



解释器内置的模块优先级比自己定义的高,比如time。
sys修改环境变量:sys.path.append() 临时修改环境变量 想永久还是得上系统属性中去改
import sys,os
BADE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR)
以上操作解决了导入与bin同级的my_module文件夹内模块的问题。
os模块
os.getcwd()获取当前工作目录
os.chdir('test1')在当前工作目录下建了一个test1文件夹,这样输会转移到test1文件夹内,如果括号内是..则后退到上一级目录
os.mkdir('dirname')生成单级目录
os.rmdir('dirname')删除单级目录,空才能删
os.makedirs('dirname1/dirname2')可生成递归目录,前者包括后者
os.removedirs()若括号内目录为空,则删除,并递归到上一级目录,如空再删,直到非空停
os.remove()删除一个文件
os.environ获取系统环境变量
os.listdir('dirname')列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.rename('oldname','newname')重命名文件/目录
os.stat()指定文件的相关信息的介绍 st_atime是查看时间 mtime是修改时间 ctime是创建时间
os.sep输出操作系统特定的路径分隔符(Win下'\\' Linux下'/')
os.linesep输出当前平台使用的行终止符(Win下为'\r\n' Linux下'\n')
os.pathsep输出用于分割文件路径的字符串(Win下为; Linux下:)
os.name输出字符串指示当前使用平台(Win下为'nt' Linux下'posix')
os.system('base command')运行shell命令,直接显示
os.path.abspath(path)返回path规范化的绝对路径
os.path.split(path)将path分割成目录和文件名二元组返回('...','...')
os.path.dirname(path)返回path的目录
os.path.basename(path)取文件名
os.path.exists(path)判断path存在与否,返回True或False
isabs绝对路径 isfile文件 isdir目录
os.path.join(a,b)路径拼接
os.path.getatime getctime getmtime 文件的最近访问 + 属性修改 + 内容修改时间
sys模块
sys.path返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.exit(n)退出程序,正常退出时exit(0)
sys.argv提前输入命令用
sys.stdout.write()写存入缓存,全写完才显示
用于数据传送的模块
json模块(不同语言间)
json.dumps()加载成字符串,引号全变双引号 序列化:把对象(变量)从内存中编程可存储或传输的过程
json.dump(dic,f) 相当于上条命令加上write
json.loads()还原成原数据类型 反序列化
json.load(f)等价于data=json.loads(f.read())
pickle模块(python之间,支持的数据类型更多)
pickle.dumps()加载成字节,文件打开要用b模式
dump
pickle.loads()
load
shelve模块
f=shelve.open(r'shelve1')将一个字典放入文本 f={} f['stu1_info']={'name':'alex','age':'18'} print(f.get('stu1_info')['age']) f.close()
xml模块
(出现的比json早,用的比较多)

