



- expendtabs
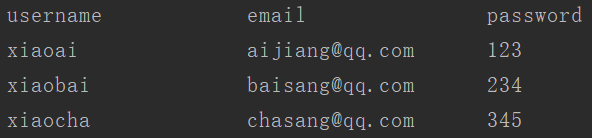
1 ... 2 t='username\temail\tpassword\nxiaoai\taijiang@qq.com\t123\nxiaobai\tbaisang@qq.com\t234\nxiaocha\tchasang@qq.com\t345' 3 w = t.expandtabs(20) #expandtabs 断句20 4 print(w)
输出
- replace
1 ... 2 t7='alexalexalex' 3 w14=t7.replace('ex','bbb') #用'bbb'替换所有的'ex' 4 w15=t7.replace('ex','bbb',1) #替换第一个 5 w16=t7.replace('ex','bbb',2) #替换前两个 6 print(w14,w15,w16)
输出
albbbalbbbalbbb albbbalexalex albbbalbbbalex
- isapha(是否字母/汉字)
- isdecimal ; - isdigit ; - isnumeric(是否数字)
范围:- isnumeric(一、①、1...) > - isdigit(①、1...) > - isdecimal(1...)
但是用的最多的还是 - isdecimal,判断标题可能用到 - isnumeric 和 -isdigit。
-isidentifier
判断是否为标识符(由字母/数字/下划线组成的,开头不能为数字的符号)
-isprintable(是否可打印,是否存在不可显示的字符('\t' ; '\n'),'\\'显示为True)
-isspace(是否全空格)
- maketrans ; - translate
1 ...
2 t4='apqiolle;arrgmiemmmc'
3 m=str.maketrans('aeiou','12345')
4 new_t4=t4.translate(m)
5 print(new_t4)
输出
1pq34ll2;1rrgm32mmmc
-istitle({英文}是否标题{所有单词首字母大写}); - 字符串变量名.title()(转化为标题)
- join
1 ... 2 t2 = '你是风儿我是沙' 3 print(t2) 4 '''u=' ' 5 w3=u.join(t2)''' 6 w3 = ' '.join(t2) #在源字符串的每个字符后加分隔符' ',最后一个字符后不加 7 print(w3)
输出
你是风儿我是沙
你 是 风 儿 我 是 沙(沙后面没元素' '了)
- ljuest ; - rjust
1 ... 2 w4=t2.ljust(20,'*') 3 w5=t2.rjust(20,'*') 4 print(w4,'\n',w5)
'''test='alex'
v=test.zfill(20)
print(v)''' # - zfill 左填0 rjust包括其功能,可忽略它
输出
你是风儿我是沙*************
*************你是风儿我是沙
'''0000000000000000alex'''
- islower ; - lower ; - isupper ; - upper(是否全部小/大写,全部转化小/大写); - swapcase(大写变小写,小写变大写)
- lstrip ; - rstrip ; - strip(左/右/两边删空白{空格、制表符、回车符};括号内写参数,删左/右/两边指定参数{包括参数的子序列})
1 ... 2 t3='xatxlex' 3 w6=t3.rstrip('9lexxexa') #有限最多匹配,先进行最多匹配
4 print(w6)
输出
xat
- partition ; - rpartition(计算器程序可用,另:正则表达式)
- split ; - rsplit ; - splitlines
1 ... 2 t5='testasdsddfg' 3 w7=t5.partition('s') #从左找第一个's'将字符串分三部分,包括's' 4 print(w7) 5 w8=t5.rpartition('s') #从右找…… 6 print(w8) 7 w9=t5.split('s') #split分割之后不包括's' 8 w10=t5.split('s',1) 9 w11=t5.split('s',2) 10 print(w9,w10,w11) 11 #分割,只能根据,True,False:是否保留换行 12 t6='asfdas\nasdasd\nsgsdfg\nsdfaf' 13 w12=t6.splitlines() #默认是False 14 w13=t6.splitlines(True) 15 print(w12,w13)
输出
('te', 's', 'tasdsddfg')
('testasd', 's', 'ddfg')
['te', 'ta', 'd', 'ddfg'] ['te', 'tasdsddfg'] ['te', 'ta', 'dsddfg']
['asfdas', 'asdasd', 'sgsdfg', 'sdfaf'] ['asfdas\n', 'asdasd\n', 'sgsdfg\n', 'sdfaf']
必记6个基本“魔法”
join
split
find
strip
upper/lower
replace
灰“魔法”
1.索引下标,获取字符串中某字符。
test='alex'
v=test[3]
print(v)
输出x
2.索引范围,获取多个字符,切片。(左闭又开)
v1=test[0:1] # 0<= <1
v2=test[0:-1] # -1表示倒数第一个字符
print(v1,v2)
输出
a
ale
3.Python3获取字符串字符个数len
v3=len(test)
print(v3)
输出4
注意:
len
for
索引
切片 [数字1:数字2]
深灰“魔法”
*字符串一旦创建就不可修改,一旦修改或者拼接,都会重新生成字符串*
range用法
创建连续的数字:例如range(0,100),在Python2.7中会直接生成0,1,2...,99这100个数,会一下占用很多内存,而在Python3中会输出range(0,100),在内存中还未创建。
创建不连续的数字:设置步长,例如range(0,100,5)

