
最近用到了python和request的一些内容,感觉自己掌握的比较零散,所以将内容记录下来,方便查阅。
转自:https://www.cnblogs.com/zhengyao9236/p/11122446.html
1)环境准备:
接口测试的方式有很多,比如可以用工具(jmeter,postman)之类,也可以自己写代码进行接口测试,工具的使用相对来说都比较简单,重点是要搞清楚项目接口的协议是什么,然后有针对性的进行选择,甚至当工具不太适合项目时需要自己进行开发。
在我们项目的初期,我们采用的是jmeter进行接口测试,当时觉得这个工具上手简单,团队成员学习成本低,并且接口测试的脚本稍微调整一下还可以用来做性能测试。
不过随着项目规模、团队人数的不断增长,渐渐的这个工具有适应不了当前项目的需求了,为此我们项目也重新开发了相关接口自动化的平台。但是,但是。。。可能是我让大家中毒太深,现在很多同学一提到接口测试关联到jmeter,为此,我深深感到不安。毕竟jmeter只是个工具,换个项目换个协议你是否还能玩转接口测试呢?session和cookie有什么区别?工具又是怎么实现的呢?
比如session如何保存,接口依赖如何处理,case如何管理及执行顺序,测试数据如何管理等等题,这个过程也有助于我们更加深刻的理解接口测试和http协议。
本文主要采用python语言,python中http协议接口相关的库有urllib,urllib2以及reqeusts库,这其中reqeusts库用来起来最方便,因此我也主要采用requests库来做http协议的接口测试。首先来看下需要哪些环境信息:
一、安装python
mac下自带安装了python,这个不多说了。
二、安装虚拟环境:
我们在一台机器上可以安装多个python版本,为了使每个版本的环境相互不受干扰,可以安装虚拟环境,安装方法如下:
1、安装virtualenv:pip install virtualenv
2、新建名为venv的虚拟环境:virtualenv venv
3、进入新环境:source venv/bin/activate
4、退出:deactivate
三、安装requests库:
>>>pip install requests
ps:用python做http协议的接口测试会用到这个库。
四、http测试工具:
一个使用 Python + Flask 编写的 HTTP 请求和响应服务,该服务主要用于测试 HTTP 库。后续测试我们都基于这个网站。
http://httpbin.org
五、在本地搭建httpbin:
考虑到测试时要不断访问 httpbin 网站,请求过多担心被拉到黑名单,我们自己在本志搭建一套httpbin服务。
1、安装:pip install gunicorn
2、安装:pip install httpbin
3、启动:gunicorn httpbin:app
至此,环境搭建已经完毕,可以开始玩了~
(2)requests.get()
环境搭建好后,接下来我们先来了解一下requests的一些简单使用,主要包括:
- requests常用请求方法使用,包括:get,post
- requests库中的Session、Cookie的使用
- 其它高级部分:认证、代理、证书验证、超时配置、错误异常处理等。
本节首先来了解一下requests库中如何发送get请求:
一、看下方法定义:
1、到官方文档去了下requests.get()方法的定义,如下:

2、点击右上角的【source】,看一下它的源码如下:

看到最后一行return,get方法最后是通过调用 requests.request 方法实现的,其实在其它的请求方法如post,put,head,delete等方法都是调用的request方法,然后把请求方法的类型传递给request方法第一个参数。
3、HTTP协议是一个基于请求/响应模式的、无状态的,应用层协议。既然有请求,就有响应,来看下resquest中常用的响应信息:

二、get方法简单使用:
1、不带参数的get:

# -*- coding:utf-8 -*- #不带参数的get import requests import json host = "http://httpbin.org/" endpoint = "get" url = ''.join([host,endpoint]) r = requests.get(url) #response = r.json() print type(r.text) print (eval(r.text))
输出:
{
'origin': '183.14.133.88',
'headers': {
'Connection': 'close',
'Host': 'httpbin.org',
'Accept-Encoding': 'gzip,
deflate',
'Accept': '*/*',
'User-Agent': 'python-requests/2.18.1'
},
'args': {
},
