


前面的文章“谷歌验证码ReCAPTCHA 的模拟点击破解方案来了!”我们介绍过 ReCaptcha 的模拟点击破解教程,但除了 ReCaptcha,还有另外和 ReCapacha 验证流程很相似的验证码,叫做 HCaptcha。
ReCaptcha 是谷歌家的,因为某些原因,咱们国内是无法使用 ReCaptcha 的,所以有时候 HCaptcha 也成了一些国际性网站的比较好的选择。
那今天我们就来了解下 HCaptcha 和它的模拟点击破解流程。
HCaptcha
我们首先看看 HCaptcha 的验证交互流程,其 Demo 网站为 https://democaptcha.com/demo-form-eng/hcaptcha.html,打开之后,我们可以看到如下的验证码入口页面:
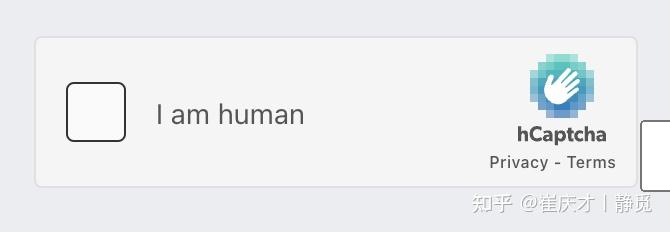
看起来入口和 ReCaptcha 很相似的对吧,其实验证流程也是很类似的。
当我们点击复选框时,验证码会先通过其风险分析引擎判断当前用户的风险,如果是低风险用户,便可以直接通过,反之,验证码会弹出对话框,让我们回答对话框中的问题,类似如下:
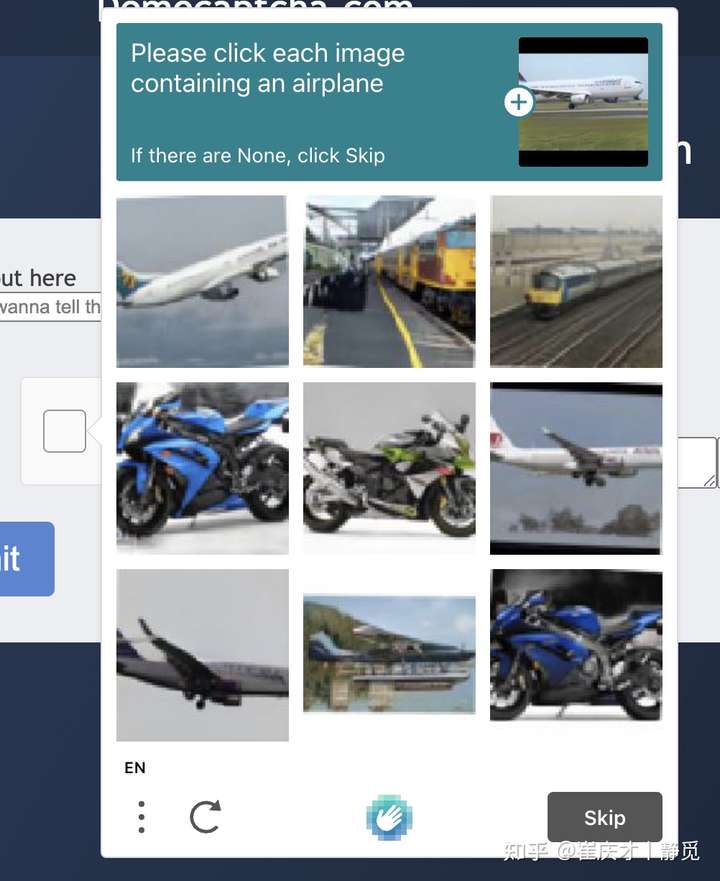
这时候我们看到 HCaptcha验证码会给我们一个问题,比如上图的问题是「请点击每张包含飞机的图片」,我们需要从下面的九张图中选择出含有飞机的图片,如果九张图片中,没有飞机,则点击「跳过 / Skip」按钮,如果有,则将所有带有飞机的图片都选择上,跳过按钮会变成「检查 / Verify」按钮,验证通过之后我们就可以看到如下的验证成功的效果了:

是不是整体流程和 ReCaptcha 还是还是非常相近的?
