
基础环境
流程概述
此次编译过程是将Spark-3.1.1源码包下载到Windows本机,使用maven编译,编译完成后导入IDEA运行,连接Linux端hive做SQL操作。
软件版本
Linux端:
hadoop-2.6.0-cdh5.16.2
apache-hive-3.1.2-bin
Windows端:(最好安装vpn软件)
java-1.8
maven-3.6.3
scala-2.12.10
spark-3.1.1 (不用安装,解压到指定目录即可)
配置修改
修改pom文件
修改Spark根目录下的pom文件
(1)添加软件源
pom文件中的谷歌仓库一定要放到第一位,自己配置的仓库放到后面,阿里仓库建议添加,CDH版本可以多添加一个cloudera仓库。
位置:pom文件264行左右
<repository> <id>gcs-maven-central-mirror</id> <!-- Google Mirror of Maven Central, placed first so that it's used instead of flaky Maven Central. See https://storage-download.googleapis.com/maven-central/index.html --> <name>GCS Maven Central mirror</name> <url>https://maven-central.storage-download.googleapis.com/maven2/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> </repository> <repository> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> </repository> <repository> <id>cloudera</id> <name>cloudera repository</name> <url>https://repository.cloudera.com/artifactory/cloudera-repos/</url> </repository>
(2)添加模块
将以下内容添加到module中。
位置:pom文件100行左右
<module>sql/hive-thriftserver</module>
修改编译脚本
需要修改编译脚本中的各组件的指定版本号,如果不修改,编译时可能会卡,住此处修改的内容与编译命令中的 “-D” 选项有相同作用。
spark:当前编译的版本即可;
scala:当前windows中安装的scala版本,如果是 2.11.x 版本,那编译之前需要做scala version change 操作;
hadoop:Linux服务器中的hadoop版本;
hive:1代表开启hive支持,不需要在此处指定hive版本。
# spark版本 VERSION=3.1.1 # scala版本 SCALA_VERSION=2.12 # hadoop版本 SPARK_HADOOP_VERSION=2.6.0-cdh5.16.2 # 开启hive SPARK_HIVE=1

编译运行
理想状态下,修改完以上内容就可以开始编译,并且能改编译成功了,但是由于诸如版本、配置等略有差异,在编译和运行的过程中可能会出现各种各样的报错,我将在报错修改中将我遇到的报错问题一一列举。
源码编译
进入到spark-3.1.1根目录下,右键打开Git Bash。
将以下命令复制进去并执行
此处的 -Dhadoop.version 和 -Dscala.version=2.12.10 与上面修改的编译脚本中的hadoop和scala有对应关系,功能作用相同,编译脚本中修改的选项,在命令中可以不用添加。
--name:写hadoop版本
--pip:不需要
--tgz:打包使用
./dev/make-distribution.sh \ --name 2.6.0-cdh5.16.2 \ --tgz -Phive \ -Phive-thriftserver \ -Pyarn -Phadoop-2.7 \ -Dhadoop.version=2.6.0-cdh5.16.2 \ -Dscala.version=2.12.10
大概等20分钟左右,编译成功。
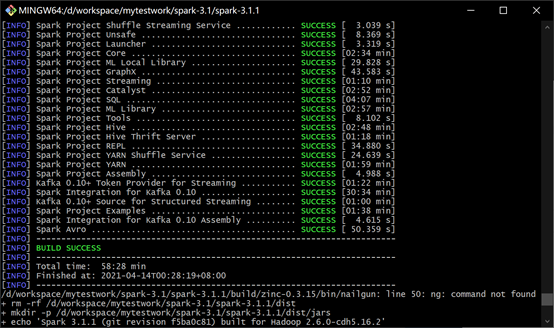
编译之后生成文件:
导入IDEA
(1)导入IDEA之后需要将根目录下的pom文件Reimport一次,将依赖加载;
(2)整个项目rebuild一次,将导入到IDEA后不匹配的地方重新编译一次;
(3)导入服务器中配置文件到:spark-3.1/spark-3.1.1/sql/hive-thriftserver/src/main/resources

要重点检查hive-site.xml文件,开启:hive.metastore.uris


<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://ruozedata:9000</value> </property> <!--指定hadoop临时目录, hadoop.tmp.dir 是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配 置namenode和datanode的存放位置,默认就放在这>个路径中 --> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/tmp/hadoop</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> </configuration>
