



zip()“拉链”方法
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 print(list(zip(('a','b','c'),(1,2,3)))) 4 p={'name':'alex','age':18,'gender':'none'} 5 print(list(zip(p.keys(),p.values()))) 6 print(list(zip('hello','12345'))) 7 print(list(zip(['c','y'],'12'))) 8 #zip两个参数都是序列,序列类型包括元组、列表、字符串。
输出
[('a', 1), ('b', 2), ('c', 3)]
[('name', 'alex'), ('age', 18), ('gender', 'none')]
[('h', '1'), ('e', '2'), ('l', '3'), ('l', '4'), ('o', '5')]
[('c', '1'), ('y', '2')]
max和min高级使用
max函数处理的是可迭代对象,相当于一个for循环去除每个元素(必须是同类型的)进行比较;每个元素间进行比较是从每个元素的第一个位置依次比较,如果这一个位置分出大小,后面的就不需要比较了,直接得出这两个元素的大小。
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 age_dic={'alex_age':18,'wupeiqi_age':20,'zsc_age':100,'lhf_age':30} 4 for item in zip(age_dic.values(),age_dic.keys()): 5 print(item) 6 print(list(max(zip(age_dic.values(),age_dic.keys()))))
输出
(18, 'alex_age')
(20, 'wupeiqi_age')
(100, 'zsc_age')
(30, 'lhf_age')
[100, 'zsc_age']
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 people=[ 4 {'name':'alex','age':1000}, 5 {'name':'wupeiqi','age':10000}, 6 {'name':'yuanhao','age':9000}, 7 {'name':'linhaifeng','age':18} 8 ] 9 print(max(people,key=lambda dic:dic['age'])) #下面操作和这句等效 10 # ret=[] 11 # for item in people: 12 # ret.append(item['age']) 13 # print(ret) 14 # print(max(ret))
输出
{'name': 'wupeiqi', 'age': 10000}
内置函数(续)
ord()字符转ASCII码
pow()两个参数时表示第一参数的第二参数次方;三个参数的时候表示次方结果对第三参数取余。
reversed()对列表进行反转
slice()切片 如s=slice(1,4,2),则s.start为1,s.stop为4,s.step为2。
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 l='hello' 4 s1=slice(3,5) 5 s2=slice(1,4,2) #第三个参数是步长 6 #print(l[3:5]) #这种是硬编码,写的越多,可读性会越来越差。 7 print(l[s1]) 8 print(l[s2])
输出
lo
el
sorted()排序,本质就是在比较大小,默认从小到大(加reverse=True的时候从大到小)
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 name_dic={ 4 'abyuanhao':11900, 5 'alex':1200, 6 'wupeiqi':300 7 } 8 print(sorted(name_dic)) 9 print(sorted(name_dic,key=lambda key:name_dic[key])) 10 print(sorted(zip(name_dic.values(),name_dic.keys())))
输出
['abyuanhao', 'alex', 'wupeiqi']
['wupeiqi', 'alex', 'abyuanhao']
[(300, 'wupeiqi'), (1200, 'alex'), (11900, 'abyuanhao')]
str()
sum()
type() 另外:写程序就是处理状态的变化
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 msg='123' 4 if type(msg) is str: 5 msg=int(msg) 6 res=msg+1 7 print(res)
输出
124
vars()
#!/usr/bin/env python # -*- coding:utf-8 -*- def test(): msg='sdfasd' print(locals()) print(vars()) #vars内不加参数,表示局部变量,返回字典 test() print(vars(int)) #vars内有参数,查看某对象下所有方法,返回字典
输出
{'msg': 'sdfasd'}
{'msg': 'sdfasd'}
{'__repr__': <slot wrapper '__repr__' of 'int' objects>, '__hash__': <slot wrapper '__hash__' of 'int' objects>, ...}
__import__() # 模块就是一个py文件写了个py'test.py',import test test.say_hi() (import不能导入字符串) 想导入字符串类型,用__import__,module_name='test' m=__import__(module_name) m.say_hi() 导入一切东西到操作系统底层都变成字符串 import----->sys------>__import__()
文件操作的其他模式
文件处理流程
1.打开文件,得到文件句柄并赋值
2.通过句柄对文件进行操作
3.关闭文件
Windows操作系统下,假设当前路径下有个文件叫做陈粒,是个文本文件
f=open('陈粒',encoding='utf-8') #句柄 跟操作系统要了一个渔网,文件是个鱼 #打开的时候是解码过程
data=f.read() #渔网捞鱼
f.close() #渔网回收
print(data)
硬盘上是二进制存数据,字符串到二进制需要编码,pycharm默认编码格式utf-8
Windows系统默认编码格式是GBK
文件打开模式
r只读(默认模式,文件必须存在,不存在则抛出异常)
w只写(不可读,不存在则创建,存在则清空内容)
a追加(可读,不存在则创建,存在则只追加内容)
x只写(…存在则报错)
r+可读且可写 从文件开头开始覆盖
文件没有修改一说,只有数据覆盖。硬盘中加载到内存中在内存的操作可以有修改,但是回到硬盘上还是覆盖操作。
默认打开模式,只读 f=open('陈粒','r',encoding='utf-8')
方法
——r模式
read()一下读全部
readable()
readline()一次读一行,没行了就读空行了,一个程序中多次调用print(f.readline(),end='')是不会每次重新开始的,是接着上一次继续读,另外里面最后有个end等于空字符串是为了让程序结束之后不自动换行。
readlines()读完输出大概是['...\n','...\n','...\n','...\n','...\n']
——w模式(无论怎样都相当于新建空文档覆盖原来的东西)
写的时候得自己加换行符才能换行;文件内容只能是字符串,读文件读出的内容也全都是字符串
write() 例如f.write('1\n') f.write('2\n') f.write('3\n')
writable()
writelines() 例如f.writelines(['1\n','2\n','3\n']) 和write的例子效果一样
【with语句】
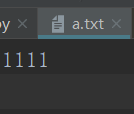
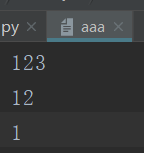
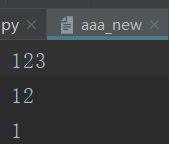
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 with open('a.txt','w')as f: 4 f.write('1111\n') 5 #文件内容覆盖另一个文件 6 with open('aaa','r',encoding='utf-8')as src_f,\ 7 open('aaa_new','w',encoding='utf-8')as dst_f: 8 data=src_f.read() 9 dst_f.write(data)
rb(底层处理的时候是二进制处理)以二进制的方式打开文件,只是文件处理的时候是二进制处理,最后显示的时候不是二进制。rb对Linux没有任何用处,因为Linux当中有个概念:一切皆文件,文件都是用二进制处理的。涉及跨平台。
文件修改操作实际是这样的:老文件中的内容读到内存中修改之后存到新文件中,最后新文件文件名覆盖原文件。

