


简介
有时候,我们天真无邪的使用urllib库或Scrapy下载HTML网页时会发现,我们要提取的网页元素并不在我们下载到的HTML之中,尽管它们在浏览器里看起来唾手可得。
这说明我们想要的元素是在我们的某些操作下通过js事件动态生成的。举个例子,我们在刷QQ空间或者微博评论的时候,一直往下刷,网页越来越长,内容越来越多,就是这个让人又爱又恨的动态加载。
爬取动态页面目前来说有两种方法
- 分析页面请求(这篇介绍这个)
- selenium模拟浏览器行为(霸王硬上弓,以后再说)
言归正传,下面介绍一下通过分析页面请求的方法爬取动态加载页面的思路。中心思想就是找到那个发请求的javascript文件所发的请求。
举两个例子,京东评论和上证股票。
后注:本文的两个例子都是get请求,可以显示的在浏览器中查看效果,如果是post请求,需要我们在程序中构造数据,构造方法可以参考我从前的一篇博文Scrapy定向爬虫教程(六)——分析表单并回帖。
京东评论
这是一个比较简单的例子。
首先我们随便找一个热卖的商品,评论比较多。
就这个吧威刚(ADATA) SU800 256G 3D NAND SATA3固态硬盘。
点进去看看这个页面现在的状况
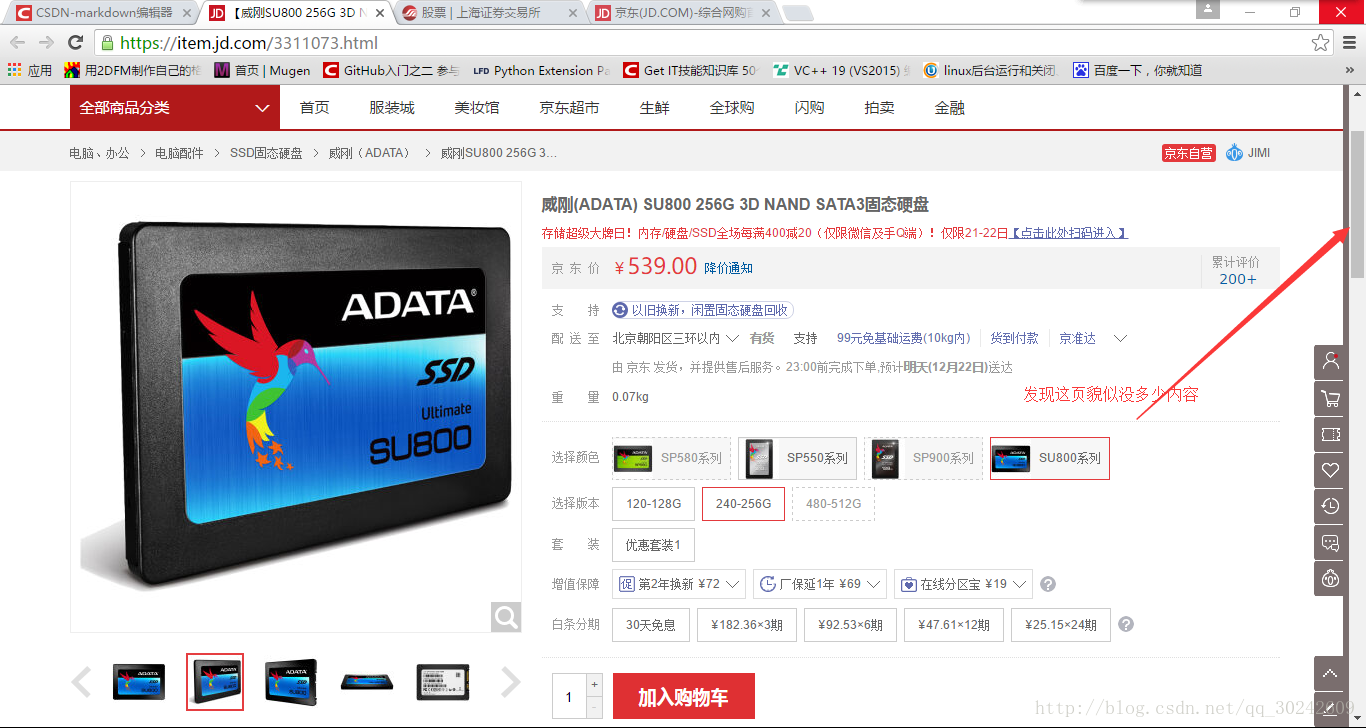
滚动条给的第一印象感觉这页仿佛没多少内容。
键盘F12打开开发者工具,选择Network选项卡,选择JS(3月12日补:除JS选项卡还有可能在XHR选项卡中,当然也可以通过其它抓包工具),如下图
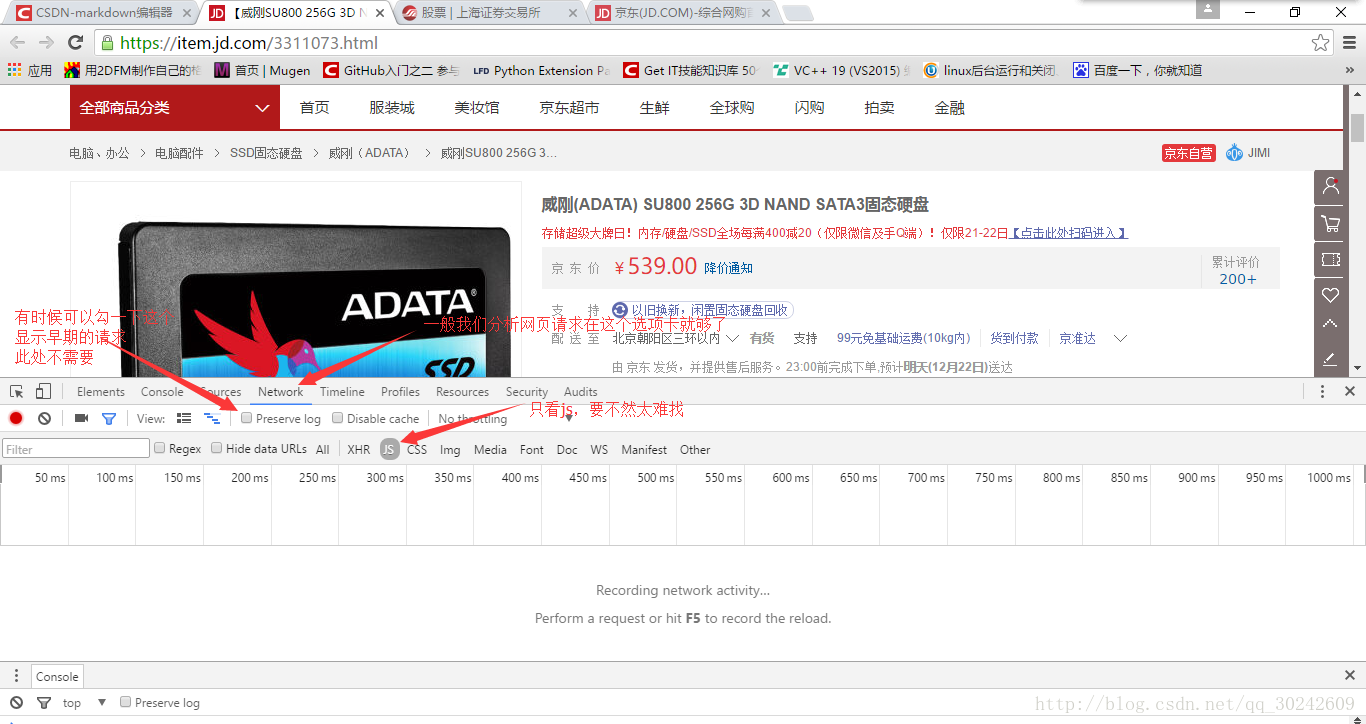
然后,我们来拖动右侧的滚动条,这时就会发现,开发者工具里出现了新的js请求(还挺多的),不过草草翻译一下,很容易就能看出来哪个是取评论的,如下图
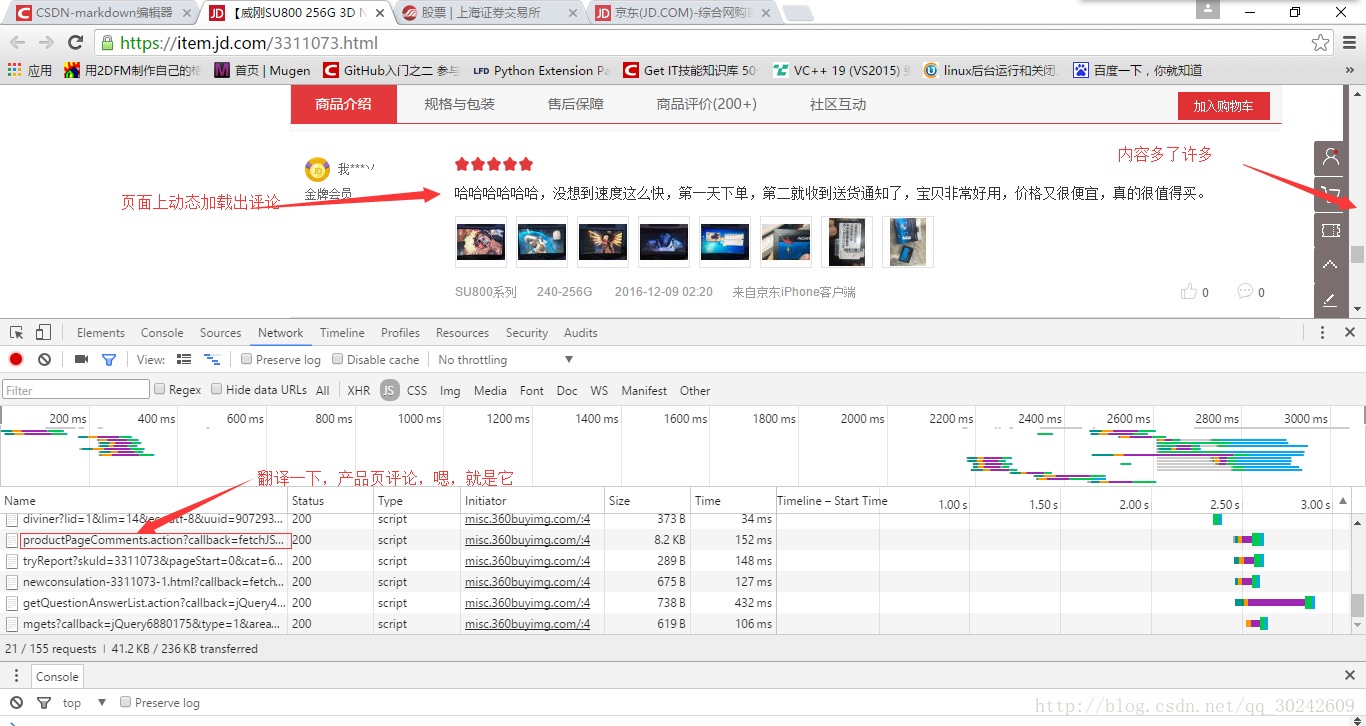
好,复制出js请求的目标url

