
 项目调用tensorflow.keras搭建DDQN框架的智能体,其中Q值网络为简单的CNN网络,将8皇后问题的整个表格作为输入(即环境状态),下一个皇后的摆放位置为输出(即行动),最终训练出了可独立完成8皇后问题的智能体。
项目调用tensorflow.keras搭建DDQN框架的智能体,其中Q值网络为简单的CNN网络,将8皇后问题的整个表格作为输入(即环境状态),下一个皇后的摆放位置为输出(即行动),最终训练出了可独立完成8皇后问题的智能体。
程序简介
项目调用tensorflow.keras搭建DDQN框架的智能体,其中Q值网络为简单的CNN网络,将8皇后问题的整个表格作为输入(即环境状态),下一个皇后的摆放位置为输出(即行动),最终训练出了可独立完成8皇后问题的智能体。
双深度Q网络(Double Deep Q network)DQN是一种深层神经网络的算法,用来预测Q值的大小。Q值可以理解为状态动作价值,即智能体在某一状态下执行该动作所带来的预期收益。而DDQN是DQN的一种改进版本,不同点在于目标函数,DDQN通过解耦目标Q值动作的选择和目标Q值的计算这两步,来消除过度估计的问题。
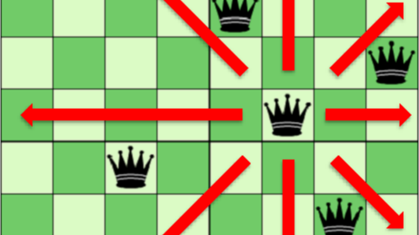
八皇后问题简单的说就是让8个棋子在8X8的网格上各占据一个位置,并且让它们各自在横、竖、斜三个方向上看不到彼此,下图是DDQN跑出的结果

程序/数据集下载

本文章只发布于博客园和爆米算法,被抄袭后可能排版错乱或下载失效,作者:爆米LiuChen
代码分析
游戏环境
八皇后的游戏环境,从空的8x8表格逐个放入皇后,并且会判断当前行为是否合规,即皇后之间是否冲突,如果可以放置,奖励为-1,若行为不合规,奖励-10,若8个皇后都成功放置,则奖励100,这里试着将第一个皇后放到第1行第1列,查看下一步游戏环境和奖励
# -*- coding: utf-8 -*-sts
from tabulate import tabulate
import pandas as pd
from copy import deepcopy
import numpy as np
import os
class ENV():
def __init__(self):
'''8皇后游戏环境'''
self.curState,self.queens = self.reset()#重置环境
def reset(self):
'''重置环境 8x8的空间 无皇后'''
self.curState = np.zeros((8,8))
self.queens = []
return self.curState,self.queens
def calQueens(self,state):
'''计算该状态下所有皇后的位置'''
positions = np.where(state==1)
quees = []
for i in range(len(positions[0])):
quees.append([positions[0][i],positions[1][i]])
return quees
def judgeValid(self,s,nextQueen):
'''判断该这一步棋子是否合规'''
valid = True
queens = self.calQueens(s)
for queen in queens:
#是否同行或同列
if (nextQueen[0] == queen[0]) or (nextQueen[1]==queen[1]):
valid = False
#是否在斜线上
if abs(nextQueen[0]-queen[0]) == abs(nextQueen[1]-queen[1]):
valid = False
return valid
def transform(self,s,a):
'''对某一环境进行行动后的下一个环境'''
nextRow = int(np.sum(s))
nextCol = a
nextQueen = [nextRow, nextCol]
s_ = deepcopy(s)
#该位置合法,可以放置
if self.judgeValid(s,nextQueen):
s_[nextQueen[0], nextQueen[1]] = 1
return s_
def play(self,a):
'''对当前环境执行一次行动'''
#查看已放置的皇后数,则下一个皇后的行就是该数
nextRow = int(np.sum(self.curState))
nextCol = a
nextQueen = [nextRow,nextCol]
s_ = self.transform(self.curState,a)
#该位置合法,可以放置
if str(s_)!=str(self.curState):
s_[nextQueen[0],nextQueen[1]] = 1
r = -1
#位置不合法
else:
r = -10
self.curState = deepcopy(s_)
# 放置了8个皇后,游戏结束
if len(self.calQueens(s_))==8:
r = 100
return s_,r
def visCurTable(self):
'''可视化当前状态'''
t = tabulate(self.curState*8, tablefmt="fancy_grid")
return t
def testModel(env,dqn):
'''对模型做一次测试'''
env = deepcopy(env)
count = 0
env.reset()
while count<=10:
count += 1
s = env.curState.copy()
a = dqn.chooseAction(s,random=False)
s_,r = env.play(a)
if r>0 and int(np.sum(s_))==8:
return 1
return 0
env = ENV()
state,r = env.play(0)
print("本次行动奖励反馈:",r)
print("下一步环境:")
print(state)
E:\Anaconda\lib\site-packages\numpy\_distributor_init.py:30: UserWarning: loaded more than 1 DLL from .libs:
E:\Anaconda\lib\site-packages\numpy\.libs\libopenblas.NOIJJG62EMASZI6NYURL6JBKM4EVBGM7.gfortran-win_amd64.dll
E:\Anaconda\lib\site-packages\numpy\.libs\libopenblas.QVLO2T66WEPI7JZ63PS3HMOHFEY472BC.gfortran-win_amd64.dll
warnings.warn("loaded more than 1 DLL from .libs:\n%s" %
本次行动奖励反馈: -1
下一步环境:
[[1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0.]]