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- 指定HDFS副本的数量 --> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 连接数据库 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://ruozedata:3306/ruozedata_hive?createDatabaseIfNotExist=true;characterEncoding=utf-8&useSSL=false;</value> </property> <!-- 数据库驱动 --> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <!-- 数据库用户 --> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <!-- 数据库密码 --> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>ruozedata</value> </property> <!-- 启用本地模式 --> <property> <name>hive.exec.mode.local.auto</name> <value>true</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://ruozedata:9083</value> </property> <property> <name>hive.insert.into.multilevel.dirs</name> <value>true</value> </property> </configuration>
#log4j.rootLogger=ERROR, stdout # #log4j.appender.stdout=org.apache.log4j.ConsoleAppender #log4j.appender.target=System.out #log4j.appender.stdout.layout=org.apache.log4j.PatternLayout #log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.rootLogger=INFO, stdout #log4j.rootLogger=ERROR, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
运行主类
(1)Linux启动Hive服务:hive --service metastore &
(2)启动SparkSQLDriver:org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver
(3)操作hive表
spark-sql (default)> show databases; show databases; databaseName company default hive_function_analyze skewtest spark-sql (default)> Time taken: 0.028 seconds, Fetched 10 row(s) select * from score; INFO SparkSQLCLIDriver: Time taken: 1.188 seconds, Fetched 4 row(s) id name subject 1 tom ["HuaXue","Physical","Math","Chinese"] 2 jack ["HuaXue","Animal","Computer","Java"] 3 john ["ZheXue","ZhengZhi","SiXiu","history"] 4 alice ["C++","Linux","Hadoop","Flink"] spark-sql (default)>
报错修改
报错:NoClassDefFoundError: com/google/common/cache/CacheLoader
Exception in thread "main" java.lang.NoClassDefFoundError: com/google/common/cache/CacheLoader at org.apache.spark.internal.Logging$.<init>(Logging.scala:189) at org.apache.spark.internal.Logging$.