


一、selenium模块
之前,我们爬虫是模拟浏览器,但始终不是用的浏览器,但今天我们要说的是另一种爬虫方式,这次不是模拟浏览器,而是用程序去控制浏览器进行一些列操作,也就是selenium。selenium是python的一个第三方库,对外提供的接口可以操控浏览器,比如说输入、点击,跳转,下拉等动作。
在使用selenium模块之前要做两件事,一是安装selenium模块,可以用终端用pip,也可以在pycharm里的setting安装;二是我们需要下载一款浏览器驱动程序,下载的驱动程序要和浏览器的版本一致
二、用谷歌驱动程序来展示selenium模块的用法
1,下载谷歌浏览器的驱动程序
下载地址:http://chromedriver.storage.googleapis.com/index.html,下载驱动程序要和浏览器版本统一,可以在这个网址看该选择哪个版本,直接在网上搜索谷歌浏览器版本与驱动程序版本映射表就可以了。如我的谷歌浏览器是最新的72版。
网上的映射图:
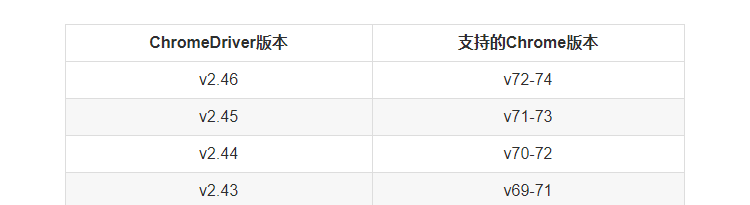
所以我选择一个v2.45的驱动程序,去驱动程序下载页面选择v2.45,点击,如果是windows系统的,选择32位是可以用(只有32位供你选择)
2,简单示例


from selenium import webdriver
#首先要实例化一个对象,参数为驱动程序所在位置的路径
driver=webdriver.Chrome(r'E:\Google\Chrome\Application\chromedriver.exe')
driver.get('https://www.baidu.com/')
#给input标签赋值
search=input('请输入想要下载的类型,如美女')
#这是通过id属性找到搜索框标签,并且给他赋值
driver.find_element_by_id('kw').send_keys(search)
#通过id属性找到‘百度一下’点击标签,可点击事件触发操作
driver.find_element_by_id('su').click()
driver.close()#关闭驱动程序
3,找到标签
find_element_by_id() #通过id属性
find_element_by_name() #通过name属性
find_element_by_class_name() #通过class名字
find_element_by_tag_name() #通过标签名字
find_element_by_link_text() #通过链接标签的文本
find_element_by_partial_link_text() #通过链接标签的部分文本
find_element_by_xpath() #通过xpath
find_element_by_css_selector() #通过css选择器
注意:
1,find_element_by_找到的第一个,find_elements_by_找到的是所有
2,find_element(By.ID,id)和find_element_by_id(id)是一样的
4,找到的标签可用方法
#这是找到一个搜索框的标签
input=driver.find_element_by_id('ww')
#给这个搜索框输入值 input.send_keys('myname')
#把搜索框的值给清空 input.clear()
#这是找到一个按钮标签 button=driver.find_element_by_id('cc')
#触发点击事件 button.click()
5,动作链
上面的动作只是输入啊,点击等单个动作的实现,其实还有一些连续的动作,比如说鼠标拖动等,这就是一个动作链。
from selenium import webdriver
from selenium.webdriver import ActionChains
import time
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
#这是特例,这个页面相当于有两层HTML,这是进入iframeResult的HTML
browser.switch_to.frame('iframeResult')
#找到source标签
source = browser.find_element_by_css_selector('#draggable')
#找到target标签
target = browser.find_element_by_css_selector('#droppable')
#实例化一个action对象
actions = ActionChains(browser)
#点击source标签,然后不放开
actions.click_and_hold(source).perform()
#把刚才点击不放的标签移动到target标签
actions.move_to_element(target).perform()
#然后再把source标签往x轴方向移动50
actions.move_by_offset(xoffset=50,yoffset=0).perform()
#这是释放动作链,也就是松开鼠标
actions.release()
6,执行js代码
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.jd.com/')
#这是滚动页面的滚动条,这个功能是很好用的,我们知道有很多页面刚进入时,是不会加载完全,当你把滚动条不断往下滚动,又会添加更多的信息,
对于爬取这种页面,如果不用这个方法,得到页面是不完全的
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("123")')
7,获取标签的信息
7.1 拿到页面的源代码
#直接用驱动对象'.page_source'就可以
driver.page_source
7.2 直接拿标签的属性
from selenium import webdriver
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.support import expected_conditions as EC
tag=browser.find_element(By.CSS_SELECTOR,'#cc-lm-tcgShowImgContainer img')
#获取标签属性,
print(tag.get_attribute('src'))
#获取标签ID,位置,名称,大小(了解)
print(tag.id)
print(tag.location)
print(tag.tag_name)
print(tag.size)
8,延时等待
页面加载是分顺序的,很多时候当网速差一点的情况下,就会明显感觉到,先看到是一些html标签,但什么css和js都没有,图片等加载会慢点。所以当我们发送请求后直接拿page_source,不一定能拿到加载完毕的页面,也就拿到源码可能不全,为了确保能拿到完整的源码,有两种等待的方法:一是隐式等待,二是显示等待
8.1 隐式等待
就是等页面加载完毕后在开始查找,
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
browser=webdriver.Chrome()
#隐式等待:在查找所有元素时,如果尚未被加载,则等10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
input_tag=browser.find_element_by_id('kw')
input_tag.send_keys('美女')
input_tag.send_keys(Keys.ENTER)
contents=browser.find_element_by_id('content_left') #没有等待环节而直接查找,找不到则会报错
print(contents)
browser.close()
8.2 显式等待
只等要查找的标签加载完毕
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
input_tag=browser.find_element_by_id('kw')
input_tag.send_keys('美女')
input_tag.send_keys(Keys.ENTER)
#显式等待:显式地等待某个元素被加载
wait=WebDriverWait(browser,10)
wait.until(EC.presence_of_element_located((By.ID,'content_left')))
contents=browser.find_element(By.CSS_SELECTOR,'#content_left')
print(contents)
browser.close()
9,cookie
我们知道对于浏览器来说cookie是很重要的,很多情况下服务器都是要对cookie进行验证的
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
#获取cookie
browser.get_cookies()
#设置cookie
browser.add_cookie({'name': 'name', 'domain': 'www.zhihu.com', 'value': 'germey'})
#删除cookie
browser.delete_all_cookies()
10,异常处理
from selenium import webdriver
from selenium.common.exceptions import TimeoutException,NoSuchElementException,NoSuchFrameException
try:
browser=webdriver.Chrome()
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
browser.switch_to.frame('iframssseResult')
except TimeoutException as e:
print(e)
except NoSuchFrameException as e:
print(e)
finally:
browser.close()
在这个示例中,我们可以把谷歌浏览器换成火狐等各种浏览器,用法是一样的
三、phantomJS无界面浏览器
1,phantomJS介绍
上面用的谷歌浏览器是很好用的,而且可视化界面让学习者很好的了解整个过程,但其实在应用中,我们并不需要看到可视化界面,于是就有了phantomJS,它是一款无界面的浏览器,整个实现流程和谷歌一样的,虽然说没有界面,但其有截图功能,用save_screenshot函数
from selenium import webdriver
import time
# phantomjs路径
path = r'PhantomJS驱动路径'
browser = webdriver.PhantomJS(path)
# 打开百度
url = 'http://www.baidu.com/'
browser.get(url)
browser.save_screenshot(r'baidu.png')
# 查找input输入框
my_input = browser.find_element_by_id('kw')
# 往框里面写文字
my_input.send_keys('美女')#截屏
browser.save_screenshot(r'meinv.png')
# 查找搜索按钮
button = browser.find_elements_by_class_name('s_btn')[0]
button.click()
browser.save_screenshot(r'show.png')
browser.quit()
用selenium和phantomJS就可以很友好的实现有些网页的爬取了,比如说需要把滚动条拉倒最下面才会有完整的页面。
2,爬取需要下拉动作的网页新闻
from selenium import webdriver
from time import sleep
import time
if __name__ == '__main__':
url = 'https://news.163.com/'
# 发起请求前,可以让url表示的页面动态加载出更多的数据
path = r'phantomjs-2.1.1-windows\bin\phantomjs.exe'
# 创建无界面的浏览器对象
bro = webdriver.PhantomJS(path)
# 发起url请求
bro.get(url)# 截图
bro.save_screenshot('1.png')
# 执行js代码(让滚动条向下偏移n个像素(作用:动态加载了更多的电影信息))
js = 'window.scrollTo(0,document.body.scrollHeight)'
bro.execute_script(js) # 该函数可以执行一组字符串形式的js代码
bro.save_screenshot('2.png') # 使用爬虫程序爬去当前url中的内容
html_source = bro.page_source # 该属性可以获取当前浏览器的当前页的源码(html)
with open('./source.html', 'w', encoding='utf-8') as fp:
fp.write(html_source)
bro.quit()
四、谷歌无头浏览器
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
# 创建一个参数对象,用来控制chrome以无界面模式打开
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 驱动路径
path = r'chromedriver.exe'
# 创建浏览器对象
browser = webdriver.Chrome(executable_path=path, chrome_options=chrome_options)
# 发送请求
url = 'http://www.baidu.com/'
browser.get(url)
browser.save_screenshot('baidu.png')
browser.quit()
本篇博客主要借鉴于两位大佬,在此分享大佬的博客
https://www.cnblogs.com/bobo-zhang/p/9685362.html
https://www.cnblogs.com/pyedu/p/10306662.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
2022-08-10 有道翻译爬虫
2021-08-10 核心期刊
2018-08-10 文档型数据库列一般都是弱项
2018-08-10 无法打开物理文件 XXX.mdf"。操作系统错误 5:"5(拒绝访问。)"的解决办法
2018-08-10 Solr学习总结(六)solr的函数查询Function Queries
2018-08-10 学习MongoDB 七: MongoDB索引(索引基本操作)(一)
2018-08-10 学习MongoDB 八: MongoDB索引(索引限制条件)(二)