智能体,DDQN构建
buildQvalueNet函数创建一个Q值网络,它的输入是环境矩阵,即上面的8x8矩阵,输出是1x8的行动概率矩阵,即把下一个皇后放在哪个位置
# -*- coding: utf-8 -*-
from tensorflow.keras.layers import Input,Dense,LSTM,GRU,BatchNormalization,Dropout, LSTM, BatchNormalization,Conv2D,Flatten
from tensorflow.keras.layers import PReLU,LeakyReLU
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
import tensorflow as tf
from tensorflow.keras.utils import to_categorical
import numpy as np
from tensorflow.compat.v1 import ConfigProto
from tensorflow.compat.v1 import InteractiveSession
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
def buildQvalueNet(stateShape,actionDim,nodeNum=300,lr=5e-4):
'''
搭建Q值网络
stateShape:环境尺寸
actionDim:行动维数
learnRate:学习率
'''
#输入层
inputLayer = Input(shape=stateShape)
#中间层
middle = Flatten()(inputLayer)
middle = Dense(nodeNum)(middle)
middle = PReLU()(middle)
middle = Dense(nodeNum)(middle)
middle = PReLU()(middle)
#输出层 全连接
outputLayer = Dense(actionDim)(middle)
#建模
model = Model(inputs=inputLayer,outputs=outputLayer)
optimizer = Adam(lr=lr)
model.compile(optimizer=optimizer,loss=tf.keras.losses.huber)
return model
model = buildQvalueNet((8,8),8)
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 8, 8)] 0
_________________________________________________________________
flatten (Flatten) (None, 64) 0
_________________________________________________________________
dense (Dense) (None, 300) 19500
_________________________________________________________________
p_re_lu (PReLU) (None, 300) 300
_________________________________________________________________
dense_1 (Dense) (None, 300) 90300
_________________________________________________________________
p_re_lu_1 (PReLU) (None, 300) 300
_________________________________________________________________
dense_2 (Dense) (None, 8) 2408
=================================================================
Total params: 112,808
Trainable params: 112,808
Non-trainable params: 0
_________________________________________________________________
DDQN类构建了整个DDQN的核心,内含两个Q值网络,其中targetNet是目标网络,参数滞后,evalNet是估值网络,参数保持最新,memory是记忆池字典,learn函数在更新evalNet时会从记忆池取出批量记忆进行训练
class DDQN():
def __init__(self,stateShape,actionDim,hiddenDim,gamma=0.99,batchSize=100,memorySize=1000,epsilonInit=0.8,epsilonDecay=0.9999,epsilonMin=0,lr=1e-3):
'''DDQN网络,入参的含义直接见下文'''
self.stateShape = stateShape
self.actionDim = actionDim#行动维数
self.hiddenDim = hiddenDim#隐藏层节点数
self.batchSize = batchSize#记忆库批学习量
self.memorySize = memorySize#记忆库大小
self.epsilonInit = epsilonInit#初始探索率
self.epsilonDecay = epsilonDecay#探索递减率 0.998^1000 = 0.135
self.epsilonMin = epsilonMin#最低探索率
self.gamma = gamma#奖励值衰减 奖励会乘以该数
self.actCount = 0#互动次数
self.memory = {"state":[],"action":[],"reward":[],"state_":[],"flag":[]}
#q值网络
self.targetNet = buildQvalueNet(stateShape=stateShape,actionDim=actionDim,nodeNum=hiddenDim,lr=lr)