<clinit>(Logging.scala) at org.apache.spark.internal.Logging.initializeLogIfNecessary(Logging.scala:108) at org.apache.spark.internal.Logging.initializeLogIfNecessary$(Logging.scala:105) at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.initializeLogIfNecessary(SparkSQLCLIDriver.scala:57) at org.apache.spark.internal.Logging.initializeLogIfNecessary(Logging.scala:102) at org.apache.spark.internal.Logging.initializeLogIfNecessary$(Logging.scala:101) at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.initializeLogIfNecessary(SparkSQLCLIDriver.scala:57) at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.<init>(SparkSQLCLIDriver.scala:63) at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.<clinit>(SparkSQLCLIDriver.scala) at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala) Caused by: java.lang.ClassNotFoundException: com.google.common.cache.CacheLoader at java.net.URLClassLoader.findClass(URLClassLoader.java:382) at java.lang.ClassLoader.loadClass(ClassLoader.java:418) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355) at java.lang.ClassLoader.loadClass(ClassLoader.java:351) ... 11 more
解决:修改pom文件
修改hive-thriftserver模块下的pom.xm文件
位置:pom文件422行左右
<dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-server</artifactId> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-servlet</artifactId> <!-- <scope>provided</scope>--> </dependency>
修改主pom.xml文件
位置:pom文件84行左右
<dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-http</artifactId> <version>${jetty.version}</version> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-continuation</artifactId> <version>${jetty.version}</version> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-servlet</artifactId> <version>${jetty.version}</version> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-servlets</artifactId> <version>${jetty.version}</version> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-proxy</artifactId> <version>${jetty.version}</version> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-client</artifactId> <version>${jetty.version}</version> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-util</artifactId> <version>${jetty.version}</version> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-security</artifactId> <version>${jetty.version}</version> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-plus</artifactId> <version>${jetty.version}</version> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-server</artifactId> <version>${jetty.version}</version> <!-- <scope>provided</scope>--> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-webapp</artifactId> <version>${jetty.version}</version> <!-- <scope>provided</scope>--> </dependency>