但其实这个比 ReCaptcha 简单一些,它的验证码图片每次一定是 3x3 的,没有 4x4 的,而且点击一个图之后不会再出现一个新的小图让我们二次选择,所以其破解思路也相对简单一些。
如何破解
整个流程其实我们稍微梳理下,就知道整体的的破解思路了,有这么两个关键点:
- 第一就是把上面的文字内容找出来,以便于我们知道要点击的内容是什么。
- 第二就是我们要知道哪些目标图片和上面的文字是匹配的,找到了依次模拟点击就好了。
听起来似乎很简单的对吧,但第二点是一个难点,我们咋知道哪些图片和文字匹配的呢?这就是一个难题。
前面 ReCaptcha 的破解过程我们了解过了使用 YesCaptcha 来进行图片的识别,除了 ReCaptcha,YesCaptcha 其实也支持 HCaptcha 的验证码识别,利用 YesCaptcha 我们也能轻松知道哪些图片和输入内容是匹配的。
下面让们来试试看。
YesCaptcha
在使用之前我们需要先注册下这个网站,网站地址是 https://yescaptcha.com/i/CnZPBu ,注册个账号之后大家可以在后台获取一个账户密钥,也就是 ClientKey,保存备用。
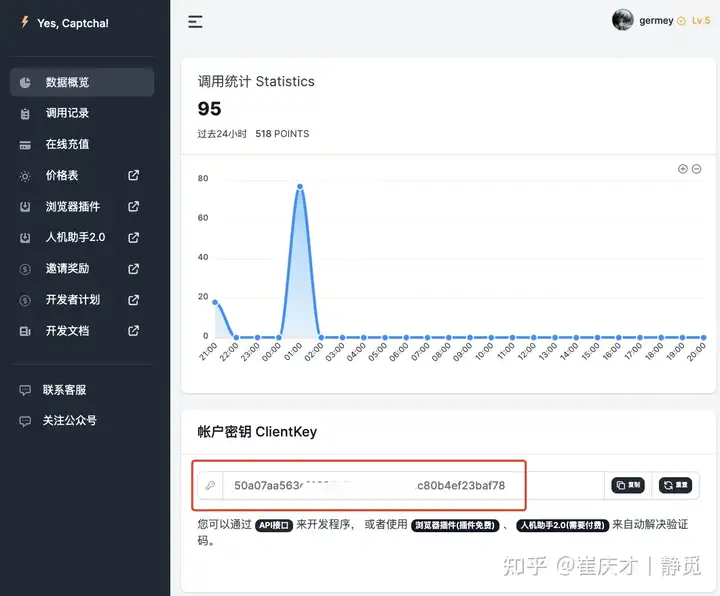
OK,然后我们可以查看下这里的官方文档:https://yescaptcha.atlassian.net/wiki/spaces/YESCAPTCHA/pages/24543233/HCaptchaClassification+Hcaptcha,这里介绍介绍了一个 API,大致内容是这样的。
首先有一个创建任务的 API,API 地址为 https://api.yescaptcha.com/createTask,然后看下请求参数:

这里我们需要传入这么几个参数:
- type:内容就是
- queries:是验证码对应的 Base64 编码,这里直接转成一个列表就可以
- question:对应的问题 ID,也就是识别目标的代号,这里其实就是问题整句的内容
- corrdinate:一个返回结果的控制开关,默认会返回每张图片识别的 true / false 结果,也就是第 x 张图片是否和图片匹配,如果加上该参数,那么 API 就会返回对应匹配图片的索引。
比如这里我们可以 POST 这样的一个内容给服务器,结构如下:
{
"clientKey": "cc9c18d3e263515c2c072b36a7125eecc078618f",
"task": {
"type": "HCaptchaClassification",
"queries": [
"/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8Uw...",
"/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8Uw...",
...
"/9j/4AAQSkZJRgABAQAAAQABAAD/2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8Uw...",
],
"question": "请单击每个包含卡车的图像。" // 直接上传问题整句
}
}然后服务器就会返回类似这样的响应:
{
"errorId": 0,
"errorCode": "",
"status": "ready",
"solution": {
"objects": [true, false, false, true, true, false, true, true] // 返回图片是否为目标,
"labels": ["truck", "boat", "boat", "truck", "truck", "airplane-right", "truck", "truck"] // 返回图片对应的标签
},
"taskId": "5aa8be0c-94a5-11ec-80d7-00163f00a53c""
}OK,我们可以看到,返回结果的 solution 字段中的 objects 字段就包含了一串 true 和 false 的列表,这就代表了每张图片是否和目标匹配。
知道了这个结果之后,我们只需要将返回结果为 true 的图片进行模拟点击就好了。
代码基础实现
行,那有了基本思路之后,那我们就开始用 Python 实现下整个流程吧,这里我们就拿 https://democaptcha.com/demo-form-eng/hcaptcha.html 这个网站作为样例来讲解下整个识别和模拟点击过程。
识别封装
首先我们对上面的任务 API 实现一下封装,来先写一个类:
from loguru import logger
from app.settings import CAPTCHA_RESOLVER_API_KEY, CAPTCHA_RESOLVER_API_URL
import requests
class CaptchaResolver(object):
def __init__(self, api_url=CAPTCHA_RESOLVER_API_URL, api_key=CAPTCHA_RESOLVER_API_KEY):
self.api_url = api_url
self.api_key = api_key
def create_task(self, queries, question):
logger.debug(f'start to recognize image for question {question}')
data = {
"clientKey": self.api_key,
"task": {
"type": "HCaptchaClassification",
"queries": queries,
"question": question
}
}
try:
response = requests.post(self.api_url, json=data)
result = response.json()
logger.debug(f'captcha recogize result {result}')
return result
except requests.RequestException:
logger.exception(
'error occurred while recognizing captcha', exc_info=True)
OK,这里我们就先定义了一个类 CaptchaResolver,然后主要接收两个参数,一个就是 api_url,这个对应的就是 https://api.yescaptcha.com/createTask 这个 API 地址,然后还有一个参数是 api_key,这个就是前文介绍的那个 ClientKey。
接着我们定义了一个 create_task 方法,接收两个参数,第一个参数 queries 就是每张验证码图片对应的 Base64 编码,第二个参数 question 就是要识别的问题整句,这里就是将整个请求用 requests 模拟实现了,最后返回对应的 JSON 内容的响应结果就好了。
基础框架
OK,那么接下来我们来用 Selenium 来模拟打开这个实例网站,然后模拟点选来触发验证码,接着识别验证码就好了。
首先写一个大致框架:
import time
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.remote.webelement import WebElement
from selenium.webdriver.common.action_chains import ActionChains
