codingHTTP:https://git.coding.net/clairewyd/wf.git
SSH方式:git@git.coding.net:clairewyd/wf.git
运行程序:http://pan.baidu.com/s/1qYPsDRI
本次作业采用c#语言进行编程。主要功能包括:
1)在指定文件中进行输入,之后运行程序进行词频统计。
2)输入文件夹中的文件名,并对其进行词频统计。
3)对指定目录遍历其中文件,对每一个文件进行词频统计,并输出前10个出现率最高的单词。
4)在控制台输入文本内容,并统计它的词频。
各个功能调用的主要函数都有很大部分的重叠,如都调用了CountEachWord方法,因此对主要函数进行说明:
1. CountEachWord(string url,int choice)划分文件中的单词,在这个程序中凡是以字母开头的文本算是一个单词,如1a不算是单词,但是a1算是一个单词。程序中使用了正则表达式进行单词匹配,使用Regex类中的Matches方法得到一个单词Match集合,并将其存储到忽略大小写的hashtable中。
int count = 0; //单词总数统计变量 StreamReader streamReader = new StreamReader(url); string line; Regex regex = new Regex(@"\b[A-Za-z]+[A-Za-z0-9]*"); while ((line = streamReader.ReadLine()) != null) { MatchCollection matchCollection = regex.Matches(line); foreach(Match word in matchCollection) { string words = word.ToString(); if (hashtable.Contains(words)) { int j = Convert.ToInt32(hashtable[words]) + 1; hashtable[words] = j; } else { hashtable.Add(words, 1); } } } //输出文章中不重复的单词总数 count = hashtable.Keys.Count; Console.WriteLine("total: " + count);
2. 对hash表中的单词数从大到小进行排序。先将hashtable中的键(单词)和值(单词频率)存储到数组,以数组索引值为链接。使用了快速排序。快速排序的时间复杂度为O(nlogn)
ArrayList arrayList = new ArrayList(hashtable.Keys); string[] keyArray = new string[arrayList.Count]; int[] valueArray = new int[arrayList.Count]; int index = 0; foreach(string key in arrayList) { //keyArray[index] = key; keyArray[index] = Convert.ToString(key); valueArray[index] = Convert.ToInt32(hashtable[key]); index++; } //快速排序递归算法 QuickSort(valueArray,keyArray, 0, arrayList.Count - 1);
3 . 功能4中曾出现如果输入大文本数据的时候会抛出异常的问题,对此进行了改进
改进前代码如下:
StreamWriter streamWriter = new StreamWriter(path, false); string line = Console.ReadLine(); streamWriter.WriteLine(line); streamWriter.Close(); this.GetFile(path); this.CountEachWord(path, 1);