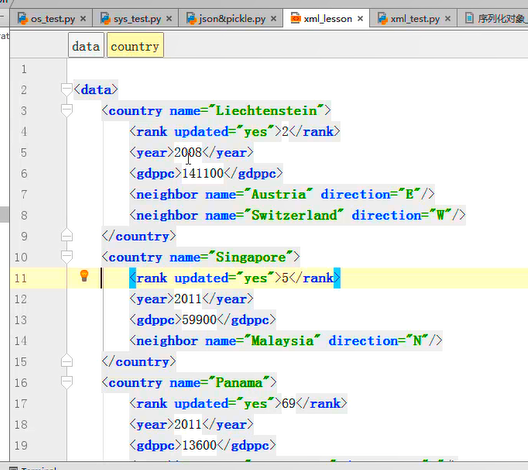
(上两图(文档树):标签语言(所有语法通过标签实现);自闭合标签&非自闭合标签(有头有尾))
xml数据操作
import xml.etree.ElementTree as ET
tag标签名称
tree=ET.parse('xml_lesson')#解析xml文档
root=tree.getroot()
print(root.tag)#获取根节点标签名称
for i in root:#i即子对象地址
for j in i:#再遍历下面分支
print(j.tag)#打印分支的标签名称
attrib标签属性
text拿非自闭合标签包裹的文本内容
只遍历year节点
for node in root.iter('year'):
print(node.tag,node.text)
修改node
for node in root.iter('year'):
new_year=int(node.text)+1
node.text=str(new_year)
node.set('updated','yes')#属性增加
tree.write('xml_lesson')
删除node
for country in root.findall('country'): #findall能找多个
rank=int(country.find('rank').text)
if rank>50:
root.remove(country)
tree.write('output.xml') #可以新写个文件,也可以覆盖
创建xml数据
import xml.etree.ElementTree as ET
new_xml=ET.Element('namelist')#创建名为'namelist'的根节点标签
name=ET.SubElement(new_xml,'name',attrib={'enrolled':'yes'})
age=ET.SubElement(name,'age',attrib={'checked':'no'})
sex=ET.SubElement(name,'sex')
sex.text='33'
name2=ET.SubElement(new_xml,'name',attrib={'enrolled':'no'})
age=ET.SubElement(name2,'age')
age.text='19'
et=ET.ElementTree(new_xml)#生成文档对象
et.write('test.xml',encoding='utf-8',xml_declaration=True)
#ET.dump(new_xml)#打印生成的格式
re模块(给字符串实现模糊匹配)
正则表达式(或RE)是一个小型的高度专业化的编程语言(面向字符串),内嵌在Python中,并通过re模块实现。正则表达式模式被编译成一系列字节码,然后由用C编写的匹配引擎执行(效率高,速度快)。
字符匹配(普通字符、元字符)
普通字符:大多数字符和字母都会和自身匹配
>>re.findall("alex","hjaksdfhalex")
['alex8']
元字符:.$^*()+[]{}\|?(共11个)
①元字符.点号
通配符除了'\n'都行 一个点对应一个
②元字符^尖角号 ③元字符$dollar
^必须在字符串开头开始匹配,尖角号前面不能加通配符
$从字符串最后往前匹配
贪婪匹配* + ? ④元字符*星号(前面的字符个数:0到无穷次) ⑤元字符+加号(前字符数:1到无穷次) ⑥元字符?问号(前字符可匹配0或1次)
* + ?都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
⑦元字符{}大括号({0,}==* {1,}==+ {0,1}==? {6}匹配六次 {1,6}匹配1到6次)
⑧元字符[]中括号 学名:字符集。中括号里面必须且只能取一个字符匹配;元字符里面没有特殊符号;[a-z]其中-代表范围(按ASCII码排的),这里即包括a到z的26个小写字母;[^a-z]不是a-z的都能匹配;字符集里特殊的包括- ^ \;特殊的\
⑨元字符\反斜杠(把有意义的字符变成没意义的,没意义变有意义)
正斜杠(forward slash'/')和反斜杠(back slash'\')
python解释器有一套转义规则,re有一套,在python解释器中运行的时候,解释器预先会对转义做翻译。
r""r表示不让解释器对字符串进行转义 例如:re.findall(r'I\b')即re.findall('I\\b') 其中\\被python解释器翻译成字符\ 而"c\\\\l" ---> "c\\l"

