

hbase连接过程
hbase client在写入的数据的过程中,是直接和rs进行通信的,整个的数据写入流程并不涉及到HMaster。那么client是如何找到对应的rs呢?流程如下:
- client从zookeeper中获取存储hbase:root表的RegionServer(设为rs1)的地址信息,hbase考虑到hbase:meta表过大,存储到了不同的region中,需要一个hbase:root的表对hbase:meta表的元数据进行存储。在0.98版本后,hbase:mata表不在split,只有一个region,也去除掉了hbase:root表,client的访问过程也不用进行这一步。
- client访问rs1,从hbase:root表中获取对应hbase:meta表的RegionServer(rs2)的地址信息。这里有些问题?hbase:root中如何知道一条数据应该写入哪个RegionServer?而这个对应的RegionServer应该存储在哪个hbase:meta中?在下面介绍hbase:meta表介绍。
- client访问rs2,从hbase:meta表中获取对应要访问的region的RegionServer(rs3)的地址信息。
- client访问rs3,和rs3进行数据交互。这里是具体的数据插入流程看下面两个具体的步骤(hbase客户端流程和hbase服务器端流程)。
meta表和root表格式:
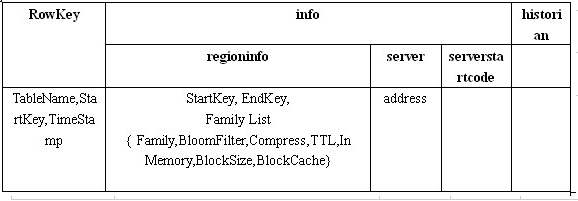
meta表结构例子:
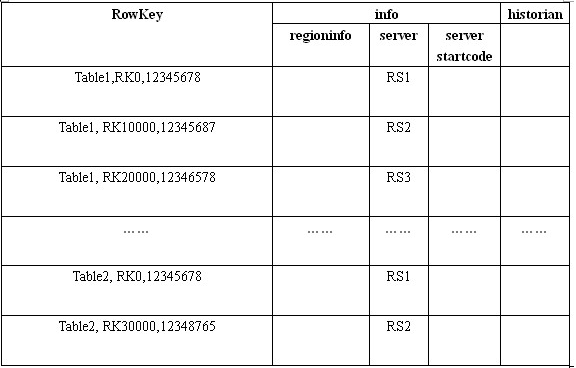
root表结构例子:

- 回答一下上面步骤二问题,从上面的root表中可以知道,RowKey里面包含了具体的表信息,这里就可以排除其他表,在regioninfo里面有具体的startKey和endKey信息,这里可以判断该条数据是否在这个区间。通过这两个信息就可以查找到对应meta表的rs地址。同理可以在meta表中查到到对应的数据交互的rs。
- 还有一个问题,是否每次put数据都需要进行这3次连接?其实不用的,每次client和hbase进行通信后,将访问过的meta表信息存储在本地。数据首先从本地的缓存中获取meta表数据,直接访问rs进行数据交互。
hbase客户端流程
- 用户提交put请求。hbase client提交可以设置autoflush参数,该参数默认autoflush=true,表示put请求会直接提交给服务器进行处理。可以设置为autoflush=false,这样的话put请求数据首先会存放在buffer中,等待本地的buffer数据大小达到阈值之后才会提交。很明显,两种方式的有优缺点在于,方式一数据写入慢,但是不会丢数据,方式二写入快,但是存在丢数据的风险。
- 在提交数据之前,client通过meta表查找到对应rowkey所属的rs,如果的批量提交,会将rowkey对应不同的rs分组,每个分组分别批量提交。
hbase服务器端流程
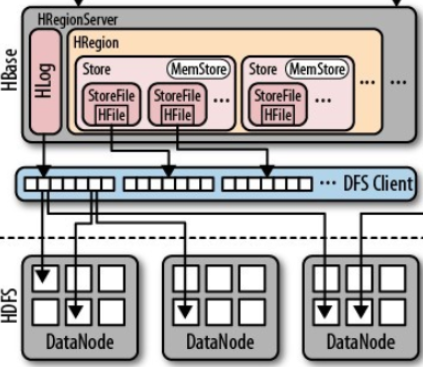
数据的写入流程:
- 数据首先写入到wal中
- 然后数据写入到MemStore中
- 当MemStore中的数据大小超过阈值,flush到HFile中
当机器出现宕机情况,因为wal和HFile中的数据存储在hdfs中,并不会出现数据丢失情况,数据丢失的是在MemStore中尚未flush到HFile的数据,可以从wal将这部分数据从新恢复