在浏览器中打开,发现我们想要的数据就在这里,如下图
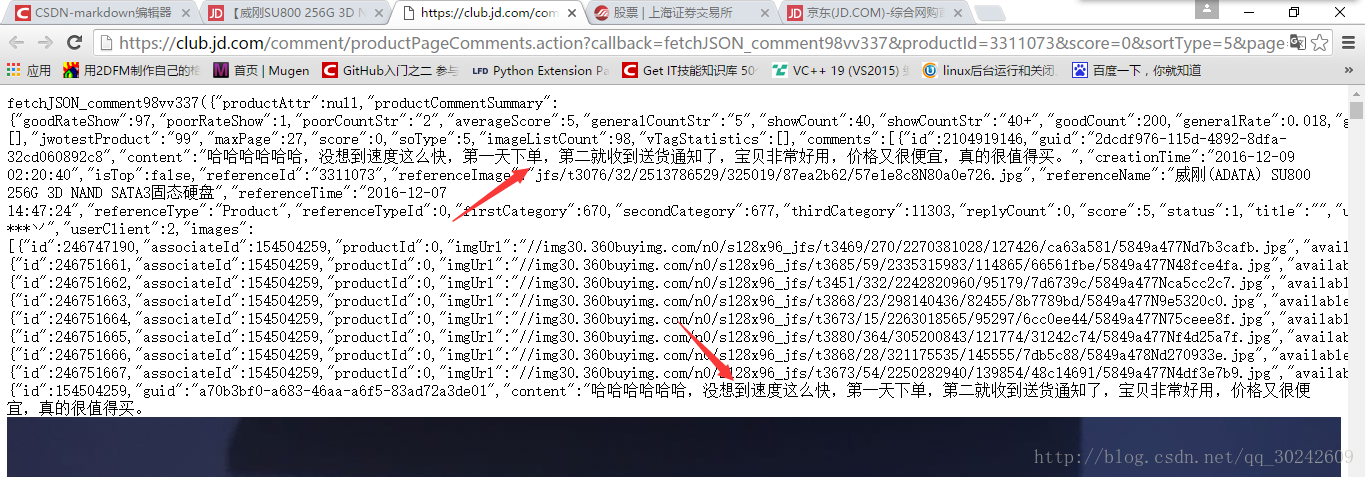
这整个页面是一个json格式的数据,对于京东来说,当用户下拉页面时,触发一个js事件,向服务器发送上面的请求取数据,然后通过一定的js逻辑把取到的这些json数据填充到HTML页面当中。对于我们Spider来说,我们要做的就是把这些json数据整理提取。
在实际应用中,当然我们不可能去每个页面里找出来这个js发起的请求目标地址,所以我们需要分析这个请求地址的规律,一般情况下规律是比较好找的,因为规律太复杂服务方维护也难。那我们就来看一下京东这个请求:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv337&productId=3311073&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0- 1
