
1.NIO与BIO相比,具有哪方面的优势?
(1)非阻塞:提高传输效率
(2)一对多连接:可以用一个或者少量的服务器中的线程来处理大量对的请求从而节省服务器的内存资源
(3)即使是已经建立连接,只要没有对应的读写事件,那么依然不能够使用服务器来进行处理
(4)利用通道来实现双向传输
(5)因为利用缓冲区来存储数据,所以可以对缓冲区中的数据实现定点操作
2.红黑树的特征及其修复过程
3.NIO的基本组件有哪些,并介绍其作用
(1)Buffer 缓冲区:容器 - 存储数据 - 底层用数组来存储数据
(2)Channel 通道:传输数据 - 是面向缓冲区的。在Java中,Channel默认也是阻塞的,需要手动设置其为非阻塞。FileChannel - 文件通道可以利用通道技术实现相同平台之间的零拷贝技术。
(3)Selector 多路复用选择器:进行选择 - 是面向通道进行操作,要求通道是使用的时候必须设置为非阻塞模式。通过Selector可以使用同一服务器同时处理多个客户端发来的数据,可以以少量线程处理大量请求 —— 在底层处理的时候实际上依然是同步的。
4.跳跃表的概念,时间复杂度,适用场景
快速查询数据的结构
O(logN)
适用于读取多,增删改少的场景
5.线程池的定义,特点
定义:储存线程的队列
特点:
(1)线程池在创建的时候是没有线程的
(2)当过来请求的时候,就会线程池中创建一个线程来处理这个请求。当请求请求处理完毕的时候,线程会归还给线程池,等待下一个请求。
(3)核心线程在线程池中需要限定数量
(4)如果所有的核心线程都被占用,那么新来的请求就会被放入工作队列中。工作队列是一个阻塞队列。
(5)如果核心线程都被占用,并且工作队列已满,那么会创建临时线程来处理新的请求
(6)临时线程处理完请求后并不是立即销毁,而是会存货一段时间,如果这段事件之内依旧没有新的请求,那么临时线程就被销毁。
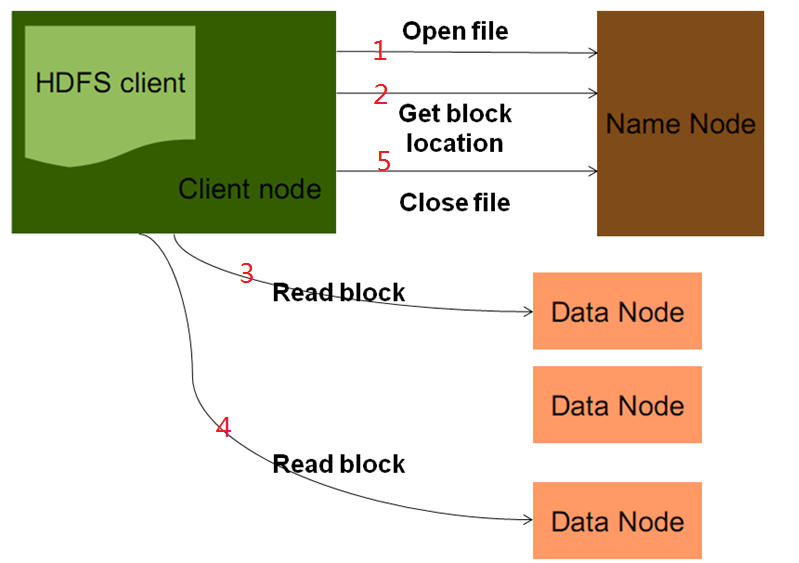
6.hadoop的读过程
1.客户端发起RPC请求访问NameNode
2.namenode会查询元数据,找到这个文件的存储位置对应的数据块的信息
3.namenode将文件对应的数据块的节点地址的全部或者部分放入一个队列中然后返回
4.client收到这个数据块对应的节点地址
5.client会从队列中取出第一个数据块对应的节点地址,会从这些节点地址中选择一个最近的节点进行读取
6.将Block读取之后,对Block进行checksum的验证,如果验证失败,说明数据块产生损坏,那么client会向namenode发送信息说明该节点上的数据块损坏,然后从其它节点中再次读取这个数据块
7.验证成功,则从队列中取出下一个Block的地址,然后继续读取