'url': 'http: //httpbin.org/get'
}
2、 带参数的get:
# -*- coding:utf-8 -*-
#带参数的get
import requests
import json
host = "http://httpbin.org/"
endpoint = "get"
url = ''.join([host,endpoint])
params = {"show_env":"1"}
r = requests.get(url=url,params=params)
print r.url
输出:
http://httpbin.org/get?show_env=1
{
'origin': '183.14.133.88',
'headers': {
'X-Request-Id': 'ebe922b4-c463-4fe9-9faf-49748d682fd7',
'Accept-Encoding': 'gzip,
deflate',
'X-Forwarded-Port': '80',
'Total-Route-Time': '0',
'Connection': 'close',
'Connect-Time': '0',
'Via': '1.1vegur',
'X-Forwarded-For': '183.14.133.88',
'Accept': '*/*',
'User-Agent': 'python-requests/2.18.1',
'X-Request-Start': '1504755961007',
'Host': 'httpbin.org',
'X-Forwarded-Proto': 'http'
},
'args': {
'show_env': '1'
},
'url': 'http: //httpbin.org/get?show_env=1'
}
3、带header的get:
# -*- coding:utf-8 -*-
import requests
import json
host = "http://httpbin.org/"
endpoint = "get"
url = ''.join([host,endpoint])
headers = {"User-Agent":"test request headers"}
r = requests.get(url)
r = requests.get(url,headers=headers)
#response = r.json()
print (eval(r.text))['headers']['User-Agent']
输出:
test request headers
4、同时带参数和header:
# -*- coding:utf-8 -*-
import requests
import json
host = "http://httpbin.org/"
endpoint = "get"
url = ''.join([host,endpoint])
headers = {"User-Agent":"test request headers"}
params = {"show_env":"1"}
r = requests.get(url)
r = requests.get(url,headers=headers,params=params)
#response = r.json()
print (eval(r.text))['headers']['User-Agent']
print r.url
输出:
test request headers http://httpbin.org/get?show_env=1
(3)requests.post()
一、方法定义
二、post方法简单使用
1、带数据的post
2、带header的post
3、带json的post
4、带参数的post
5、普通文件上传
6、定制化文件上传
7、多文件上传
一、方法定义:
1、到官方文档去了下requests.post()方法的定义,如下:

2、源码:

3、常用返回信息:

二、post方法简单使用:
1、带数据的post:
# -*- coding:utf-8 -*-
import requests
import json
host = "http://httpbin.org/"
endpoint = "post"
url = ''.join([host,endpoint])
data = {'key1':'value1','key2':'value2'}
r = requests.post(url,data=data)
#response = r.json()
print (r.text)
输出:
{
"args": {},
"data": "",
"files": {},
"form": {
"key1": "value1",
"key2": "value2"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "23",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.1"