⑩元字符|管道符 取或
⑪元字符()圆括号 分组 例如print(re.search("(?P<name>[a-z]+)(?P<age>\d+)","alex36wusir34xialv33").group("name")) 输出'alex' 如果group内是"age"则输出'36' 再例如print(re.findall"(abc)+","abcabcabc")输出['abc'] 而取消优先显示组内内容后print(re.findall"(?:abc)+","abcabcabc")输出['abcabcabc']
search返回的是一个对象(找到的第一个),没找到则什么都不返回,在后面加.group()返回找到的值(字符串形式)
match(相当于search内加^)从头开始匹配,返回一个对象,如果没有则不返回,相当于search的特殊情况,也可以加.group()返回值
split分割,比字符串那个功能强大 例如:print(re.split("[ |]","hello abc|def"))输出['hello','abc','def'] 再例如:print(re.split("[ab]","asdabcd"))输出[' ','sd',' ','cd'](以分割符为中介左边一个右边一个,没有则为空,依次分下去)
sub替换 print(re.sub("\d","A","jask4235ashdjf5423",4))输出'jaskAAAAashdjf5423'
subn替换加显示次数 print(re.subn("\d","A","jask4235ashdjf5423"))输出('jaskAAAAashdjfAAAA',8)
compile编译,只有一个参数,就是规则,使用多次的时候效率体现出来了 例如com=re.compile("\d+") print(com.findall("jask4235ashdjf5423"))输出['4235','5423']
finditer返回迭代器对象,数据大的时候有用 例如:ret=re.finditer("\d","sdfgs6345dkflfdg534jd") print(next(ret).group())输出6 print(next(ret).group())输出3
需要注意下面这种情况:
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 print(re.findall("www\.(baidu|163)\.com","sdfsadfwww.baidu.com")) #优先级在组,只输出组里信息 4 print(re.findall("www\.(?:baidu|163)\.com","sdfsadfwww.baidu.com")) #去除组优先级,信息全输出
logging模块
日志级别

basicConfig
logging.basicConfig(level=logging.DEBUG,filename="logger.log",filemode='w',format="%(asctime)s %(filename)s [%(lineno)d] %(message)s") #默认等级warning以上;默认显示到屏幕上,filename设定存到的文件;filemode默认是追加;同时列出filename(写到文件)和stream(显示到屏幕)两个参数,stream参数会被忽略

logger对象——“吸星大法”
logger=logging.getLogger() #括号内写上名字是子用户;(了解)只要root用户工作,子用户就跟着工作
fh=logging.FileHandler("test_log")
ch=logging.StreamHandler()
fm=logging.Formatter("%(asctime)s %(message)s")
fh.setFormatter(fm)
ch.setFormatter(fm)
logger.addHandler(fh)
logger.addHandler(ch)
logger.setLevel("DEBUG")
logger.debug("debug")
logger.info("info")
logger.warning("warning")
logger.error("error")
logger.critical("critical")
configparser模块(配置解析)
如何生成配置文件(相当于字典)?
1 import configparser 2 3 config = configparser.ConfigParser() #config={} 4 5 config["DEFAULT"] = {'ServerAliveInterval': '45', 6 'Compression': 'yes', 7 'CompressionLevel': '9'} 8 9 config['bitbucket.org'] = {} 10 config['bitbucket.org']['User'] = 'hg' 11 12 config['topsecret.server.com'] = {} 13 topsecret = config['topsecret.server.com'] 14 topsecret['Host Port'] = '50022' # mutates the parser 15 topsecret['ForwardX11'] = 'no' # same here 16 17 with open('example.ini', 'w') as f: 18 config.write(f)
config = configparser.ConfigParser()
config.read("配置文件名")
print(config.sections()) #输出除默认外的几个块的名字
config["块名"]["键名"] #名称不区分大小写
遍历除了default块的其他信息,default块内容也会输出
config.options("...")返回键列表
config.items("..."))返回键值对元组构成的列表
config.get("块名","键名")连续取值
config.add_section("新块名")增加块
config.set("块名","键名","值")
config.remove_section("块名")删除块
config.remove_option("块名","键名")删除键值对
config.write(open("i.cfg","w"))没有文件句柄不需要关闭,增删改查之后写到文件里,可以覆盖或者建新文件,文件扩展名不固定
hashlib模块
提供的是哈希算法,摘要算法。明文变密文,不能反解。变密文之后对比。
字符串到字节一定要有编码方式。不定长的变定长,同样的数据对应的密文一样。
存在撞库问题(常用的明文密文对应),只能一定程度上解决问题,加盐后才更安全。
加密算法越复杂,效率越低。
import hashlib
obj=hashlib.md5()
obj.update("admin".encode("utf8"))
print(obj.hexdigest())
如果这里再obj.update("root".encode("utf8")),会接着"admin"来,即"adminroot",然后print(obj.hexdigest())会输出"adminroot"对应的密文

