
试验目标:
把kafka的生产者发出的数据流经由Flume放到HDFS来存储。
试验环境:
java:1.8
kafka:2.11
flume:1.6
hadoop:2.8.5
试验流程:
1.进入zookeeper的bin目录,启动zookeeper
$ zkServer.sh start
2.配置Flume的conf文件
在flume下conf文件夹创建 flume.cof文件
agent.sources = kafkaSource agent.channels = memoryChannel agent.sinks = hdfsSink agent.sources.kafkaSource.channels = memoryChannel agent.sources.kafkaSource.type=org.apache.flume.source.kafka.KafkaSource agent.sources.kafkaSource.zookeeperConnect=127.0.0.1:2181 agent.sources.kafkaSource.topic=flume-data agent.sources.kafkaSource.kafka.consumer.timeout.ms=100 agent.channels.memoryChannel.type=memory agent.channels.memoryChannel.capacity=1000 agent.channels.memoryChannel.transactionCapacity=100 agent.sinks.hdfsSink.type=hdfs agent.sinks.hdfsSink.channel = memoryChannel agent.sinks.hdfsSink.hdfs.path=hdfs://master:9000/usr/feiy/flume-data agent.sinks.hdfsSink.hdfs.writeFormat=Text agent.sinks.hdfsSink.hdfs.fileType=DataStream
3.启动hadoop分布式集群
$ start-all.sh
4.启动kafka服务,并创建一个topic,让flume来消费。
启动kafka:
$ bin/kafka-server-start.sh -daemon ./config/server.properties &
创建topic,主题名:flume-data
$ bin/kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic flume-data
4.启动flume,等待kafka传输消息
进入flume安装目录下的conf目录,执行命令
$ bin/flume-ng agent --conf conf --conf-file conf/flume.conf --name agent -Dflume.root.logger=INFO,console

5.向主kafka里面输入数据
$ bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic flume-data

此时,你输入的数据就会通过flume发送到HDFS里面
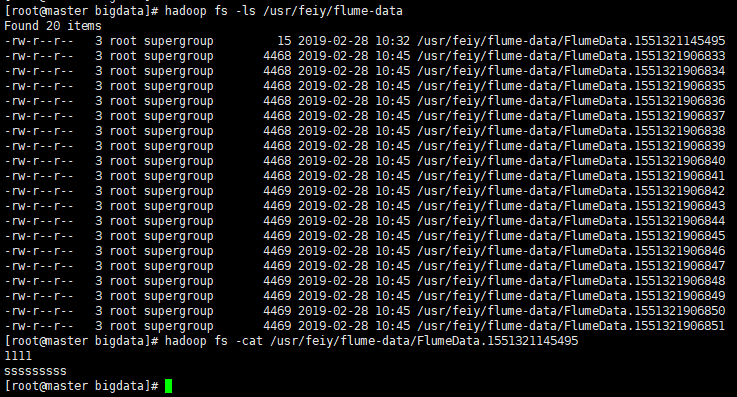
6.查看HDFS里面的文件
$ hadoop fs -ls /usr/feiy/flume-data
$ hadoop fs -cat /usr/feiy/flume-data/FlumeData.1551321145495
代码试验:
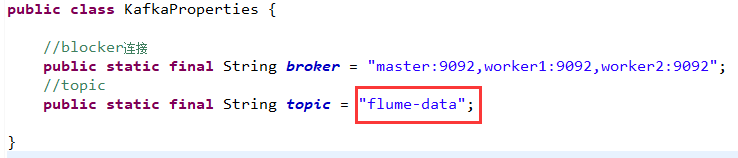
如果是用kafka代码,获取接口的数据,然后向flume里传送,只需要将kafka中的代码中的topic名字设置成服务器上的主题名即可:flume-data
参考:https://blog.csdn.net/feinifi/article/details/73929015

 浙公网安备 33010602011771号
浙公网安备 33010602011771号