},
"json": null,
"origin": "183.14.133.88",
"url": "http://httpbin.org/post"
}
2、带header的post:
# -*- coding:utf-8 -*-
import requests
import json
host = "http://httpbin.org/"
endpoint = "post"
url = ''.join([host,endpoint])
headers = {"User-Agent":"test request headers"}
# r = requests.post(url)
r = requests.post(url,headers=headers)
#response = r.json()
输出:
{
"args": {},
"data": "",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "0",
"Host": "httpbin.org",
"User-Agent": "test request headers"
},
"json": null,
"origin": "183.14.133.88",
"url": "http://httpbin.org/post"
}
3、带json的post:
# -*- coding:utf-8 -*-
import requests
import json
host = "http://httpbin.org/"
endpoint = "post"
url = ''.join([host,endpoint])
data = {
"sites": [
{ "name":"test" , "url":"www.test.com" },
{ "name":"google" , "url":"www.google.com" },
{ "name":"weibo" , "url":"www.weibo.com" }
]
}
r = requests.post(url,json=data)
# r = requests.post(url,data=json.dumps(data))
response = r.json()
输出:
{
"args": {},
"data": "{\"sites\": [{\"url\": \"www.test.com\", \"name\": \"test\"}, {\"url\": \"www.google.com\", \"name\": \"google\"}, {\"url\": \"www.weibo.com\", \"name\": \"weibo\"}]}",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "140",
"Content-Type": "application/json",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.1"
},
"json": {
"sites": [
{
"name": "test",
"url": "www.test.com"
},
{
"name": "google",
"url": "www.google.com"
},
{
"name": "weibo",
"url": "www.weibo.com"
}
]
},
"origin": "183.14.133.88",
"url": "http://httpbin.org/post"
}
4、带参数的post:
# -*- coding:utf-8 -*-
import requests
import json
host = "http://httpbin.org/"
endpoint = "post"
url = ''.join([host,endpoint])
params = {'key1':'params1','key2':'params2'}
# r = requests.post(url)
r = requests.post(url,params=params)
#response = r.json()
print (r.text)
输出:
{
"args": {
"key1": "params1",
"key2": "params2"
},
"data": "",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "0",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.1"
},
"json": null,
"origin": "183.14.133.88",
"url": "http://httpbin.org/post?key2=params2&key1=params1"