8.当把这一次的文件块全部读取完之后,client会向namenode要下一批block的地址
9.当把文件全部读取完成之后,从client会向namenode发送一个读取完毕的信号,namenode就会关闭对应的文件
7.hadoop的shuffle过程
MapTask
1.获取到切片(FileSplit)信息
2.每一个切片对应一个MapTask
3.读取具体的数据块
4.按行读取数据
5.每一行数据会调用一次map方法,进行处理
6.map方法在执行完成之后会产生k-v结构,这个数据会存在缓冲区中
7.在缓冲区中会进行partition/sort/combine
8.缓冲区默认大小是100M,缓冲区中还会有一个阀值 —— 80% ——就意味着如果缓冲区使用达到了80%的时候,认为缓冲区满了
9.如果缓冲区满了,就会将缓冲区中的数据写到磁盘的文件中,过程称为Spill(溢写),写出的文件称之为溢写文件。
10.每一个溢写文件中的数据是分好区且排好序的
11.每一次spill过程都会产生一个新的溢写文件,所以所有的溢写文件从整体上不是分区而是排序的
12.在交给ReduceTask之前,会对所有的溢写文件进行一次合并 —— merge
13.合并之后的文件是对所有的数据进行了整体的分区并且排序
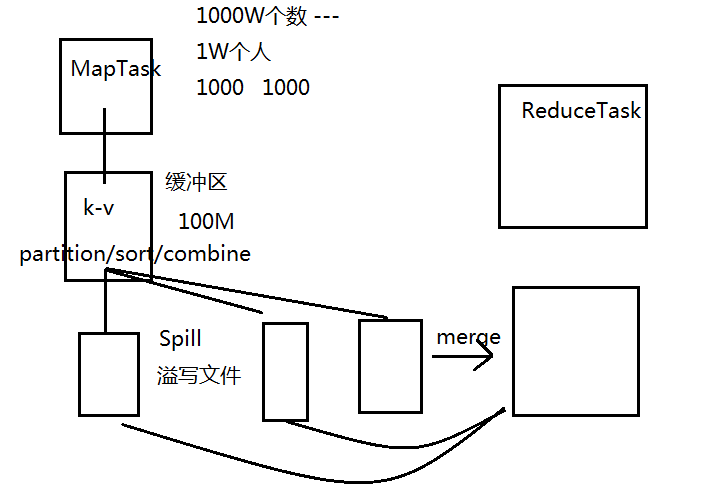
注意:
- Spill过程不一定发生
- 如果产生了Spill过程,且最后一次的数据不足阈值,将最后一次的缓冲区中的数据flush到最后一个溢写文件中
- 切片的大小和溢写文件的个数不是对等的
- 达到缓冲区的80%的时候会Spill到溢写文件中,理论上Spill文件应该是80M,实际上溢写文件一定是80M么?--- 不一定 ①要考虑最后一次的flush;②要考虑序列化的因素
- 如果溢写文件的个数>=3个,在merge的时候会再进行一次combine过程
- 每一个MapTask对应一个缓冲区
- 缓冲区本质上是一个字节数组
- 缓冲区是一个环形缓冲区,为了重复利用缓冲区
- 阈值的作用:①防止数据覆盖②防止写入过程的阻塞
ReduceTask
- ReduceTask通过http请求来访问对应的MapTask获取到分区的数据 --- fetch - fetch线程数量默认是5
- 获取到不同的MapTask的数据之后,会对数据进行merge,将数据合并(将相同的键所对应的值放入一个迭代器中)且排序(根据键进行排序)
- 每一个键调用一次reduce方法来进行处理
- 将处理之后的数据写到HDFS中
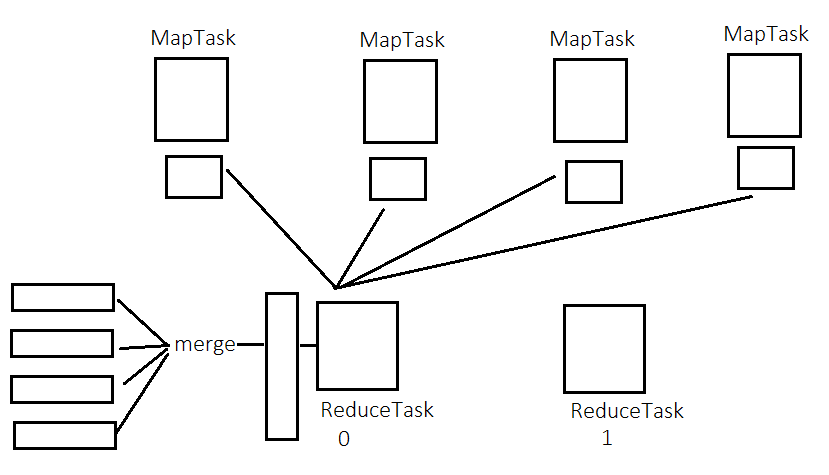
注意:
- merge因子:确定每次将几个文件合并一次。默认是10。如果文件个数<merge因子,直接合并
