
1.模块&包(* * * * *)
1.模块(modue)的概念:
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就称之为一个模块(Module)。
使用模块有什么好处?
最大的好处是大大提高了代码的可维护性。
其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
所以,模块一共三种:
- python标准库
- 第三方模块
- 应用程序自定义模块
另外,使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。
2.模块导入方法
1 import 语句
1 import module1[, module2[,... moduleN]
当我们使用import语句的时候,Python解释器是怎样找到对应的文件的呢?答案就是解释器有自己的搜索路径,存在sys.path里。
1 ['', '/usr/lib/python3.4', '/usr/lib/python3.4/plat-x86_64-linux-gnu', 2 '/usr/lib/python3.4/lib-dynload', '/usr/local/lib/python3.4/dist-packages', '/usr/lib/python3/dist-packages']
因此若像我一样在当前目录下存在与要引入模块同名的文件,就会把要引入的模块屏蔽掉。
2 from…import 语句
1 from modname import name1[, name2[, ... nameN]]
这个声明不会把整个modulename模块导入到当前的命名空间中,只会将它里面的name1或name2单个引入到执行这个声明的模块的全局符号表。
3 From…import* 语句
1 from modname import *
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。大多数情况, Python程序员不使用这种方法,因为引入的其它来源的命名,很可能覆盖了已有的定义。
4 运行本质
#1 import test #2 from test import add
无论1还是2,首先通过sys.path找到test.py,然后执行test脚本(全部执行),区别是1会将test这个变量名加载到名字空间,而2只会将add这个变量名加载进来。
包(package)
如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。
举个例子,一个abc.py的文件就是一个名字叫abc的模块,一个xyz.py的文件就是一个名字叫xyz的模块。
现在,假设我们的abc和xyz这两个模块名字与其他模块冲突了,于是我们可以通过包来组织模块,避免冲突。方法是选择一个顶层包名:

引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突。现在,view.py模块的名字就变成了hello_django.app01.views,类似的,manage.py的模块名则是hello_django.manage。
请注意,每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录(文件夹),而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是对应包的名字。
调用包就是执行包下的__init__.py文件
注意点(important)
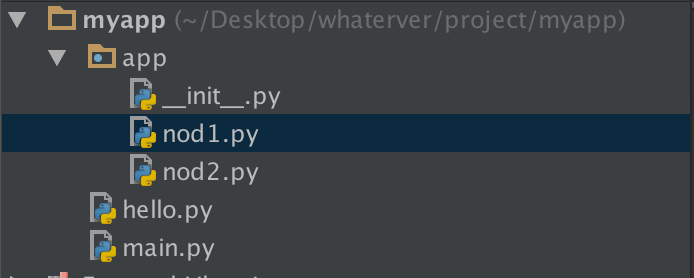
1--------------
在nod1里import hello是找不到的,有同学说可以找到呀,那是因为你的pycharm为你把myapp这一层路径加入到了sys.path里面,所以可以找到,然而程序一旦在命令行运行,则报错。有同学问那怎么办?简单啊,自己把这个路径加进去不就OK啦:
1 import sys,os 2 BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) 3 sys.path.append(BASE_DIR) 4 import hello 5 hello.hello1()
2 --------------
1 if __name__=='__main__': 2 print('ok')
输出:
ok
“Make a .py both importable and executable”
如果我们是直接执行某个.py文件的时候,该文件中那么”__name__ == '__main__'“是True,但是我们如果从另外一个.py文件通过import导入该文件的时候,这时__name__的值就是我们这个py文件的名字而不是__main__。
这个功能还有一个用处:调试代码的时候,在”if __name__ == '__main__'“中加入一些我们的调试代码,我们可以让外部模块调用的时候不执行我们的调试代码,但是如果我们想排查问题的时候,直接执行该模块文件,调试代码能够正常运行!s
3 --------------

1 ##-------------cal.py 2 def add(x,y): 3 4 return x+y 5 ##-------------main.py 6 import cal #from module import cal 7 8 def main(): 9 10 cal.add(1,2) 11 12 ##--------------bin.py 13 from module import main 14 15 main.main()
注意:
# from module import cal 改成 from . import cal同样可以,这是因为bin.py是我们的执行脚本, # sys.path里有bin.py的当前环境。即/Users/yuanhao/Desktop/whaterver/project/web这层路径, # 无论import what , 解释器都会按这个路径找。所以当执行到main.py时,import cal会找不到,因为 # sys.path里没有/Users/yuanhao/Desktop/whaterver/project/web/module这个路径,而 # from module/. import cal 时,解释器就可以找到了。
2.time模块(* * * *)
三种时间表示
在Python中,通常有这几种方式来表示时间:
- 时间戳(timestamp) : 通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
- 格式化的时间字符串
- 元组(struct_time) : struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
1 mport time 2 3 # 1 time() :返回当前时间的时间戳 4 time.time() #1473525444.037215 5 6 #---------------------------------------------------------- 7 8 # 2 localtime([secs]) 9 # 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。 10 time.localtime() #time.struct_time(tm_year=2016, tm_mon=9, tm_mday=11, tm_hour=0, 11 # tm_min=38, tm_sec=39, tm_wday=6, tm_yday=255, tm_isdst=0) 12 time.localtime(1473525444.037215) 13 14 #---------------------------------------------------------- 15 16 # 3 gmtime([secs]) 和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。 17 18 #---------------------------------------------------------- 19 20 # 4 mktime(t) : 将一个struct_time转化为时间戳。 21 print(time.mktime(time.localtime()))#1473525749.0 22 23 #---------------------------------------------------------- 24 25 # 5 asctime([t]) : 把一个表示时间的元组或者struct_time表示为这种形式:'Sun Jun 20 23:21:05 1993'。 26 # 如果没有参数,将会将time.localtime()作为参数传入。 27 print(time.asctime())#Sun Sep 11 00:43:43 2016 28 29 #---------------------------------------------------------- 30 31 # 6 ctime([secs]) : 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为 32 # None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。 33 print(time.ctime()) # Sun Sep 11 00:46:38 2016 34 35 print(time.ctime(time.time())) # Sun Sep 11 00:46:38 2016 36 37 # 7 strftime(format[, t]) : 把一个代表时间的元组或者struct_time(如由time.localtime()和 38 # time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。如果元组中任何一个 39 # 元素越界,ValueError的错误将会被抛出。 40 print(time.strftime("%Y-%m-%d %X", time.localtime()))#2016-09-11 00:49:56 41 42 # 8 time.strptime(string[, format]) 43 # 把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。 44 print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X')) 45 46 #time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6, 47 # tm_wday=3, tm_yday=125, tm_isdst=-1) 48 49 #在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。 50 51 52 # 9 sleep(secs) 53 # 线程推迟指定的时间运行,单位为秒。 54 55 # 10 clock() 56 # 这个需要注意,在不同的系统上含义不同。在UNIX系统上,它返回的是“进程时间”,它是用秒表示的浮点数(时间戳)。 57 # 而在WINDOWS中,第一次调用,返回的是进程运行的实际时间。而第二次之后的调用是自第一次调用以后到现在的运行 58 # 时间,即两次时间差。
数据参考:http://www.jquerycn.cn/a_16937
https://www.cnblogs.com/mayesheng/p/5574919.html


