首先批量操作的优点是:大大的提高查询的效率。
举个简单的例子:如果在程序中遍历来执行sql的话,这种情况就是有多少行数据就要执行多少条sql,这样导致的效率将是非常低。
如下可能需要40s
insert into USER (name,age) values ('张三','33');
insert into USER (name,age) values ('张三','33');
insert into USER (name,age) values ('张三','33');
insert into USER (name,age) values ('张三','33');
。。。
如果改成批量执行的话,如下可能只需要3s.:
insert into USER (name,age) values
('张三','33'),
('张三','33'),
('张三','33'),
...
下面将进行详细讲解用法。
==============================
批量操作包括批量插入和批量更新和批量删除:
主要是应用<foreach>来实现。
格式如:
<foreach collection="list" item="item" open="(" close=")" separator="," index="index"> #{item.xx}, #{item.xx} </foreach>
其中foreach中的包含的属性值有:
collection="list" 其中list是固定的,如果是数组就是array
item="item" 循环中每一项的别名
open="" 开始标识,比如删除in (id1,id2),open="(" close=")"
close="" 结束标识
separator="," 分隔符号
index="index" 下标值
========================================================================
批量新增:
<!-- 批量保存用户,并返回每个用户插入的ID -->
<insert id="batchSave" parameterType="java.util.List" useGeneratedKeys="true" keyProperty="id">
INSERT INTO `test`.`tb_user`(`username`, age)
VALUES
<foreach collection="list" item="item" separator=",">
(#{item.username}, #{item.age})
</foreach>
</insert>
扩展:useGeneratedKeys="true" keyProperty="id" 这两个属性的设置表示按主键自增的方式自动生成主键。
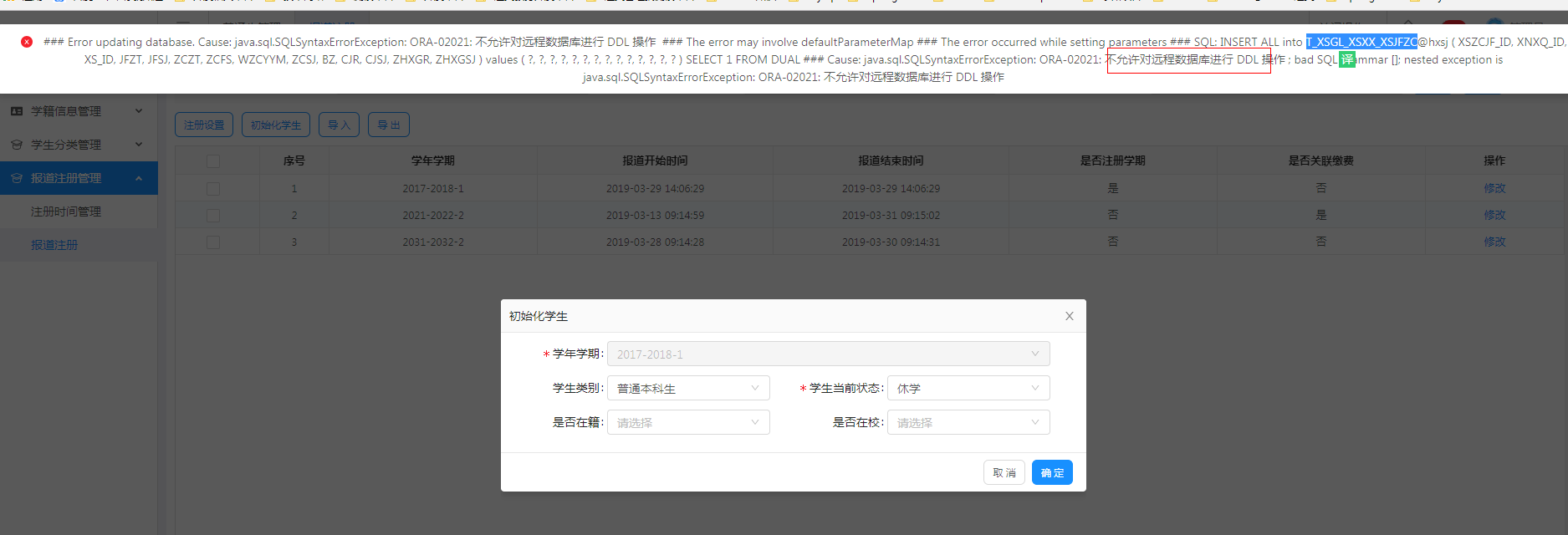
如果这种写法在Oracle不兼容的话,可以使用:
INSERT ALL
INTO A(field_1,field_2) VALUES (value_1,value_2)
INTO A(field_1,field_2) VALUES (value_3,value_4)
INTO A(field_1,field_2) VALUES (value_5,value_6)
SELECT 1 FROM DUAL;
详解:
"INSERT ALL INTO a表
VALUES(各个值)
INTO a表 VALUES (其它值)
INTO a表 VALUES(其它值) .... 再跟一个SELECT 语句"。
后边跟的SELECT 语句我们可以从虚拟表里查如 SELECT 1 FROM DUAL。注意后边跟的SELECT语句可以随意,不过不是把它SELECT出来的内容插入前边的表里,而是起到前边的多个数据每次插入多少行的作用,这个多少行是和后边跟的SELECT语句查出来几条而定的,如后边的跟的SELECT 语句查出了15条记录,那么前边的"INSERT ALL INTO a表 VALUES(各个值1) INTO a表 VALUES (其它值2) INTO a表 VALUES(其它值3)"就会先插入值1对应的各个字段插入15条记录,然后插入值2各个对应的字段15条记录,然后插入值3对应的各个字段15条记录,也就是说有点按列插入的意思。
我们要的是批量插入多个VALUES这样的一条记录,所以后边的SELECT 语句只要能查出一条记录就行,建议大家后边用SELECT 1 FROM DUAL。
实际项目中的例子有:
<!-- 批量添加添加 -->
<insert id="batchInsert">
INSERT ALL
<foreach collection="list" item="entity" separator="">
into T_JW_XKGL_XKGZXSFW
(
XKGZXSFW_ID,
XKGZ_ID,
XQ_ID,
XYH,
NJ,
ZYDL_ID,
ZY_ID,
ZYFX_ID,
SFXFZ,
SFGAT,
SFLXS,
SFYXS,
SFJHS,
XSQT,
CXB,
CJR,
CJRXM,
CJSJ
)
values (
#{entity.electiveCourseRuleStuScopeID,jdbcType=VARCHAR},
#{entity.electiveCourseRuleID,jdbcType=VARCHAR},
#{entity.campusID,jdbcType=VARCHAR},
#{entity.collegeNum,jdbcType=VARCHAR},
#{entity.grade,jdbcType=VARCHAR},
#{entity.professionBroadID,jdbcType=VARCHAR},
#{entity.professionID,jdbcType=VARCHAR},
#{entity.professionDirID,jdbcType=VARCHAR},
#{entity.creditSystem,jdbcType=VARCHAR},
#{entity.hongKongMacaoTaiwan,jdbcType=VARCHAR},
#{entity.overseasStu,jdbcType=VARCHAR},
#{entity.medicalInsuranceStu,jdbcType=VARCHAR},
#{entity.exchangeStu,jdbcType=VARCHAR},
#{entity.stuGroup,jdbcType=VARCHAR},