}
5.普通文件上传:
# -*- coding:utf-8 -*-
import requests
import json
host = "http://httpbin.org/"
endpoint = "post"
url = ''.join([host,endpoint])
#普通上传
files = {
'file':open('test.txt','rb')
}
r = requests.post(url,files=files)
print (r.text)
输出:
{
"args": {},
"data": "",
"files": {
"file": "hello world!\n"
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "157",
"Content-Type": "multipart/form-data; boundary=392865f79bf6431f8a53c9d56c62571e",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.1"
},
"json": null,
"origin": "183.14.133.88",
"url": "http://httpbin.org/post"
}
6.定制化文件上传:
# -*- coding:utf-8 -*-
import requests
import json
host = "http://httpbin.org/"
endpoint = "post"
url = ''.join([host,endpoint])
#自定义文件名,文件类型、请求头
files = {
'file':('test.png',open('test.png','rb'),'image/png')
}
r = requests.post(url,files=files)
print (r.text)heman793
7.多文件上传:
# -*- coding:utf-8 -*-
import requests
import json
host = "http://httpbin.org/"
endpoint = "post"
url = ''.join([host,endpoint])
#多文件上传
files = [
('file1',('test.txt',open('test.txt', 'rb'))),
('file2', ('test.png', open('test.png', 'rb')))
]
r = requests.post(url,files=files)
print (r.text)
8.流式上传:
# -*- coding:utf-8 -*-
import requests
import json
host = "http://httpbin.org/"
endpoint = "post"
url = ''.join([host,endpoint])
#流式上传
with open( 'test.txt' ) as f:
r = requests.post(url,data = f)
print (r.text)
输出:
{
"args": {},
"data": "hello world!\n",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "13",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.18.1"
},
"json": null,
"origin": "183.14.133.88",
"url": "http://httpbin.org/post"
}
(4)Cookie&Session
掌握了前面几节的的内容,就可以做一些简单的http协议接口的请求发送了,但是这些还不够。HTTP协议是一个无状态的应用层协议,也就是说前后两次请求是没有任何关系的,那如果我们测试的接口之前有相互依赖关系怎么办呢(比如我要在博客园发文章,是需要先登录的),这时我们就要用到cookie和session技术来保持客户端与服务器端连接的状态,这也就是本节要介绍的内容:
一、Cookie:
1、获取cookie:
# -*- coding:utf-8 -*-
#获取cookie
import requests
import json
url = "https://www.baidu.com/"
r = requests.get(url)
#将RequestsCookieJar转换成字典
c = requests.utils.dict_from_cookiejar(r.cookies)
print r.cookies
print c
for a in r.cookies:
print a.name,a.value
输出:
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
