
配置环境变量:vim /etc/profile
在profile中末尾追加输入:
export SCALA_HOME=/root/scala
export PATH=$PATH:$SCALA_HOME/bin
esc,:wq保存
使环境变量生效:source /etc/profile
查看安装是否成功
输入:scala -version

三、安装flink
下载flink
https://www.apache.org/dyn/closer.lua/flink/flink-1.13.5/flink-1.13.5-bin-scala_2.12.tgz
拷贝到虚拟机里,我装在root目录下
解压:tar -zxvf flink-1.13.5-bin-scala_2.12.tgz
重命名: mv mv flink-1.13.5 flink
进入flink目录:cd flink
进入conf文件:cd conf/
修改配置文件:vim flink-conf.yaml
找到jobmanager:/jobmanager(搜索的意思,不要再insert模式下),修改为你的主机名,我上个文章已经配置过了,叫master
修改masters:vim masters,修改为master
修改works:vim workers,修改为s1 s2,
退回到flink安装目录下,复制给另外两个机器:
scp -r flink root@s1:~/
scp -r flink root@s2:~/
进入另外两个机器,查看有没有传送过来:如下图,我检查了
启动集群,进入flink目录:cd flink
输入命令,不要进入bin再启动,因为他这个sh文件不一般:bin/start-cluster.sh
因为在start-cluster.sh中指定的解析器是/usr/bin/env bash,而不是我们常见的shell解析器,所以会出错,一般情况,只要不是shell解析器,都采用“./脚本名”的方式运行脚本
输入jps:jps





 浙公网安备 33010602011771号
浙公网安备 33010602011771号