
top

主要看:load average: 0.00, 0.01, 0.02
分别为:这个时间段之内的负载情况 5m 10m 15m
df

查看目录文件空间使用情况
-h :以更直观易懂的方式显示空间使用情况。
ps aux

查看服务进程
字段解读(从前往后):进程名,PID, 父PID
注意:有PID不一定有端口号,服务的通信交流使用PID+Port

a :显示现行终端机下的所有程序,包括其他用户的程序
u :以用户为主的格式来显示程序状况。
x :显示所有程序,不以终端机来区分。
tail
$ tail -F hadoop-env.sh
持续将文件中新增加的内容输出。
$ tail -n 20 hadoop-env.sh
将文件最后20行输出。
less
less 与 more 类似,但使用 less 可以随意浏览文件,而 more 仅能向前移动,却不能向后移动,而且 less 在查看之前不会加载整个文件。
$ less hadoop-env.sh
- b 向上翻一页
- d 向后翻半页
- h 显示帮助界面
- Q 退出less 命令
- u 向前滚动半页
- y 向前滚动一行
- 空格键 滚动一页
- 回车键 滚动一行
$ ps -ef |less
ps查看进程信息并通过less分页显示.
$ less hadoop-env.sh yarn-site.xml
输入 :n后,切换到 log2014.log
输入 :p 后,切换到log2013.log
date
$ date
查看当前时间
$ date -s "2021-02-23 12:11:22"
修改时间
netstat
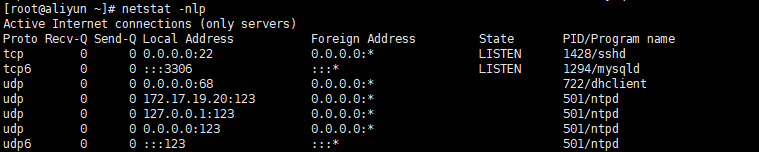
选项解读
-n, --numeric don't resolve names 不解析名称
-p, --programs display PID/Program name for sockets
-l, --listening display listening server sockets
{-t|--tcp} {-u|--udp}
awk
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。
$ awk '{print $1,$4}' log.txt
将log.txt文件中的每列第一个字符和第4个字符输出,默认分割符为Tab

$ awk -F, '{print $1,$4}' log.txt
-F:指定分隔符
$ awk -va=1 -vb=s '{print $1,$1+a,$1b}' log.txt
-v :设置变量

sed
- a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d :删除,因为是删除啊,所以 d 后面通常不接任何咚咚;
- i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
- s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g 就是啦!
- -e :<script>或--expression=<script> 以选项中指定的script来处理输入的文本文件。
- -f :<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
$ sed -e 2a\newline log.txt
在log.txt文件的第四行后添加一行,并将结果输出到标准输出。

$ nl log.txt | sed '2d'
只删除第 2 行(并不是在原文件删除)
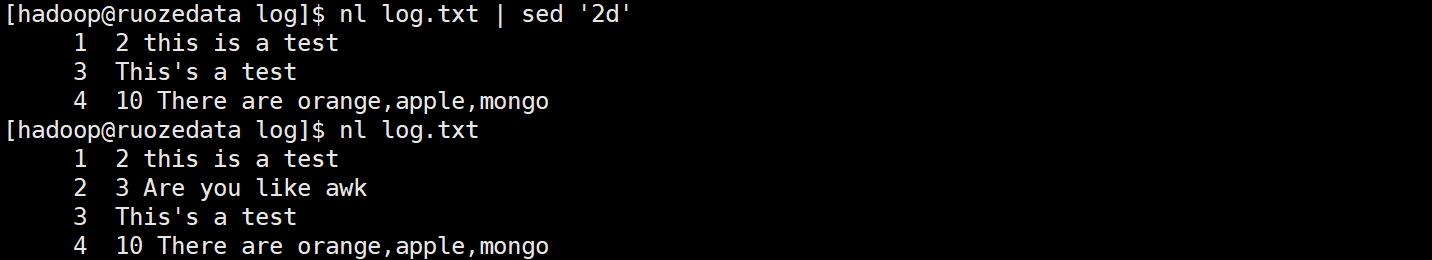
$ nl log.txt | sed '2,4d'
删除第2-4行

$ nl log.txt | sed '3,$d'
删除第 3 到最后一行
![]()