修改主pom.xml文件
位置:pom文件663行左右,换成compile
<dependency> <groupId>xml-apis</groupId> <artifactId>xml-apis</artifactId> <version>1.4.01</version> <scope>compile</scope> </dependency>
修改主pom.xml文件
位置:pom文件486行左右
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>${guava.version}</version> <!-- <scope>provided</scope>--> </dependency>
如果还有其他类似的ClassNotFoundException,都是这个原因引起的,注释即可。
参考连接:https://blog.csdn.net/qq_43081842/article/details/105777311
报错:A master URL must be set in your configuration
2021-04-15 00:59:20,147 ERROR [org.apache.spark.SparkContext] - Error initializing SparkContext. org.apache.spark.SparkException: A master URL must be set in your configuration at org.apache.spark.SparkContext.<init>(SparkContext.scala:394) at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2678) at org.apache.spark.sql.SparkSession$Builder.$anonfun$getOrCreate$2(SparkSession.scala:942) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:936) at org.apache.spark.sql.hive.thriftserver.SparkSQLEnv$.init(SparkSQLEnv.scala:52) at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.<init>(SparkSQLCLIDriver.scala:325) at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:157) at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala) Exception in thread "main" org.apache.spark.SparkException: A master URL must be set in your configuration at org.apache.spark.SparkContext.<init>(SparkContext.scala:394) at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2678) at org.apache.spark.sql.SparkSession$Builder.$anonfun$getOrCreate$2(SparkSession.scala:942) at scala.Option.getOrElse(Option.scala:189) at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:936) at org.apache.spark.sql.hive.thriftserver.SparkSQLEnv$.init(SparkSQLEnv.scala:52) at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.<init>(SparkSQLCLIDriver.scala:325) at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver$.main(SparkSQLCLIDriver.scala:157) at org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver.main(SparkSQLCLIDriver.scala)
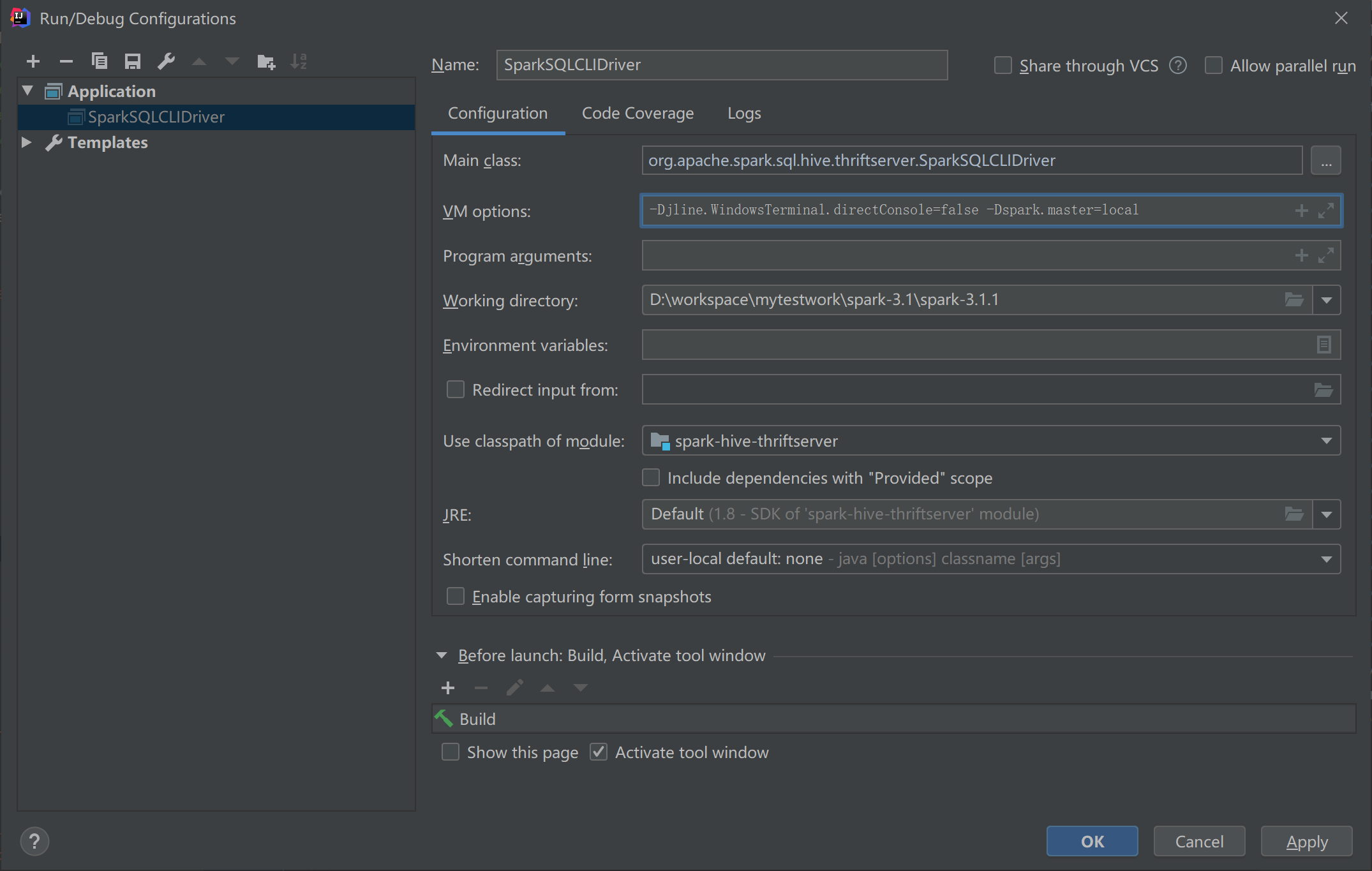
报错:value setRolledLogsIncludePattern is not a member of org.apache.hadoop.yarn.api.records.LogAggregationContext
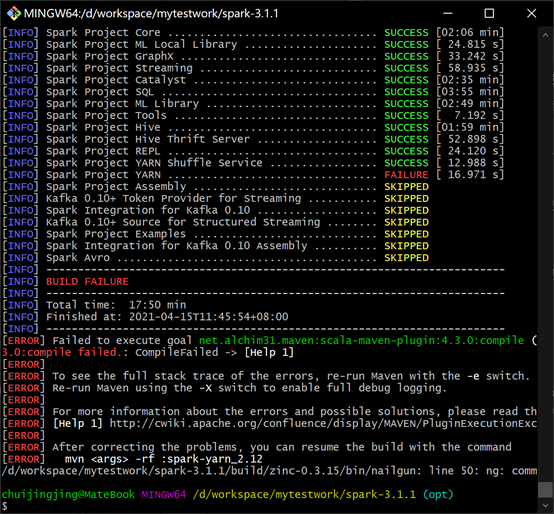
原因:Spark3.x 对hadoop2.x 支持有问题,需要手动修改源码
解决:修改源码:spark-3.1.1\resource-managers\yarn\src\main\scala\org\apache\spark\deploy\yarn\Client.scala
参考链接:https://github.com/apache/spark/pull/16884/files

