

上传txt文件到hdfs,txt文件大小是74左右。
这里提醒一下,是不是说parquet加lzo可以把数据压缩到这个地步,因为我的测试数据存在大量重复。所以下面使用parquet和lzo的压缩效果特别好。

创建hive表,使用parquet格式存储数据
不可以将txt数据直接加载到parquet的表里面,需要创建临时的txt存储格式的表
CREATE TABLE emp_txt ( empno int, ename string, job string, mgr int, hiredate DATE, sal int, comm int, deptno int ) partitioned BY(dt string,hour string) row format delimited fields terminated by ",";
然后在创建parquet的表
CREATE TABLE emp_parquet ( empno int, ename string, job string, mgr int, hiredate DATE, sal int, comm int, deptno int ) partitioned BY(dt string,hour string) row format delimited fields terminated by "," stored as PARQUET;
加载数据
# 先将数据加载到emp_txt load data inpath '/test/data' overwrite into table emp_txt partition(dt='2020-01-01',hour='01'); #再从emp_txt将数据加载到emp_parquet里面 insert overwrite table emp_parquet select empno,ename,job,mgr,hiredate,sal,comm,deptno from emp_txt where dt='2020-01-01' AND hour='01';
可以看到这里生成了两个文件,加起来5.52M,可见大大的将原始的txt进行了压缩

下面我们使用parquet加lzo的方式,来看看数据的压缩情况
CREATE TABLE emp_parquet_lzo ( empno int, ename string, job string, mgr int, hiredate DATE, sal int, comm int, deptno int ) partitioned by (dt string,hour string) row format delimited fields terminated by "," stored as PARQUET tblproperties('parquet.compression'='lzo');
加载数据到emp_parquet_lzo
insert overwrite table emp_parquet_lzo partition (dt='2020-01-01',hour='01') select empno,ename,job,mgr,hiredate,sal,comm,deptno from emp_txt where dt='2020-01-01' AND hour='01';
数据相比较于仅仅使用parquet,数据被进一步的压缩了。但是这里提醒一下,是不是说pzrquet加lzo可以把数据压缩到这个地步,因为我的测试数据存在大量重复。

综上总结
txt文本文件,在使用parquet加压缩格式,相比较于仅仅使用parquet,可以更进一步的将数据压缩。
拓展
1.parquet压缩格式
parquet格式支持有四种压缩,分别是lzo,gzip,snappy,uncompressed,在数据量不大的情况下,四种压缩的区别也不是太大。
2.hive的分区是支持层级分区
也就是分区下面还可以有分区的,如上面的 partitioned by (dt string,hour string) 在插入数据的时候使用逗号分隔,partition(dt='2020-01-01',hour='01')
3.本次测试中,一个74M的文件,使用在insert overwrite ... select 之后,为什么会产生两个文件
首先要声明一下,我的hive使用的执行引擎是tez,替换了默认的mapreduce执行引擎。
我们看一下执行页面,这里可以看到形成了两个map,这里是map-only,一般数据的加载操作都是map-only的,所以,有多少的map,就会产生几个文件。
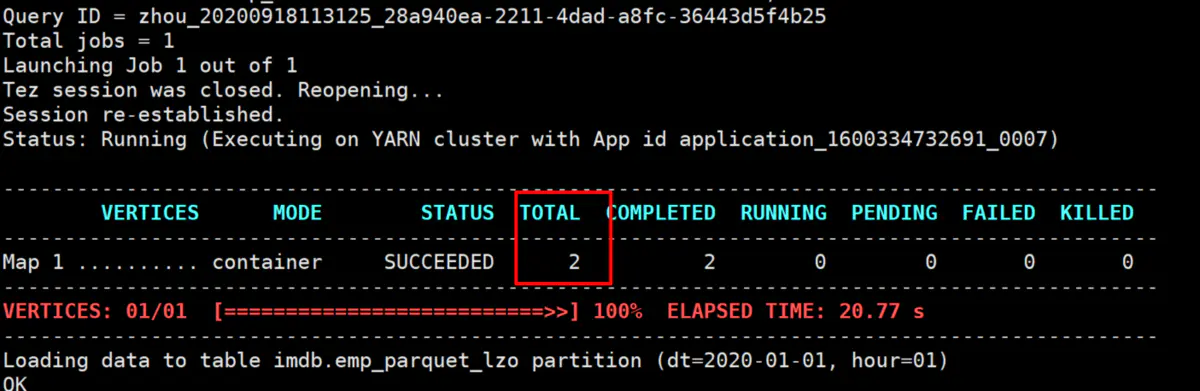
可以是hadoop的mapreduce不是128M的splitsize吗,这个文件才74M,为什么会产出两个map,这里我们看看tez的执行日志
从图片可以看出,这里是tez把74M的文件分成了两个,这里的52428800是50M,也就是这里的splitsize不是hadoop的mr的默认的128M,而是这里的50M,所以,74M的文件会被分为两个,一个是50M,一个是24M,.然后我们看上面的emp_parquet的文件,一个式3.7M,也是1.8M,正好和50M和24M的比例是对应的。
从图片可以看出,这里是tez把74M的文件分成了两个,这里的52428800是50M,也就是这里的splitsize不是hadoop的mr的默认的128M,而是这里的50M,所以,74M的文件会被分为两个,一个是50M,一个是24M,.然后我们看上面的emp_parquet的文件,一个式3.7M,也是1.8M,正好和50M和24M的比例是对应的。
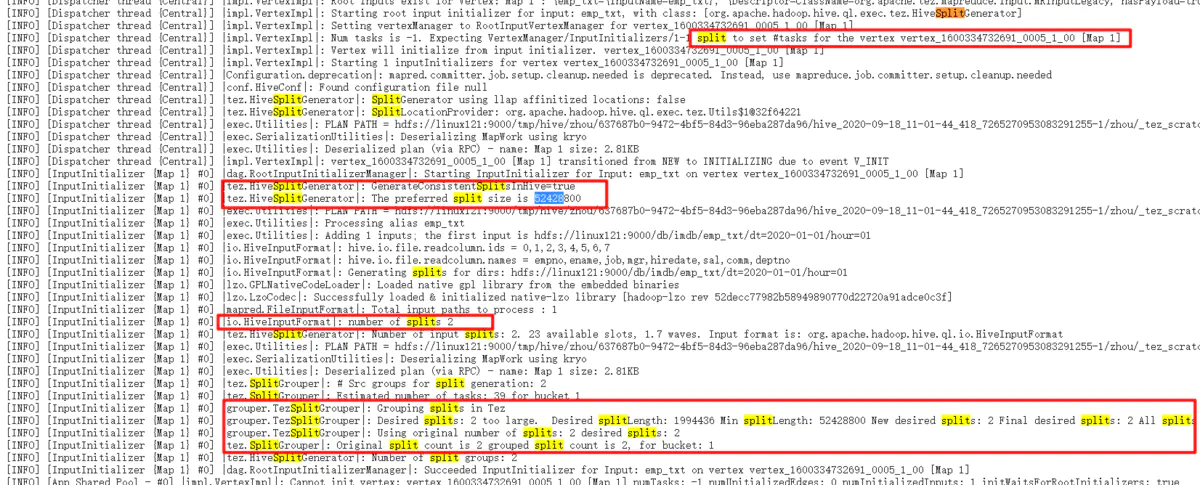
所以,一切事情都是有原因的,这里的splitsize是50M,才会导致形成两个文件的。但是我没有找到这哥tez的splitsize的具体配置是什么,以后找到的话,再进行补充。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号