{'BDORZ': '27315'}
BDORZ 27315
2、发送Cookie
# -*- coding:utf-8 -*-
#发送cookie到服务器
import requests
import json
host = "http://httpbin.org/"
endpoint = "cookies"
url = ''.join([host,endpoint])
#方法一:简单发送
# cookies = {"aaa":"bbb"}
# r = requests.get(url,cookies=cookies)
# print r.text
#方法二:复杂发送
s = requests.session()
c = requests.cookies.RequestsCookieJar()
c.set('c-name','c-value',path='/xxx/uuu',domain='.test.com')
s.cookies.update(c)
二、Session
1、保持会话同步:
# -*- coding:utf-8 -*- import requests import json host = "http://httpbin.org/" endpoint = "cookies" url = ''.join([host,endpoint]) url1 = "http://httpbin.org/cookies/set/sessioncookie/123456789" r = requests.get(url) print r.text print "------" s = requests.session() #初始化一个session对象 s.get(url1) #cookie的信息存在了session中 r = s.get(url) print r.text
输出:
{
"cookies": {}
}
------
{
"cookies": {
"sessioncookie": "123456789"
}
}
2、保存绘画信息:
# -*- coding:utf-8 -*-
import requests
import json
host = "http://httpbin.org/"
endpoint = "headers"
url = ''.join([host,endpoint])
header1 = {"testA":"AAA"}
header2 = {"testB":"BBB"}
s = requests.session() #初始化一个session对象
s.headers.update(header1) #已经存在于服务中的信息
r = s.get(url,headers=header2) #发送新的信息
print r.text
输出:
{
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Host": "httpbin.org",
"Testa": "AAA",
"Testb": "BBB",
"User-Agent": "python-requests/2.18.1"
}
}
3.删除已存在的会话信息,保存为None
# -*- coding:utf-8 -*-
import requests
import json
host = "http://httpbin.org/"
endpoint = "headers"
url = ''.join([host,endpoint])
header1 = {"testA":"AAA"}
header2 = {"testB":"BBB"}
s = requests.session() #初始化一个session对象
s.headers.update(header1) #已经存在于服务中的信息
r = s.get(url,headers=header2) #发送新的信息
print r.text
print '--------'
s.headers['testA'] = None #删除会话里的信息testA
r1 = s.get(url,headers = header2)
print r1.text
{
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Host": "httpbin.org",
"Testa": "AAA",
"Testb": "BBB",
"User-Agent": "python-requests/2.18.1"
}
}
--------
{
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Host": "httpbin.org",
"Testb": "BBB",
"User-Agent": "python-requests/2.18.1"
}
}
4、提供默认数据:
s = requests.Session()
s.auth = ('user', 'pass')