挺长的一个GET请求,不过参数命名都很规范,产品ID,评论页码什么的,因为我这里只是举个例子,我就不一个一个去研究了~
思路有了,就按照正常的爬虫去写就好了,发请求,得到响应,解析数据,后续处理等等……
上证股票
这是前段时间一位道友问我的一个问题,感觉还是挺有嚼头的,比上例要难。
目标网址:上海证券交易所
目的是把每一页的股票信息都得到,看似很简单,但是通过查看源代码发现,每一页的链接在源代码里是看不到的。如下图
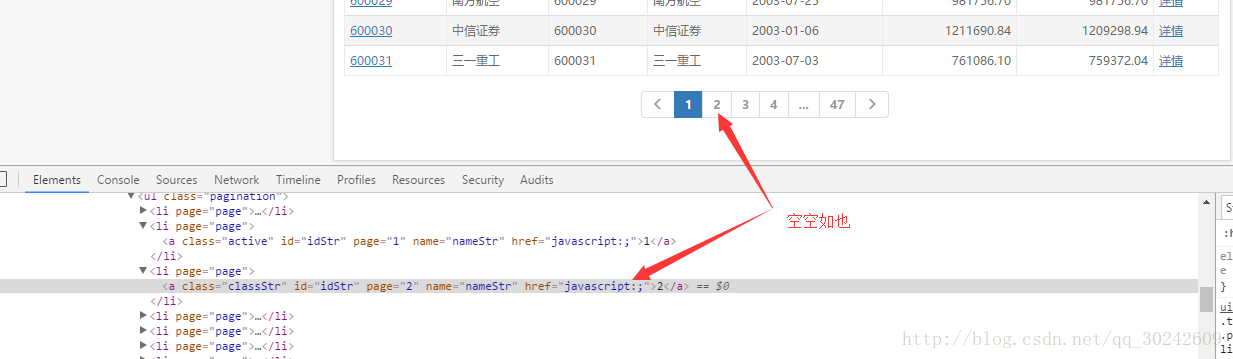
ok,又是js动态加载,在源代码里不显示,不过一定躲不过我们的开发者工具,按照上面京东的思路,切到Network、js选项卡,点击页码,获得请求地址,一切行云流水,如下图
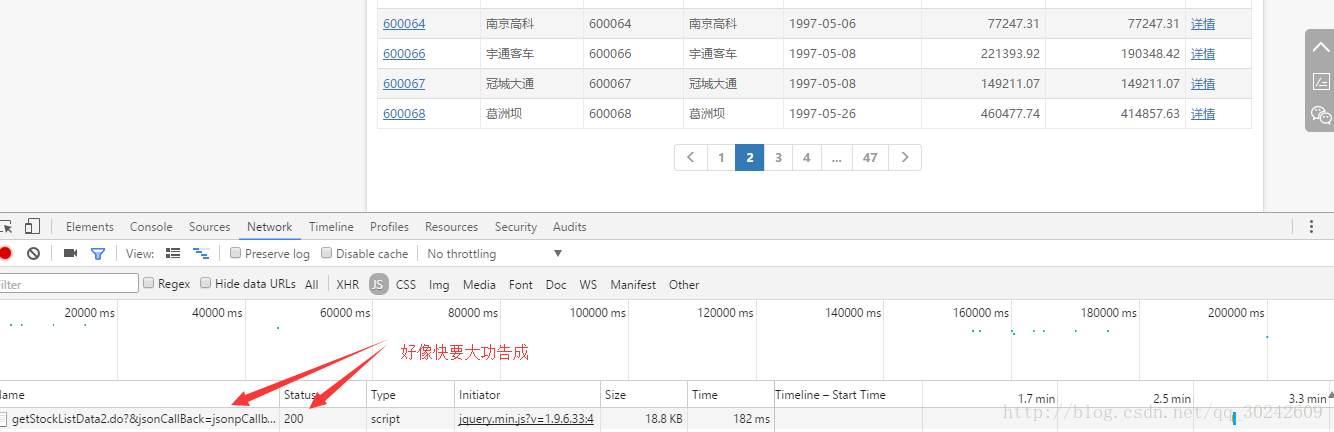
然而,当我们复制出这个url,在浏览器中打开的时候,浏览器呈现的信息却是:

403错误!奇哉怪也!
究其原因,403状态码什么意思呢?意思就是说,本服务器知道你发来这一串url想找啥呢,但是老子就不给你!
怎么办,有办法~
想想看,为什么我们在那个页面上点击第二页第三页的时候能够正常的获取到数据?为什么我们直接请求不行?都是同一个浏览器呀。
问题就在于,浏览器通过上一个页面发起的请求和单独发的请求,头信息(request header)是不同的,比方说cookie、refer这些字段,服务器就通过这些就把我们的请求过滤掉了。
浏览器如此,我们的爬虫也是如此,最后我解决这个问题的方法是给爬虫设定详细的请求头(从我们能请求到的原始页获得),包括cookie,refer等,终于成功的得到了返回的json数据。
这份代码是用python3的urllib写的,我只帮他写了取一页的数据,逻辑他自己去写了。如下,看官不妨试试将头信息去掉~
import urllib.request
Cookie = "PHPStat_First_Time_10000011=1480428327337; PHPStat_Cookie_Global_User_Id=_ck16112922052713449617789740328; PHPStat_Return_Time_10000011=1480428327337; PHPStat_Main_Website_10000011=_ck16112922052713449617789740328%7C10000011%7C%7C%7C; VISITED_COMPANY_CODE=%5B%22600064%22%5D; VISITED_STOCK_CODE=%5B%22600064%22%5D; seecookie=%5B600064%5D%3A%u5357%u4EAC%u9AD8%u79D1; _trs_uv=ke6m_532_iw3ksw7h; VISITED_MENU=%5B%228451%22%2C%229055%22%2C%229062%22%2C%229729%22%2C%228528%22%5D"
url = "http://query.sse.com.cn/security/stock/getStockListData2.do?&jsonCallBack=jsonpCallback41883&isPagination=true&stockCode=&csrcCode=&areaName=&stockType=1&pageHelp.cacheSize=1&pageHelp.beginPage=3&pageHelp.pageSize=25&pageHelp.pageNo=3&pageHelp.endPage=31&_=1480431103024"
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36',
'Cookie': Cookie,
'Connection': 'keep-alive',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Host': 'query.sse.com.cn',
'Referer': 'http://www.sse.com.cn/assortment/stock/list/share/'
}
req = urllib.request.Request(url,None,headers)
response = urllib.request.urlopen(req)
the_page = response.read()
print(the_page.decode("utf8"))结语
还是那句话,通过分析页面请求的方法爬取动态加载页面的思路。中心思想就是找到那个发请求的javascript文件所发的请求。然后利用我们既有的爬虫知识去构造请求就可以了。
临近考试,写作较为匆忙。如果本文有叙述不清或者不正确的地方,还请批评指正。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
2018-07-23 (c#) 销毁资源和释放内存
2018-07-23 C#中 ThreadStart和ParameterizedThreadStart区别
2018-07-23 MongoDB的C#封装类
2018-07-23 mongo DB for C#
2018-07-23 C#操作MongoDB
2018-07-23 关于Mongodb的全面总结
2018-07-23 Mongodb下载、安装、配置与使用