from app.captcha_resolver import CaptchaResolver
class Solution(object):
def __init__(self, url):
self.browser = webdriver.Chrome()
self.browser.get(url)
self.wait = WebDriverWait(self.browser, 10)
self.captcha_resolver = CaptchaResolver()
def __del__(self):
time.sleep(10)
self.browser.close()这里我们先在构造方法里面初始化了一个 Chrome 浏览器操作对象,然后调用对应的 get 方法打开实例网站,接着声明了一个 WebDriverWait 对象和 CaptchaResolver 对象,以分别应对节点查找和验证码识别操作,留作备用。
iframe 切换支持
接着,下一步我们就该来模拟点击验证码的入口,来触发验证码了对吧。
通过观察我们发现这个验证码和 ReCaptcha 非常类似,其入口其实是在 iframe 里面加载的,对应的 iframe 是这样的:
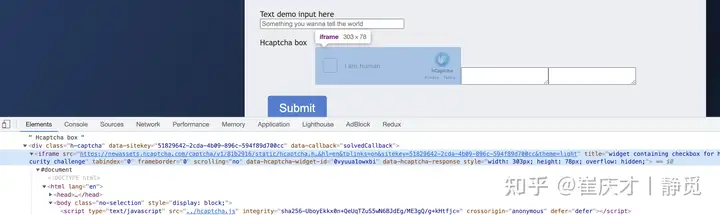
另外弹出的验证码图片又在另外一个 iframe 里面,如图所示:
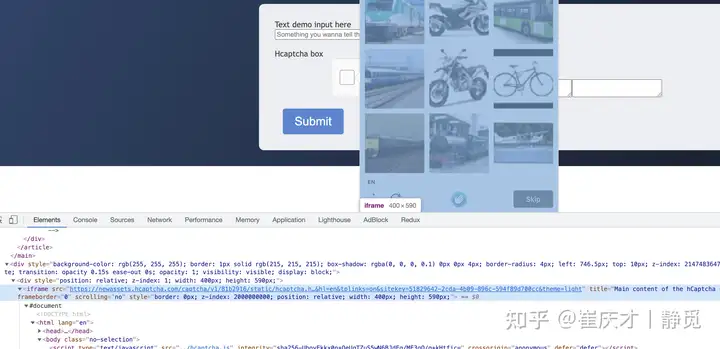
Selenium 查找节点是需要切换到对应的 iframe 里面才行的,不然是没法查到对应的节点,也就没法模拟点击什么的了。
所以这里我们定义几个工具方法,分别能够支持切换到入口对应的 iframe 和验证码本身对应的 iframe,代码如下:
def get_captcha_entry_iframe(self) -> WebElement:
self.browser.switch_to.default_content()
captcha_entry_iframe = self.browser.find_element_by_css_selector(
'.h-captcha > iframe')
return captcha_entry_iframe
def switch_to_captcha_entry_iframe(self) -> None:
captcha_entry_iframe: WebElement = self.get_captcha_entry_iframe()
self.browser.switch_to.frame(captcha_entry_iframe)
def get_captcha_content_iframe(self) -> WebElement:
self.browser.switch_to.default_content()
captcha_content_iframe = self.browser.find_element_by_xpath(
'//iframe[contains(@title, "Main content")]')
return captcha_content_iframe
def switch_to_captcha_content_iframe(self) -> None:
captcha_content_iframe: WebElement = self.get_captcha_content_iframe()
self.browser.switch_to.frame(captcha_content_iframe)
这样的话,我们只需要调用 switch_to_captcha_content_iframe 就能查找验证码图片里面的内容,调用 switch_to_captcha_entry_iframe 就能查找验证码入口里面的内容。
触发验证码
OK,那么接下来的一步就是来模拟点击验证码的入口,然后把验证码触发出来了对吧,就是模拟点击这里:
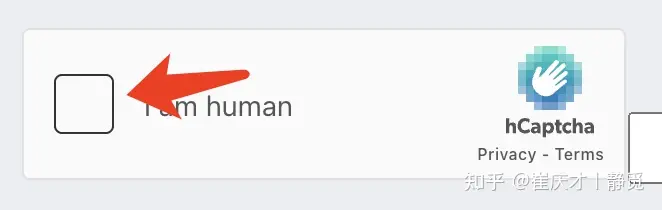
实现很简单,代码如下:
def trigger_captcha(self) -> None:
self.switch_to_captcha_entry_iframe()
captcha_entry = self.wait.until(EC.presence_of_element_located(
(By.CSS_SELECTOR, '#anchor #checkbox')))
captcha_entry.click()
time.sleep(2)
self.switch_to_captcha_content_iframe()
captcha_element: WebElement = self.get_captcha_element()
if captcha_element.is_displayed:
logger.debug('trigged captcha successfully')这里首先我们首先调用 switch_to_captcha_entry_iframe 进行了 iframe 的切换,然后找到那个入口框对应的节点,然后点击一下。
点击完了之后我们再调用 switch_to_captcha_content_iframe 切换到验证码本身对应的 iframe 里面,查找验证码本身对应的节点是否加载出来了,如果加载出来了,那么就证明触发成功了。
找出识别目标
OK,那么现在验证码可能就长这样子了:
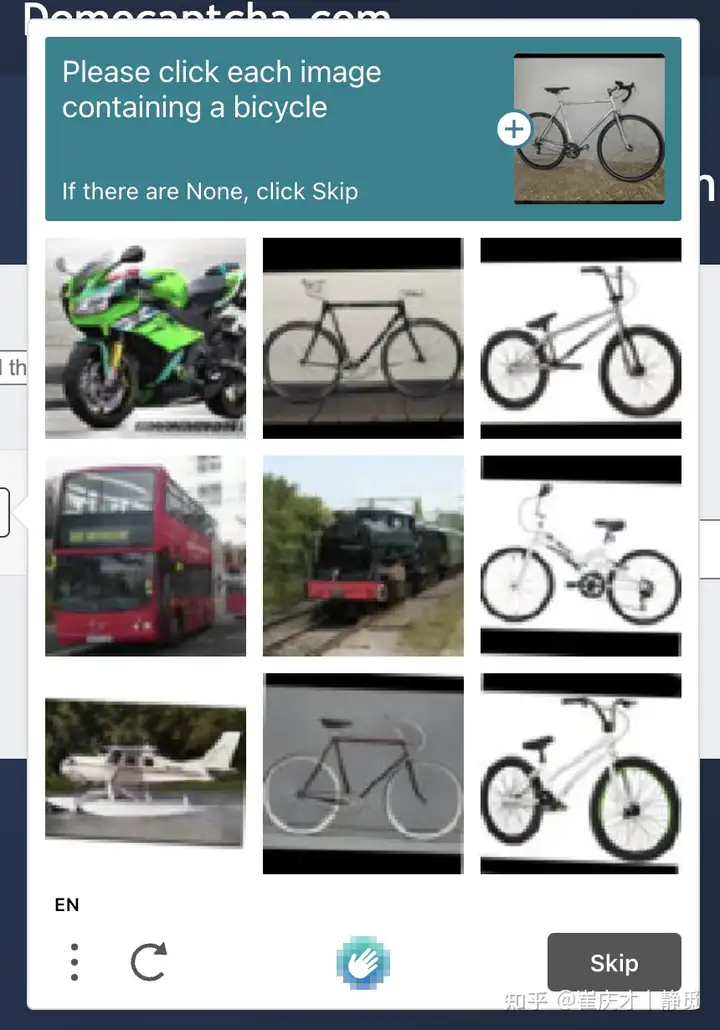
那接下来我们要做的就是两件事了,一件事就是把匹配目标,也就是问题本身找出来,第二件事就是把每张验证码保存下来,然后转成 Base64 编码。
好,那么怎么查找问题呢呢?用 Selenium 常规的节点搜索就好了:
def get_captcha_target_text(self) -> WebElement:
captcha_target_name_element: WebElement = self.wait.until(EC.presence_of_element_located(
(By.CSS_SELECTOR, '.prompt-text')))
return captcha_target_name_element.text
通过调用这个方法,我们就能得到上图中完整的问题文本了。
验证码识别
接下来,我们就需要把每张图片进行下载并转成 Base64 编码了,我们观察下它的 HTML 结构:
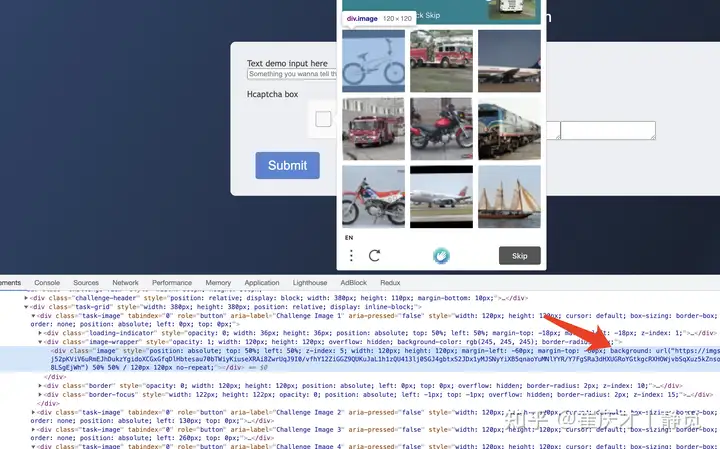
我们可以看到,每个验证码其实都对应了一个 .task-image 的节点,然后里面有个 .image-wrapper 的节点,在里面有一个 .image 的节点,那图片怎么呈现的呢?这里它是设置了一个 style CSS 样式,通过 CSS 的 backgroud 来设置了验证码图片的地址。
所以,我们要想提取验证码图片也比较容易了,我们只需要找出 .image 节点的 style 属性的内容,然后提取其中的 url 就好了。
得到 URL 之后,转下 Base64 编码,利用 captcha_resolver 就可以对内容进行识别了。
所以代码可以写为如下内容:
def verify_captcha(self):
# get target text
self.captcha_target_text = self.get_captcha_target_text()
logger.debug(
f'captcha_target_text {self.captcha_target_text}'
)
# extract all images
single_captcha_elements = self.wait.until(EC.visibility_of_all_elements_located(
(By.CSS_SELECTOR, '.task-image .image-wrapper .image')))
resized_single_captcha_base64_strings = []
for i, single_captcha_element in enumerate(single_captcha_elements):
single_captcha_element_style = single_captcha_element.get_attribute(
'style')
pattern = re.compile('url\("(https.*?)"\)')
match_result = re.search(pattern, single_captcha_element_style)
single_captcha_element_url = match_result.group(
1) if match_result else None
logger.debug(
f'single_captcha_element_url {single_captcha_element_url}')
with open(CAPTCHA_SINGLE_IMAGE_FILE_PATH % (i,), 'wb') as f:
f.write(requests.get(single_captcha_element_url).content)
resized_single_captcha_base64_string = resize_base64_image(
