

文档
概述
文档是MongoDB的核心概念,是数据的基本单元,非常类似于关系数据库中的行。在MongoDB中,文档表示为键值对的一个有序集。MongoDB使用Javascript shell,文档的表示一般使用Javascript里面的对象的样式来标记,如下:
1 {"title":"hello!"} 2 {"title":"hello!","recommend":5} 3 {"title":"hello!","recommend":5,"author":{"firstname":"paul","lastname":"frank"}}
从上面的例子可以看到,文档的值有不同的数据类型,甚至可以是一个完整的内嵌文档(最后一个示例的author是有一个完整的文档表示的,文档里面定义了firstname和lastname。当然还可以包含更多其他信息甚至于在内嵌文档中还可以有内嵌文档)。
说明
文档区分大小写和数据类型,所以以下两组文档是不同的:
1 {"recommend":"5"} 2 {"recommend":5} 3 4 {"Recommend":"5"} 5 {"recommend":"5"}
MongoDB的文档不能有重复的键。下面的文档是非法的:
1 {"title":"hello!","title":"Mongo"}
操作
创建
创建文档非常简单,通过插入语句就能向数据库中创建一个文档记录。
1 > db.blogs.insert({"title":"hello!"})
如果在执行这条语句之前,数据库和blogs集合并没有创建,会分别创建数据库和集合,同时插入文档。
删除
1 > db.blogs.remove() // 删除集合中所有文档。 2 > db.blogs.remove({"title":"hello!"}) // 删除指定条件的文档,当前语句删除"title"为"hello!"的文档。
集合
集合是一组文档的集,相当于关系型数据库中的数据表。
动态模式
集合是动态模式的。什么意思呢?具体来说就是一个集合里面的文档可以是各式各样的。举例来说,下面的两种文档完全可以存储在同一个集合里面:
1 {"title":"hello!"} 2 {"recommend":5}
可以看出,上面两个文档不仅值得类型不同,连键也完全不一样。这和关系型数据库中一个表中只能存放相同模型的数据结构显得很不一样。但是这也就产生了一个问题:既然一个集合中可以存放任意的文档,那么多个集合的存在还有什么必要性呢?这其实可以和关系型数据表可以对应起来理解,我们可以创建一张表容纳下上面提到的title和recommend列,但是总有一个列是NULL的。这还仅仅是两个列的情况,如果出现无数的列,那么这种情况就非常糟糕了。所以不难想出一个数据库中存在多个集合的原因应该至少有如下几点:
-
数据混乱。开发人员要区分每次查询只返回特定类型的文档,或者把这个区分交给处理查询结果的应用程序来处理。这对于开发和维护来说都会带来很大的麻烦。
-
性能。分别在不同的集合上查询要比在一个集合中去查询不同数据快得多。
-
数据更集中。同种类型的文档放在一个集合里,数据更加集中,查询数据时。需要的磁盘寻道操作更少,效率更高。
-
更高效的利用索引。索引是按照集合来定义的。创建索引时,需要使用文档的附加结构。在一个集合中只放入一种类型的文档,可以更有效的对集合进行索引。
常用命令
-
show collections 查看当前数据库中存在哪些集合,将展示集合的名称列表。如下图所示:
-
help() 获取集合上的可执行命令的列表。执行语句如下:
1 db.users.help() -
insert(obj) 向集合中插入一个文档。
-
drop() 删除当前集合,删除之后不可恢复。
-
dropIndex(index) 删除集合上的索引,参数为空时,删除所有索引(除了_id上的索引)
-
ensureIndex(keypattern[,options]) 创建索引
-
update(query,object[,upsert_bool,multi_bool]) 更新集合中满足条件的文档
-
find([query,fields]) 根据条件查询满足条件的文档
当然还有很多命令在这里没有列出,但是可以通过help()命令轻松的查看能在集合上执行的命令。
数据库
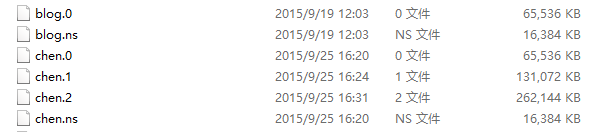
多个文档构成集合,多个集合组成数据库。一个MongoDB实例可以承载多个数据库,每个数据库可以拥有0到多个集合。下图所示是我的机器上用到的数据库的本地文件:
说明
-
每个数据库有相应的数据文件和命名空间文件。文件的前缀是数据库的名称,后缀.ns表示命名空间文件,后缀以.0、.1等数字结尾的,表示数据文件。
-
数据文件的大小从64MB开始(这是在64位Windows Server 2012上看到的结果,其他环境可能有些差异),新的数据文件比上一个文件大一倍。所以能看到,chen.0的大小是64MB,chen.1的大小是128MB,chen.2是256MB。
-
文件使用MMAP进行内存映射,会将所有的数据文件映射到内存中,但是只是虚拟内存,只有访问到这块数据时才会交换到物力内存中。
-
每个数据文件会被分成一个一个的数据块,块与块之间用双向链表链接。
-
在命名空间文件中,保存了每个命名空间的存储信息元数据,包括其大小、块数、第一块的位置、最后一块的位置、被删除的块的链表以及索引信息。
常用命令
-
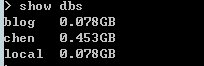
show dbs 查看当前MongoDB实例中存在的数据库,展示数据库名称列表和数据库占用的磁盘空间大小。如下图所示:
-
db 检验当前正在使用哪个数据库。如下图所示:

-
use xxx 切换当前使用的数据库。当use一个不存在的数据库的时候,不会立刻创建数据库的数据文件和命名空间文件,而是会在第一次向数据库中插入一个文件的时候才去创建对应的数据库。在这一点上,集合也有类似的特性。
-
db.dropDatabase() 删除当前使用的数据库。在删除当前使用的数据库之后,db任然指向被删除的那个数据库名称,可以通过use切换;如果不切换就做数据插入操作,会重新建立相同名字的一个数据库,但是已经不是原来的数据库了,尽管有相同的名称,也有可能有相同的集合和文档。
参考资料:
https://docs.mongodb.org/manual/
《MongoDB权威指南》(第二版)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号