- ReduceTask的阈值:ReduceTask不是等所有的MapTask都结束之后才启动执行,而是在一定数量的MapTask结束之后就开始启动抓取数据。--- 5% --- 当5%的数量的MapTask结束之后,ReduceTask就开始启动抓取数据
调优
- 可以调大缓冲区,一般建议是250~400M之间
- 可以适当的增加combine过程
- 在map过程中会产生一个最后merge好的文件,通过网络发送给ReduceTask --- 可以将文件进行压缩,压缩之后再发送 --- 如果网络带宽比较稀缺,这个时候可以考虑压缩
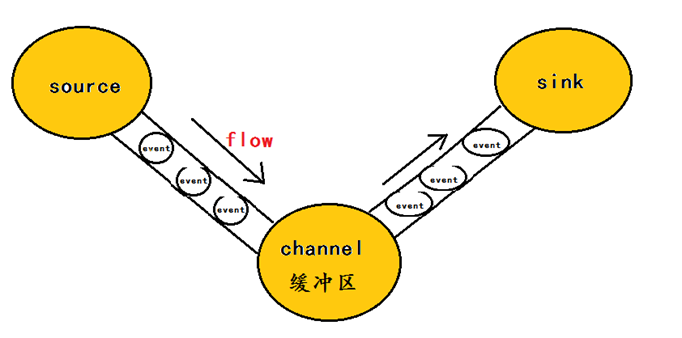
8.flume的基本组件机制
flume运行的核心就是agent,agent本身是一个Java进程,
agent里面包含3个核心的组件:source—->channel—–>sink,类似生产者、仓库、消费者的架构。
source:source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义。
channel:source组件把数据收集来以后,临时存放在channel中,即channel组件在agent中是专门用来存放临时数据的——对采集到的数据进行简单的缓存,可以存放在memory、jdbc、file等等。
sink:sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义。
一个完整的工作流程:source不断的接收数据,将数据封装成一个一个的event,然后将event发送给channel,chanel作为一个缓冲区会临时存放这些event数据,随后sink会将channel中的event数据发送到指定的地方—-例如HDFS等。
注:只有在sink将channel中的数据成功发送出去之后,channel才会将临时event数据进行删除,这种机制保证了数据传输的可靠性与安全性。
9.Zookeeper的特点
- 本身是一个树状结构 --- Znode树
- 每一个节点称之为znode节点
- 根节点是 /
- Zookeeper的所有操作都必须以根节点为基准进行计算 /
- 每一个znode节点都必须存储数据
- 任意一个持久节点都可以有子节点
- 任意一个节点的路径都是唯一的
- Znode树是维系在内存中 --- 目的是为了快速查询
- Zookeeper不适合存储海量数据。原因:1)维系在内存中,如果存储大量数据会耗费内存 2) 不是一个存储框架而是一个服务协调框架
- Zookeeper会为每一次事务(除了读取以外的所有操作都是事务)分配一个全局的事务id ---Zxid
10.读写锁机制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号