self.evalNet = buildQvalueNet(stateShape=stateShape,actionDim=actionDim,nodeNum=hiddenDim,lr=lr)
def saveModel(self,path):
'''保存模型'''
self.evalNet.save_weights(path)
def loadModel(self,path):
'''加载模型'''
self.evalNet.load_weights(path)
def updateTargetNet(self):
'''将估计网络权重更新到目标网络'''
self.targetNet.set_weights(self.evalNet.get_weights())
@property
def epsilon(self):
'''计算当前的探索率'''
epsilon = max(self.epsilonMin,self.epsilonInit*(self.epsilonDecay**self.actCount))
return epsilon
@property
def judgeEpsilon(self):
'''判断是否采取探索策略'''
if np.random.random()<self.epsilon:
return True
else:
return False
def chooseAction(self,state,random=False):
'''选择行为'''
# 采样均衡
flags = []
for a in range(self.actionDim):
a = np.array(a).reshape(-1)
s = np.array(state).reshape(-1,self.stateShape[0],self.stateShape[1],self.stateShape[2])
flag = str(s)+"_"+str(a)
flags.append(flag)
if len(state.shape)<4:
state = state[np.newaxis,:]
if ((not self.judgeEpsilon) and random) or (not random):
values = self.evalNet.predict(state)
action = np.argmax(values,axis=-1)[0]
else:
values = np.random.uniform(0.1,1,self.actionDim)
for i,flag in enumerate(flags):
if flag in self.memory["flag"]:
values[i] = 1e-10
action = np.argmax(values,axis=-1)
self.actCount += state.shape[0]
return action
def saveMemory(self, s, a ,r,s_):
'''存储记忆'''
s = np.array(s).reshape(-1,self.stateShape[0],self.stateShape[1],self.stateShape[2])
a = np.array(a).reshape(-1)
r = np.array(r).reshape(-1)
if s_ is not None:
s_ = np.array(s_).reshape(-1, self.stateShape[0], self.stateShape[1], self.stateShape[2])
flag = str(s) + "_" + str(a)
self.memory["state"].append(s)
self.memory["action"].append(a)
self.memory["reward"].append(r)
self.memory["state_"].append(s_)
self.memory["flag"].append(flag)
self.memory["state"] = self.memory["state"][-1*self.memorySize:]
self.memory["action"] = self.memory["action"][-1*self.memorySize:]
self.memory["reward"] = self.memory["reward"][-1*self.memorySize:]
self.memory["state_"] = self.memory["state_"][-1 * self.memorySize:]
self.memory["flag"] = self.memory["flag"][-1 * self.memorySize:]
@property
def batchMemory(self):
'''批量记忆'''
#需要取出的样本量
sampleSize = min(len(self.memory["state"]),self.batchSize)
#取出记忆
indices = np.random.choice(len(self.memory["state"]), size=sampleSize,replace=False)
states = [self.memory["state"][i] for i in indices]
actions = [self.memory["action"][i] for i in indices]
rewards = [self.memory["reward"][i] for i in indices]
states_ = [self.memory["state_"][i] for i in indices]
return states,actions,rewards,states_
def learn(self):
'''训练模型'''
#取出批量样本
states, actions, rewards,states_ = self.batchMemory
states = np.concatenate(states,axis=0)
actions = np.concatenate(actions,axis=0).reshape(-1,1)
qTarget = []
for i,s_ in enumerate(states_):
s = states[i:i+1]
reward = rewards[i]
action = actions[i]
evaluate = self.evalNet.predict(s)[0]
if s_ is not None:
nextAction = np.argmax(self.evalNet.predict(s_)[0])
target = self.targetNet.predict(s_)[0]
evaluate[action] = reward + self.gamma*target[nextAction]
else:
evaluate[action] = reward
qTarget.append(evaluate)
qTarget = np.stack(qTarget,axis=0)
loss = self.evalNet.fit(states, qTarget, epochs=1, verbose=0, batch_size=500).history["loss"]
#qMean = np.mean(self.evalNet.predict(states))
loss = np.mean(loss)
#self.updateTargetNet()
return loss
实例化游戏环境、DDQN
开始训练,同时对每一轮游戏进行测试,测试通过则终止训练,下面日志中,eps为探索率,loss是训练损失,step是总交互次数,r是该轮游戏的平均奖励,success是游戏总通关次数,test是该轮游戏后网络的测试是否通过
# 初始化 迷宫
env = ENV()
# 实例化DQN
stateShape = (8, 8, 1) # 周围环境尺寸
hiddenDim = 200 # 隐藏层节点数
actionDim = 8 # 行动空间大小
dqn = DDQN(stateShape=stateShape, hiddenDim=hiddenDim, actionDim=actionDim, memorySize=100000, batchSize=50,
epsilonInit=1, epsilonDecay=0.9995, epsilonMin=0.1,lr=1e-3)
history = {"step": [], "epsilon": [], "loss": [], "reward": [], "success": []}
rewardList = list() # 奖励记录
step = 0#总共交互次数
count = 0#每回合最高100次交互
success = 0
while True:
step += 1
count += 1
s = env.curState.copy()
a = dqn.chooseAction(s, random=True) # 选择行动
s_, r = env.play(a) # 下一步的环境 奖励
rewardList.append(r)
# 到达终点
if int(np.sum(s_))==8:
success += 1
s_ = None
env.reset()
count = 0
if count >= 64:
env.reset()
count = 0
dqn.saveMemory(s, a, r, s_) # 保存记忆
if dqn.actCount > dqn.batchSize:
loss = dqn.learn()
if step % 100 == 0:
testResult = testModel(env,dqn)
reward = np.mean(rewardList)
rewardList = list()
# 保存数据
history["epsilon"].append(dqn.epsilon)
history["loss"].append(loss)
history["step"].append(step)
history["reward"].append(reward)
history["success"].append(success)
print("eps:%.2f loss:%.1f step:%d r:%.1f sucess:%d test:%d" % (dqn.epsilon, loss, step, reward, success,testResult))
historyDF = pd.DataFrame(history)
historyDF.to_excel("Result/DDQN训练过程.xlsx", index=None)
if testResult:
dqn.saveModel("Static/dqn.keras")
break
if step % 200 == 0:
dqn.updateTargetNet()
eps:0.95 loss:0.2 step:100 r:-9.0 sucess:0 test:0
eps:0.89 loss:0.0 step:200 r:-9.1 sucess:0 test:0
eps:0.85 loss:0.1 step:300 r:-9.4 sucess:0 test:0
eps:0.80 loss:0.3 step:400 r:-7.7 sucess:1 test:0
eps:0.76 loss:0.0 step:500 r:-9.0 sucess:1 test:0
eps:0.72 loss:0.1 step:600 r:-9.6 sucess:1 test:0
eps:0.68 loss:0.0 step:700 r:-9.1 sucess:1 test:0
eps:0.64 loss:0.1 step:800 r:-9.6 sucess:1 test:0
eps:0.61 loss:0.1 step:900 r:-9.0 sucess:1 test:0
eps:0.57 loss:0.0 step:1000 r:-9.4 sucess:1 test:0
eps:0.54 loss:0.0 step:1100 r:-9.2 sucess:1 test:0
eps:0.51 loss:0.0 step:1200 r:-9.0 sucess:1 test:0
eps:0.49 loss:0.1 step:1300 r:-9.5 sucess:1 test:0
eps:0.46 loss:0.1 step:1400 r:-9.1 sucess:1 test:0
eps:0.43 loss:0.1 step:1500 r:-9.5 sucess:1 test:0
eps:0.41 loss:0.0 step:1600 r:-9.2 sucess:1 test:0
eps:0.39 loss:0.1 step:1700 r:-9.0 sucess:1 test:0
eps:0.37 loss:0.0 step:1800 r:-9.6 sucess:1 test:0
eps:0.35 loss:0.0 step:1900 r:-7.8 sucess:2 test:0