CAPTCHA_SINGLE_IMAGE_FILE_PATH % (i,), (100, 100))
resized_single_captcha_base64_strings.append(
resized_single_captcha_base64_string)
logger.debug(
f'length of single_captcha_element_urls {len(resized_single_captcha_base64_strings)}')
这里我们提取出来了每张验证码图片的 url,这里是用正则表达式进行批评的,提取出 url 之后,我们然后将其存入了 resized_single_captcha_base64_strings 列表里面。
其中这里的 Base64 编码我们单独定义了一个方法,传入了图片路径和调整大小,然后可以返回编码后的结果,定义如下:
from PIL import Image
import base64
from app.settings import CAPTCHA_RESIZED_IMAGE_FILE_PATH
def resize_base64_image(filename, size):
width, height = size
img = Image.open(filename)
new_img = img.resize((width, height))
new_img.save(CAPTCHA_RESIZED_IMAGE_FILE_PATH)
with open(CAPTCHA_RESIZED_IMAGE_FILE_PATH, "rb") as f:
data = f.read()
encoded_string = base64.b64encode(data)
return encoded_string.decode('utf-8')
图片识别
好,那么现在我们已经可以得到问题内容了,也能得到每张图片对应的 Base64 编码了,我们直接利用 YesCaptcha 进行图像识别就好了,代码调用如下:
# try to verify using API
captcha_recognize_result = self.captcha_resolver.create_task(
resized_single_captcha_base64_strings,
self.captcha_target_text
)
if not captcha_recognize_result:
logger.error('count not get captcha recognize result')
return
recognized_results = captcha_recognize_result.get(
'solution', {}).get('objects')
if not recognized_results:
logger.error('count not get captcha recognized indices')
return
如果运行正常的话,我们可能得到如下的返回结果:
{
"errorId":0,
"errorCode":"",
"status":"ready",
"solution":{
"objects":[
true,
false,
false,
false,
true,
false,
true,
true,
false
],
"labels":[
"boat",
"seaplane",
"bicycle",
"train",
"boat",
"train",
"boat",
"boat",
"bus"
]
},
"taskId":"25fee484-df63-11ec-b02e-c2654b11608a"
}现在我们可以看到 sulution 里面的 objects 字段就包含了 true false 的列表,比如第一个 true 就代表了第一个验证码是和问题匹配的,第二个 false 就代表了第二个验证码图片和问题是不匹配的。那序号和图片又是怎么对应的呢?见下图:

从左到右一行行地数,序号依次递增,比如第一行第一个序号就是 0,那么其结果就是 objects 结果里面的第一个结果,true。
模拟点击
现在我们已经得到 true false 列表了,我们只需要将结果是 true 的序号提取出来,然后对这些验证码小图点击就好了,代码如下:
# click captchas
recognized_indices = [i for i, x in enumerate(recognized_results) if x]
logger.debug(f'recognized_indices {recognized_indices}')