1 help(time) 2 help(time.asctime)
3.random模块(* *)
1 import random 2 3 print(random.random())#(0,1)----float 4 5 print(random.randint(1,3)) #[1,3] 6 7 print(random.randrange(1,3)) #[1,3) 8 9 print(random.choice([1,'23',[4,5]]))#23 10 11 print(random.sample([1,'23',[4,5]],2))#[[4, 5], '23'] 12 13 print(random.uniform(1,3))#1.927109612082716 14 15 16 item=[1,3,5,7,9] 17 random.shuffle(item) 18 print(item)
1.random.random
random.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0
2.random.uniform
random.uniform(a, b),用于生成一个指定范围内的随机符点数,两个参数其中一个是上限,一个是下限。如果a > b,则生成的随机数n: a <= n <= b。如果 a <b, 则 b <= n <= a
print random.uniform(10, 20) print random.uniform(20, 10) # 18.7356606526 # 12.5798298022
3.random.randint
random.randint(a, b),用于生成一个指定范围内的整数。其中参数a是下限,参数b是上限,生成的随机数n: a <= n <= b
1 print random.randint(12, 20) # 生成的随机数 n: 12 <= n <= 20 2 print random.randint(20, 20) # 结果永远是20 3 # print random.randint(20, 10) # 该语句是错误的。下限必须小于上限
4.random.randrange
random.randrange([start], stop[, step]),从指定范围内,按指定基数递增的集合中 获取一个随机数。如:random.randrange(10, 100, 2),结果相当于从[10, 12, 14, 16, ... 96, 98]序列中获取一个随机数。random.randrange(10, 100, 2)在结果上与 random.choice(range(10, 100, 2) 等效
5.random.choice
random.choice从序列中获取一个随机元素。其函数原型为:random.choice(sequence)。参数sequence表示一个有序类型。这里要说明 一下:sequence在python不是一种特定的类型,而是泛指一系列的类型。list, tuple, 字符串都属于sequence。有关sequence可以查看python手册数据模型这一章。下面是使用choice的一些例子:
1 print random.choice("学习Python") 2 print random.choice(["JGood", "is", "a", "handsome", "boy"]) 3 print random.choice(("Tuple", "List", "Dict"))
6.random.shuffle
random.shuffle(x[, random]),用于将一个列表中的元素打乱。如:
1 p = ["Python", "is", "powerful", "simple", "and so on..."] 2 random.shuffle(p) 3 print p 4 # ['powerful', 'simple', 'is', 'Python', 'and so on...']
7.random.sample
random.sample(sequence, k),从指定序列中随机获取指定长度的片断。sample函数不会修改原有序列
1 list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 2 slice = random.sample(list, 5) # 从list中随机获取5个元素,作为一个片断返回 3 print slice 4 print list # 原有序列并没有改变
1 >>> import random 2 >>> random.randint(0,99) 3 # 21
随机选取0到100间的偶数:
1 >>> import random 2 >>> random.randrange(0, 101, 2) 3 # 42
随机浮点数:
1 >>> import random 2 >>> random.random() 3 0.85415370477785668 4 >>> random.uniform(1, 10) 5 # 5.4221167969800881
随机字符:
1 >>> import random 2 >>> random.choice('abcdefg&#%^*f') 3 # 'd'
多个字符中选取特定数量的字符:
1 >>> import random 2 random.sample('abcdefghij', 3) 3 # ['a', 'd', 'b']
多个字符中选取特定数量的字符组成新字符串:
1 >>> import random 2 >>> import string 3 >>> string.join( random.sample(['a','b','c','d','e','f','g','h','i','j'], 3) ).replace(" ","") 4 # 'fih'
随机选取字符串:
1 >>> import random 2 >>> random.choice ( ['apple', 'pear', 'peach', 'orange', 'lemon'] ) 3 # 'lemon'
洗牌:
>>> import random >>> items = [1, 2, 3, 4, 5, 6] >>> random.shuffle(items) >>> items # [3, 2, 5, 6, 4, 1]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号