eps:0.33 loss:0.0 step:2000 r:-9.3 sucess:2 test:0
eps:0.31 loss:0.1 step:2100 r:-9.1 sucess:2 test:0
eps:0.29 loss:0.1 step:2200 r:-8.9 sucess:2 test:0
eps:0.28 loss:0.1 step:2300 r:-9.4 sucess:2 test:0
eps:0.26 loss:0.0 step:2400 r:-9.3 sucess:2 test:0
eps:0.25 loss:0.0 step:2500 r:-9.3 sucess:2 test:0
eps:0.24 loss:0.1 step:2600 r:-9.0 sucess:2 test:0
eps:0.22 loss:0.0 step:2700 r:-9.4 sucess:2 test:0
eps:0.21 loss:0.1 step:2800 r:-9.2 sucess:2 test:0
eps:0.20 loss:0.0 step:2900 r:-8.8 sucess:2 test:0
eps:0.19 loss:0.1 step:3000 r:-9.5 sucess:2 test:0
eps:0.18 loss:0.1 step:3100 r:-9.2 sucess:2 test:0
eps:0.17 loss:0.6 step:3200 r:-9.3 sucess:2 test:0
eps:0.16 loss:0.1 step:3300 r:-7.8 sucess:3 test:0
eps:0.15 loss:0.1 step:3400 r:-9.1 sucess:3 test:0
eps:0.14 loss:0.2 step:3500 r:-9.4 sucess:3 test:0
eps:0.14 loss:0.0 step:3600 r:-9.1 sucess:3 test:0
eps:0.13 loss:0.1 step:3700 r:-9.5 sucess:3 test:0
eps:0.12 loss:0.1 step:3800 r:-8.9 sucess:3 test:0
eps:0.11 loss:0.1 step:3900 r:-7.7 sucess:4 test:0
eps:0.11 loss:0.1 step:4000 r:-9.6 sucess:4 test:0
eps:0.10 loss:0.1 step:4100 r:-9.3 sucess:4 test:0
eps:0.10 loss:0.0 step:4200 r:-9.0 sucess:4 test:0
eps:0.10 loss:0.0 step:4300 r:-9.4 sucess:4 test:0
eps:0.10 loss:0.1 step:4400 r:-9.2 sucess:4 test:0
eps:0.10 loss:0.8 step:4500 r:-9.1 sucess:4 test:0
eps:0.10 loss:0.1 step:4600 r:-8.0 sucess:5 test:0
eps:0.10 loss:0.1 step:4700 r:-9.3 sucess:5 test:0
eps:0.10 loss:0.1 step:4800 r:-8.9 sucess:5 test:0
eps:0.10 loss:0.1 step:4900 r:-8.1 sucess:6 test:0
eps:0.10 loss:0.1 step:5000 r:-7.4 sucess:7 test:0
eps:0.10 loss:0.1 step:5100 r:-3.3 sucess:11 test:0
eps:0.10 loss:0.2 step:5200 r:-3.0 sucess:15 test:0
eps:0.10 loss:0.1 step:5300 r:-6.1 sucess:17 test:0
eps:0.10 loss:0.1 step:5400 r:-7.6 sucess:18 test:0
eps:0.10 loss:0.1 step:5500 r:-5.9 sucess:20 test:0
eps:0.10 loss:0.1 step:5600 r:-6.0 sucess:22 test:0
eps:0.10 loss:1.0 step:5700 r:-3.5 sucess:26 test:0
eps:0.10 loss:0.9 step:5800 r:-9.1 sucess:26 test:0
eps:0.10 loss:0.2 step:5900 r:-7.5 sucess:27 test:0
eps:0.10 loss:0.1 step:6000 r:-1.3 sucess:32 test:0
eps:0.10 loss:0.1 step:6100 r:-7.5 sucess:33 test:0
eps:0.10 loss:0.8 step:6200 r:-7.3 sucess:34 test:0
eps:0.10 loss:0.9 step:6300 r:-1.4 sucess:39 test:0
eps:0.10 loss:0.1 step:6400 r:-7.5 sucess:40 test:1
可视化测试结果
对训练成熟的DDQN模型,先进行加载,然后一步步测试,查看每一步的八皇后棋盘状态
env.reset()
dqn.loadModel("Static/dqn.keras")
while True:
s = env.curState.copy()
a = dqn.chooseAction(s, random=False)
s_, r = env.play(a)
print("将皇后放入第%d行第%d列"%(int(np.sum(env.curState)),a+1))
if np.sum(s_)==8:
break
print(s_)
将皇后放入第1行第6列
将皇后放入第2行第3列
将皇后放入第3行第7列
将皇后放入第4行第2列
将皇后放入第5行第8列
将皇后放入第6行第5列
将皇后放入第7行第1列
将皇后放入第8行第4列
[[0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0.]
[0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 1. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0.]]
