
程序简介
百度图片爬虫的封装接口2018年实现的,现在还能用...不错,谢谢百度的不封之恩,先将其贡献给所有热爱技术的开发者
输入:关键词、下载数量、重定尺寸(可省)
输出:自动创建文件夹下载对应数量的百度图片,图片由md5命令
程序/数据集下载

代码分析
导入模块
import numpy as np
import hashlib
import requests
import json
import cv2
import os
evalMd5函数用来计算图片md5,好进行命名和过滤相同图片
def evalMd5(sentence,charset='utf8'):
'''
计算一段字符串的md5
:param sentence: 字符串
:param charset: 字符集
:return: md5值
'''
#将字符串编码成bytes
if type(sentence) != bytes:
sentence = sentence.encode(charset)
md5 = hashlib.md5(sentence).hexdigest()
return md5
resizeImg函数用来重定图片尺寸
def resizeImg(oldPath,size,newPath):
'''
重定图片尺寸
:param oldPath: 图片路径
:param size: 重定大小
:param newPath: 图片保存路径
:return: None
'''
oldPath = oldPath.replace('\\','/')
newPath = newPath.replace('\\','/')
oldImg = cv2.imdecode(np.fromfile(oldPath,dtype=np.uint8),-1)
try:
newImg = cv2.resize(oldImg,size,) #为图片重新指定尺寸
cv2.imwrite(newPath,newImg)
cv2.imencode('.'+newPath.split('.')[-1],newImg)[1].tofile(newPath)
except:
#图片格式不对发生错误,删除
os.remove(oldPath)
核心函数download会调用上面的函数进行批量图片下载
def download(keyWord,imgNumber,imgSize=None):
'''
下载图片到关键词文件夹
:param keyWord: 关键词
:param imgNumber: 图片数量
:param imgSize: 图片重定大小
:return: None
'''
#创建关键词文件夹
dirname = keyWord
if not os.path.exists(dirname):
os.mkdir(dirname)
#开始爬图片
url = 'https://image.baidu.com/search/acjson'#图片网址
same = 0#重复下载数
error = 0#错误数
passNum = 0#无链接数
for i in range(30,30*10000+30,30):
param = {
'tn': 'resultjson_com','ipn': 'rj',
'ct': 201326592,
'is': '',
'fp': 'result',
'queryWord': keyWord,
'cl': 2,
'lm': -1,
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': -1,
'z': '',
'ic': 0,
'word': keyWord,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': 0,
'istype': 2,
'qc': '',
'nc': 1,
'fr': '',
'pn': i,
'rn': 30,
'gsm': '1e',
'1488942260214': ''
}
#所有图片地址列表
data = requests.get(url,params=param).text.replace('\\','\\\\')
try:
data = json.loads(data)['data']
except:
#json数据可能不合法,直接跳过
error += 1
if error >=20:
return None
continue
for item in data:
imgUrl = item.get("middleURL")#图片地址
if passNum>=20:
return None
if imgUrl is None:
passNum+=1
continue
suffix = imgUrl.split('.')[-1]#图片后缀
imgContent = requests.get(imgUrl).content#图片内容
imgMd5 = evalMd5(imgContent)#图片md5
imgPath = os.path.join(dirname,'%s.%s'%(imgMd5,suffix))#图片路径
oldFinish = len(os.listdir(dirname))
open(imgPath, 'wb').write(imgContent)#写入
#重定尺寸
if imgSize:
resizeImg(imgPath,imgSize,imgPath)
newFinish = len(os.listdir(dirname))
print('key:%s goal:%d finish:%d'%(keyWord,imgNumber,newFinish))
#图片数达标,退出
if newFinish >= imgNumber:
return None
#重复下载图片达到100次,说明已经下载完所有图片,退出
if newFinish == oldFinish:
same+=1
if same >= 20:
return
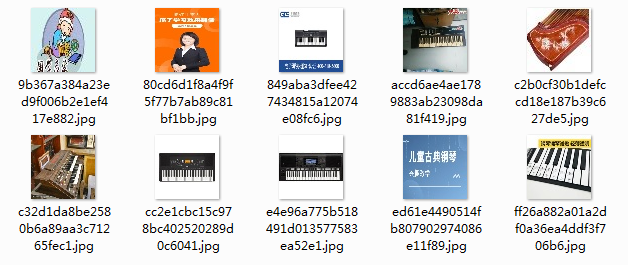
来测试一下看看效果吧~
imgNumber = 10
keys = ['电子琴','苹果']
imgSize = None
for keyWord in keys:
download(keyWord,imgNumber,imgSize)
key:电子琴 goal:10 finish:1
key:电子琴 goal:10 finish:2
key:电子琴 goal:10 finish:3
key:电子琴 goal:10 finish:4
key:电子琴 goal:10 finish:5
key:电子琴 goal:10 finish:6
key:电子琴 goal:10 finish:7
key:电子琴 goal:10 finish:8
key:电子琴 goal:10 finish:9
key:电子琴 goal:10 finish:10
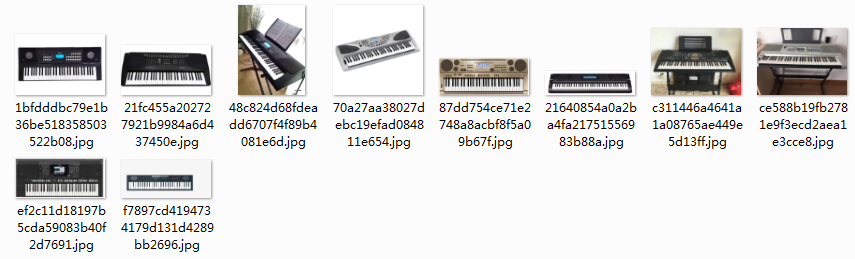
key:苹果 goal:10 finish:1
key:苹果 goal:10 finish:2
key:苹果 goal:10 finish:3
key:苹果 goal:10 finish:4
key:苹果 goal:10 finish:5
key:苹果 goal:10 finish:6
key:苹果 goal:10 finish:7
key:苹果 goal:10 finish:8
key:苹果 goal:10 finish:9
key:苹果 goal:10 finish:10

 浙公网安备 33010602011771号
浙公网安备 33010602011771号