s.headers.update({'x-test': 'true'})
# both 'x-test' and 'x-test2' are sent
s.get('http://httpbin.org/headers', headers={'x-test2': 'true'})
参考:
http://docs.python-requests.org/en/master/user/quickstart/#cookies
http://docs.python-requests.org/en/master/user/advanced/#session-objects
(5)其他(认证&代理&超时设置)
一、认证
1、基本认证:
# -*- coding:utf-8 -*-
import requests
url = "http://httpbin.org/basic-auth/user/passwd"
r1 = requests.get(url)
print "未提供用户名密码:" + str(r1.status_code)
#Basic Authentication
r2 = requests.get(url,auth=('user','passwd'))
print "已提供用户名密码:" + str(r2.status_code)
输出:
未提供用户名密码:401 已提供用户名密码:200
2、数字认证:
>>> from requests.auth import HTTPDigestAuth
>>> url = 'http://httpbin.org/digest-auth/auth/user/pass'
>>> requests.get(url, auth=HTTPDigestAuth('user', 'pass'))
<Response [200]>
3、OAuth认证:
参考:http://docs.python-requests.org/en/master/user/authentication/
二、代理
1、方法一:proxy参数:
import requests
proxies = {
"https": "http://41.118.132.69:4433"
}
r = requests.post("http://httpbin.org/post", proxies=proxies)
print r.text
2、方法二:设置环境变量:
$ export HTTP_PROXY="http://10.10.1.10:3128"
$ export HTTPS_PROXY="http://10.10.1.10:1080"
$ python
>>> import requests
>>> requests.get('http://example.org')
3、HTTP Basic Auth使用代理方法:http://user:password@host/
proxies = {'http': 'http://user:pass@10.10.1.10:3128/'}
三、证书验证
1、SSL证书(HTTPS):
import requests
#跳过12306 的证书验证,把 verify 设置为 False:
r = requests.get('https://kyfw.12306.cn/otn/', verify=False)
print r.text
2、客户端证书:
>>> requests.get('https://kennethreitz.org', cert=('/path/client.cert', '/path/client.key'))
<Response [200]>
or
s = requests.Session() s.cert = '/path/client.cert'
四、超时配置
1 、利用timeout参数来配置最大请求时间:
r = requests.get('https://github.com', timeout=5)
2、设置timeout=None,告诉请求永远等待响应,而不将请求作为超时值传递
r = requests.get('https://github.com', timeout=None)
五、错误异常:
1、所有Requests显式抛出的异常都继承自:requests.exctptions.RequestException
2、遇到网络问题(如:DNS查询失败,拒绝连接等)时,requests会抛出一个 ConnectionError 异常
3、遇到罕见的无效HTTP响应时,Request则会抛出一个 HTTPError 异常
4、若请求超时,则抛出一个 Timeout 异常
5、若请求超过了最大的重写向次数,则会抛出一个 TooManyRedirects 异常
(6)unittest-单个用例管理:
上面主要介绍了环境搭建和requests库的使用,可以使用这些进行接口请求的发送。但是如何管理接口案例?返回结果如何自动校验?这些内容光靠上面五节是不行的,因此从本节开始我们引入python单元测试框架 unittest,用它来处理批量用例管理,校验返回结果,初始化工作以及测试完成后的环境复原工作等等。