#{entity.innovationClazz,jdbcType=VARCHAR},
#{entity.creator,jdbcType=VARCHAR},
#{entity.creatorName,jdbcType=VARCHAR},
#{entity.createTime,jdbcType=TIMESTAMP}
)
</foreach>
SELECT 1 FROM DUAL
</insert>
======================================================
批量删除
<!-- 批量删除用户 -->
<delete id="batchDelete" parameterType="java.util.List">
DELETE FROM USER
WHERE id IN
<foreach collection="list" item="item" open="(" close=")" separator=",">
#{item}
</foreach>
</delete>
================================
第二种批量新增数据的方式:
oracle语法:
insert into tableX (a,b,c) select * from ( select 1,2,3 from dual union select 4,5,6 from dual ) t
在使用mybatis时,oracle需要写成下面格式
<foreach collection="list" item="file" index="index" separator="UNION">
实操例子有:
<insert id="batchInsertInfo" parameterType="java.util.List">
insert into XTGL_GGGL_JSFW (GGJSFW_ID, JS_ID, TZGG_ID,
CJR, CJSJ, ZHXGR,
ZHXGSJ)
<foreach close=")" collection="list" item="item" index="index"
open="(" separator="union">
select
#{item.noticeRoseScopeId,jdbcType=VARCHAR}, #{item.roseId,jdbcType=VARCHAR}, #{item.noticeId,jdbcType=VARCHAR},
#{item.creator,jdbcType=VARCHAR},
#{item.createTime,jdbcType=VARCHAR}, #{item.editor,jdbcType=VARCHAR},
#{item.editeTime,jdbcType=VARCHAR}
from dual
</foreach>
</insert>
运行通过。在Oracle的版本中,有几点需要注意的:
1.SQL中没有VALUES;
2.<foreach>标签中的(selece ..... from dual);
3.<foreach>标签中的separator的属性为"UNION ALL",将查询合并结果集。
==============================
批量更新
<update id="updateByElectiveCourseResultIds">
update T_JW_XKGL_XKJG
set xkcgbz=#{dto.successFlag,jdbcType=VARCHAR},
ZHXGR =#{dto.editor,jdbcType=VARCHAR},
ZHXGRXM =#{dto.editorName,jdbcType=VARCHAR},
ZHXGSJ =#{dto.editeTime,jdbcType=DATE}
where xkjg_id in
<foreach collection="dto.electiveCourseResultIds" index="index" item="item"
open="(" separator="," close=")">
#{item}
</foreach>
</update>
=======================
实现代码:从网上摘得一个例子(服务层得实现类下)
public void batchAddDevice(int sceneId, String list) {
List<SceneDevice> sceneDevicesList = new ArrayList<>();
Map deviceMap = new HashMap<>();
Gson gson = new Gson();
JSONArray jsonArray = JSONArray.fromObject(list);
for(int i = 0;i < jsonArray.size(); i++){
SceneDevice sceneDevice = new SceneDevice();
String jsonString = jsonArray.getString(i);
deviceMap = gson.fromJson(jsonString, deviceMap.getClass());
sceneDevice.setId(Integer.parseInt(deviceMap.get("id").toString()));
sceneDevice.setSceneId(sceneId);
sceneDevice.setDeviceId(Integer.parseInt(deviceMap.get("deviceId").toString()));
sceneDevice.setPattern(deviceMap.get("pattern").toString());
sceneDevicesList.add(sceneDevice);
}
curdRepo.batchAddDevice(sceneDevicesList);
}
其中crudRepo接口声明得方法是:
public void batchAddDevice(@Param("list") List<SceneDevice> list);
解释:
@Param("list")表示传到Mapper中得集合名字叫做list
=======================================================================
注意:批量新增不能通过dblinke进行DDL操作,不然会报错