click_targets = self.wait.until(EC.visibility_of_all_elements_located(
(By.CSS_SELECTOR, '.task-image')))
for recognized_index in recognized_indices:
click_target: WebElement = click_targets[recognized_index]
click_target.click()
time.sleep(random())
当然我们也可以通过执行 JavaScript 来对每个节点进行模拟点击,效果是类似的。
这里我们用 for 循环将 true false 列表转成了一个列表,列表的每个元素代表 true 在列表中的位置,其实就是我们的点击目标了。
然后接着我们获取了所有的验证码小图对应的节点,然后依次调用 click 方法进行点击即可。
这样我们就可以实现验证码小图的逐个识别了。
点击验证
好,那么有了上面的逻辑,我们就能完成整个 HCaptcha 的识别和点选了。
最后,我们模拟点击验证按钮就好了:
# after all captcha clicked
verify_button: WebElement = self.get_verify_button()
if verify_button.is_displayed:
verify_button.click()
time.sleep(3)而 verfiy_button 的提取也是用 Selenium 即可:
def get_verify_button(self) -> WebElement:
verify_button = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.button-submit')))
return verify_button校验结果
点击完了之后,我们可以尝试检查网页变化,看看有没有验证成功。
比如验证成功的标志就是出现一个绿色小对勾:
检查方法如下:
def get_is_successful(self):
self.switch_to_captcha_entry_iframe()
anchor: WebElement = self.wait.until(EC.visibility_of_element_located((
By.CSS_SELECTOR, '#anchor #checkbox'
)))
checked = anchor.get_attribute('aria-checked')
logger.debug(f'checked {checked}')
return str(checked) == 'true'这里我们先切换了 iframe,然后检查了对应的 class 是否是符合期望的。
最后如果 get_is_successful 返回结果是 True,那就代表识别成功了,那就整个完成了。
如果返回结果是 False,我们可以进一步递归调用上述逻辑进行二次识别,直到识别成功即可。
# check if succeed
is_succeed = self.get_is_successful()
if is_succeed:
logger.debug('verifed successfully')
else:
self.verify_captcha()运行视频
代码
以上代码可能比较复杂,这里我将代码进行了规整,然后放到 GitHub 上了,大家如有需要可以自取:https://github.com/Python3WebSpider/HCaptchaResolver
注册地址
最后需要说明一点,上面的验证码服务是收费的,每验证一次可能花一定的点数,比如识别一次 3x3 的图要花 10 点数,而充值一块钱就能获得 1000 点数,所以识别一次就一分钱,还是比较便宜的。
转:https://zhuanlan.zhihu.com/p/522241889?utm_id=0


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
2022-08-10 有道翻译爬虫
2021-08-10 核心期刊
2018-08-10 文档型数据库列一般都是弱项
2018-08-10 无法打开物理文件 XXX.mdf"。操作系统错误 5:"5(拒绝访问。)"的解决办法
2018-08-10 Solr学习总结(六)solr的函数查询Function Queries
2018-08-10 学习MongoDB 七: MongoDB索引(索引基本操作)(一)
2018-08-10 学习MongoDB 八: MongoDB索引(索引限制条件)(二)