一、单个用例管理起来比较简单,参考如下图,单个用例一般多用在调试的时候:

二、代码如下:
# -*- coding:utf-8 -*-
# 单个用例执行
# 1、导入模块
import unittest
# 2、继承自unittest.TestCase类
class TestOne(unittest.TestCase):
# 3、配置环境:进行测试前的初始化工作
def setUp(self):
print '\ncases before'
pass
# 4、定义测试用例,名字以“test”开头
def test_add(self):
'''test add method'''
print 'add...'
a = 3 + 4
b = 7
# 5、定义assert断言,判断测试结果
self.assertEqual(a, b)
def test_sub(self):
'''test sub method'''
print 'sub...'
a = 10 - 5
b = 4
self.assertEqual(a, b)
# 6、清理环境
def tearDown(self):
print 'case after'
pass
# 7、该方法会搜索该模块下所有以test开头的测试用例方法,并自动执行它们
if __name__ == '__main__':
unittest.main()
输出:
Ran 2 tests in 0.001s OK cases before add... case after cases before sub... case after Process finished with exit code 0
(8)unittest-生成测试报告:
用例的管理问题解决了后,接下来要考虑的就是报告我问题了,这里生成测试报告主要用到 HTMLTestRunner.py 这个模块,下面简单介绍一下如何使用:
一、下载HTMLTestRunner下载:
这个模块不能通过pip安装,只能下载安装,下载地址如下:
- python2.x版本:http://tungwaiyip.info/software/HTMLTestRunner.html
- python3.x版本:http://hzqldjb.blog.51cto.com/9587820/1590802
二、mac下配置:
1、终端进入python环境
2、输入:
import sys print sys.path
- case包下面有baidu,httpbin两个包
- 每个包下面分别有两个测试的py文件
- 每个test_00x.py文件里各有2个test case
- run_all_case.py文件:用来执行所有的test case且生成测试报告
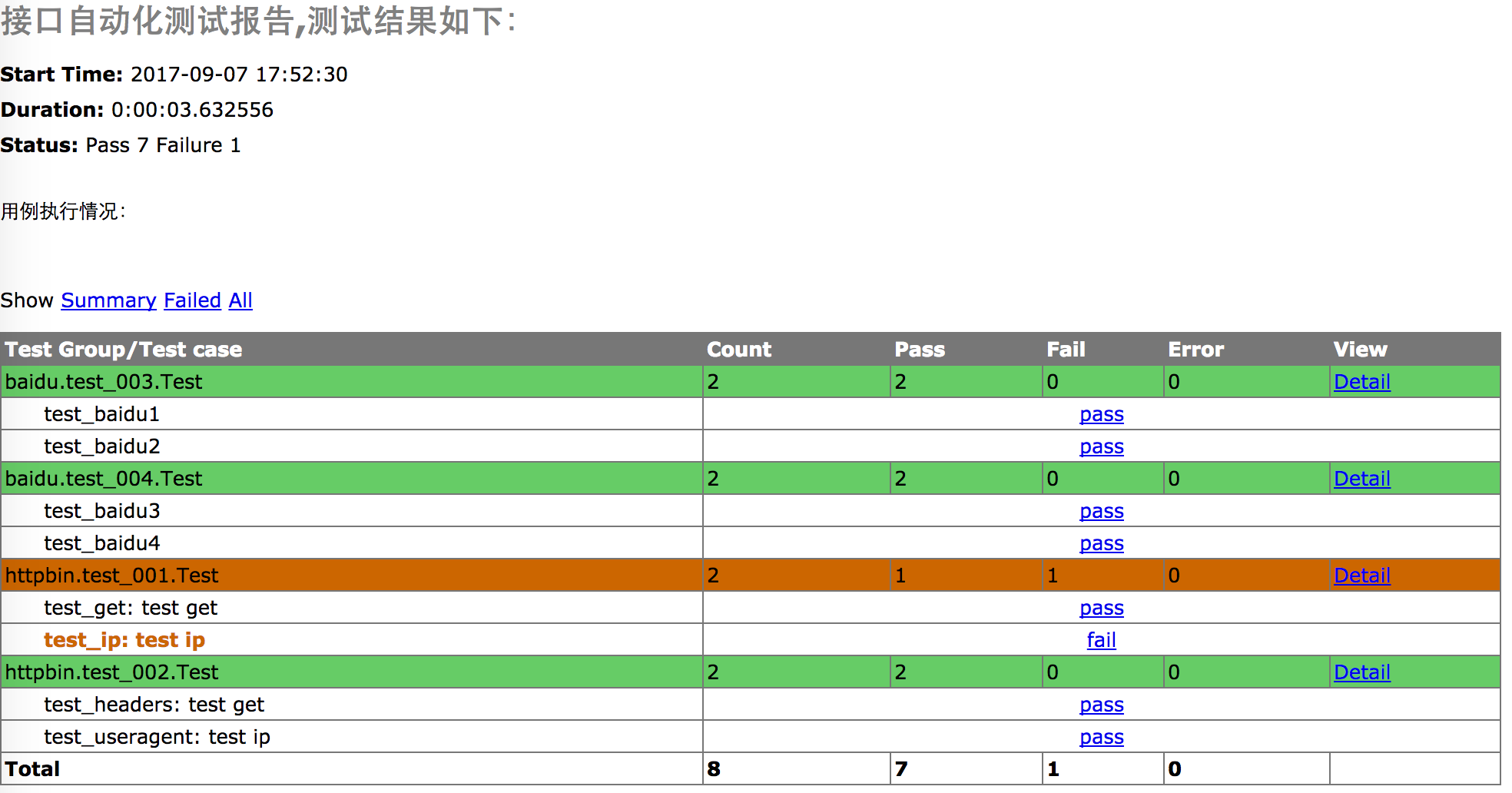
2、运行后生成报告如下:
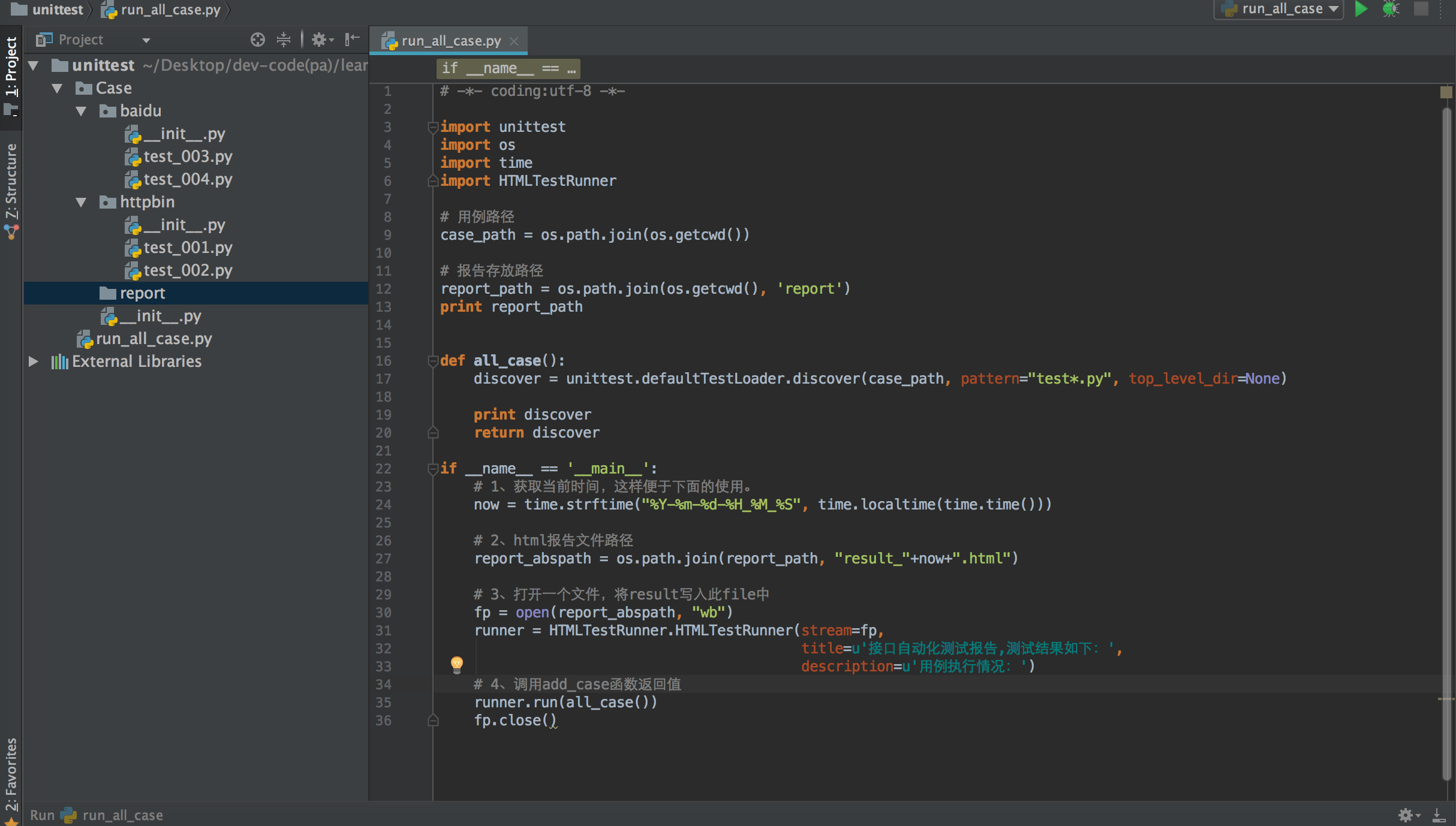
3、run_all_case.py代码如下:
# -*- coding:utf-8 -*-
import unittest
import os
import time
import HTMLTestRunner
# 用例路径
case_path = os.path.join(os.getcwd())
# 报告存放路径
report_path = os.path.join(os.getcwd(), 'report')
print report_path
def all_case():
discover = unittest.defaultTestLoader.discover(case_path, pattern="test*.py", top_level_dir=None)
print discover
return discover
if __name__ == '__main__':
# 1、获取当前时间,这样便于下面的使用。
now = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))
# 2、html报告文件路径
report_abspath = os.path.join(report_path, "result_"+now+".html")
# 3、打开一个文件,将result写入此file中
fp = open(report_abspath, "wb")
runner = HTMLTestRunner.HTMLTestRunner(stream=fp,
title=u'接口自动化测试报告,测试结果如下:',
description=u'用例执行情况:')
# 4、调用add_case函数返回值
runner.run(all_case())
fp.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号