这段代码若输入大文本数据(如gone_with_the_wind.txt)会抛出“未经处理的异常: System.ArgumentOutOfRangeException: 索引和计数必须引用该缓冲”异常,后改进代码,但是这样存进文件的并不是原输入的文本文件,而是hash表中的单词,因为作业没有明确指出要将控制台输入文本存进文件,所以没有对此进行进一步改善。代码如下:
public void InputAndCount(string path) { Console.WriteLine("请输入文本内容(结束请按回车并输入-155.555)"); StreamWriter streamWriter = new StreamWriter(path, false); Regex regex = new Regex(@"\b[A-Za-z]+[A-Za-z0-9]*"); int count = 0; string line; while((line = Console.ReadLine()) != "-155.555") { //streamWriter.WriteLine(line); MatchCollection matchCollection = regex.Matches(line); foreach (Match word in matchCollection) { string words = word.ToString(); if (hashtable.Contains(words)) { int j = Convert.ToInt32(hashtable[words]) + 1; hashtable[words] = j; } else { hashtable.Add(words, 1); streamWriter.Write(words+" "); } } }
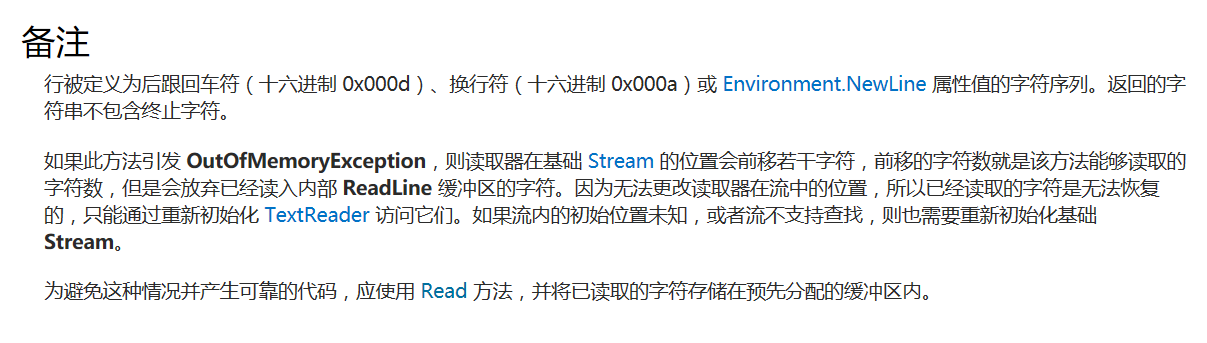
注:18日晚做最后测试时又发现,使用上面一段改进代码,可以运行大文本数据(测试时使用3.13MB的war_and_peace.txt可以正常运行),但是如果输入有某一行很长且没有回车换行符的文件时(一行大约超过45个单词)会出现加载错误。查阅msdn发现是Console.ReadLine()方法缓冲区的问题,具体可参见下面的msdn截图。但是如果使用read()方法,读到的是ASCII码经类型转换后加入hash表统计的词频是错误的。故而因为能力有限,提交的代码目前只能做到输入长行时只加载一部分,但是不抛出异常,加载的部分可以正常统计词频。会继续学习c#进行改进的。
PSP阶段表格:
(表格中实际时间是真正的编码时间,不包括学习查资料,所以记录方面可能与真正时间有出入,但是误差控制在5分钟以内)

分析原因:
预计时间与实际时间有较大出入的地方在三个地方:
1.最开始编程时,因为从来没学习过c#语言,也想趁此机会对c#进行系统的学习,而不是只完成一个小程序,所以打算系统的学习一下c#,故而预记花费很长时间打算先学习下语法,再编写程序,但是借来书后发现c#与java有很大程度的相似,故而抛弃了原来的打算,边编写程序边学习。所以比预计时间少很多。
2.第二处是在功能2的测试完善时,这个主要时因为在项目完成把它传到coding.net上后我自己又把网上的下了一次发现运行不通过(这个表并不是按时间顺序划分的而是按作业要求按功能划分的,所以时间都写在了一起)。后来发现是因为文件的相对路径的问题。
3第三处是功能4模块的测试及完善处,这个是因为在最后的测试时突然发现对于有些大文本数据程序会抛出异常(再另一篇作业中有具体说明)。因为能力不足,所以改了很久,最后虽然解决了这个问题,但是解决的方法并不完美,希望在日后的学习中能够找到更好的办法。
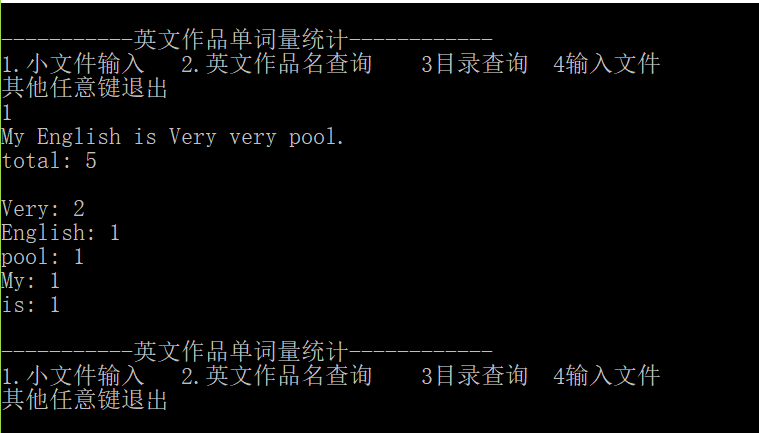
程序截图: