


受新加坡某科研机构委托,需要对国内469所高校,156个学科,25年内在 中的“引文报告”(如下图示例)数据进行采集。检索次数超180万次。
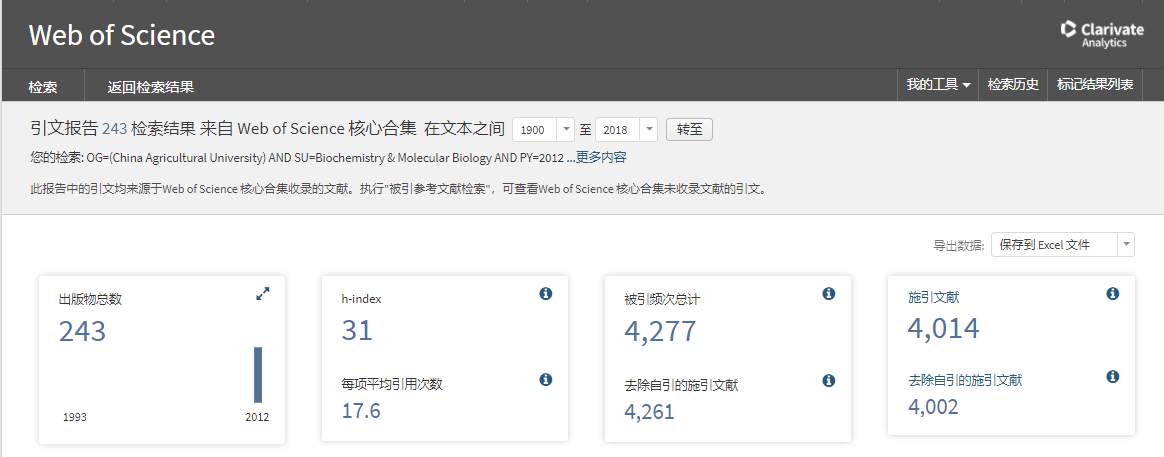
该网站“需要登陆,并且会封账号”,具有很强的典型性,特对本网站的采集经验分享如下:
1. Web of Science必须登陆才能检索,而且同一个账号不能重复登陆,新的登陆会造成同一账号老的会话失效。
2. 同一账号的会话可以多线程使用,不会互相干扰检索结果。
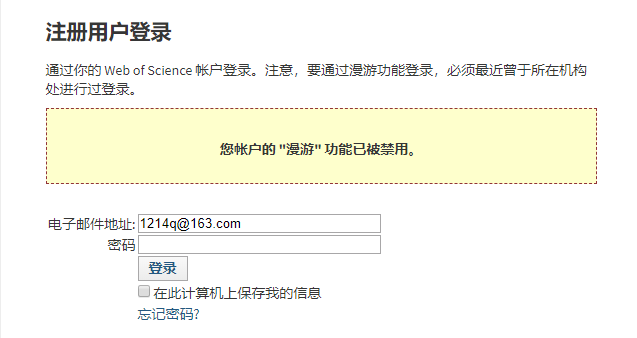
3. 账号可能会被封,被封之后会提示“您帐户的 "漫游" 功能已被禁用”(如下图所示)。这个可能是Web of
Science运维人工干预的,在我们的测试过程中,在相同的访问频率下,有的账号只能搜索一两万次就被封了,而有的却能搜索十几万次。在爬虫中我们加入了自动切换账号的功能,如果检测到账号被封则自动换用下一个账号,不需要人工介入。我们总共进行了超过180次的搜索,总共使用了25个账号。
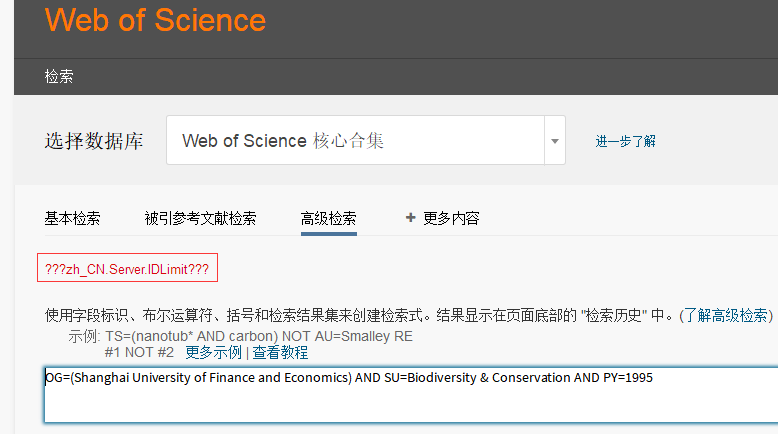
4. 账号每日访问次数有限制,超过之后会提示“Server.IDLimit”之类错误(如下图所示),如果检测到账号被封则自动换用下一个账号,也不需要人工介入。
5. Cookie会不停的变动,每次查询网站都会返回新的Cookie,不能持续的使用老的Cookie(有时效性),否则一段时间后会出现Timeout问题。我们一开始以为是代理的问题,后来经过多次验证是因为Cookie变化了造成的,应该是触发了WAF的防护策略。在我们的爬虫中,如果连续检测到多次出现Timeout问题,爬虫自动重新登陆,即可恢复正常。
6. 每搜索满200次系统会提示“记录本次会话中所有检索的“检索历史” 列表已满”,造成检索失败。所以爬虫中需要每隔200次清空一下搜索结果。
7. 会出现搜索失败的情况,爬虫需要进行重试直至成功。
8. 可以不使用代理IP,我们采集的过程中未发现该系统对IP访问频率有限制。
9. 为了不对系统造成过重负担(Richard曾说过在采集别人网站的时候要心怀感恩),我们爬虫仅使用了5个线程。进行180万搜索,共耗时约20天。
10. 由于搜索需要大量时间,爬虫使用了缓存机制,防止客户修改字段后需要二次下载。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
2019-04-06 solr字段压缩属性compressed新版本已经移除
2019-04-06 solr schema.xml Field属性详解
2012-04-06 企业技术架构图
2012-04-06 关于VerifyRenderingInServerForm方法的思考(转)
2007-04-06 如何自定义上传文件大小限制
2007-04-06 在IE里嵌入播放器