

一、简介
环境介绍
角色
172.16.133.82 InfluxDb 172.16.133.82 Grafana 172.16.133.82 jmxtrans kafka 172.16.133.82 node1
软件版本
influxdb-1.7.7.x86_64.rpm grafana-6.2.5-1.x86_64.rpm jmxtrans-266.rpm kafka_2.12-0.10.2.1
二、配置规划
- jmxtrans可以分别在每台kafka节点上部署,也可以部署到一台机器上,这里是选择了后者,因为集群小,这样配置文件可以集中管理,如果集群比较大,可以考虑分散部署
- 关于jmxtrans的配置文件,分全局指标(每个kafka节点)和topic指标,全局指标每个节点一个配置文件,命名规则:base_172.16.133.82.json,topic指标是每个topic一个配置文件,命名规则:falcon_monitor_us_82.json
三、监控指标
全局指标
每秒输入的流量
"obj" : "kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec"
"attr" : [ "Count" ]
"resultAlias":"BytesInPerSec"
"tags" : {"application" : "BytesInPerSec"}
每秒输出的流量
"obj" : "kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec"
"attr" : [ "Count" ]
"resultAlias":"BytesOutPerSec"
"tags" : {"application" : "BytesOutPerSec"}
每秒输入的流量
"obj" : "kafka.server:type=BrokerTopicMetrics,name=BytesRejectedPerSec"
"attr" : [ "Count" ]
"resultAlias":"BytesRejectedPerSec"
"tags" : {"application" : "BytesRejectedPerSec"}
每秒的消息写入总量
"obj" : "kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec"
"attr" : [ "Count" ]
"resultAlias":"MessagesInPerSec"
"tags" : {"application" : "MessagesInPerSec"}
每秒FetchFollower的请求次数
"obj" : "kafka.network:type=RequestMetrics,name=RequestsPerSec,request=FetchFollower"
"attr" : [ "Count" ]
"resultAlias":"RequestsPerSec"
"tags" : {"request" : "FetchFollower"}
每秒FetchConsumer的请求次数
"obj" : "kafka.network:type=RequestMetrics,name=RequestsPerSec,request=FetchConsumer"
"attr" : [ "Count" ]
"resultAlias":"RequestsPerSec"
"tags" : {"request" : "FetchConsumer"}
每秒Produce的请求次数
"obj" : "kafka.network:type=RequestMetrics,name=RequestsPerSec,request=Produce"
"attr" : [ "Count" ]
"resultAlias":"RequestsPerSec"
"tags" : {"request" : "Produce"}
内存使用的使用情况
"obj" : "java.lang:type=Memory"
"attr" : [ "HeapMemoryUsage", "NonHeapMemoryUsage" ]
"resultAlias":"MemoryUsage"
"tags" : {"application" : "MemoryUsage"}
GC的耗时和次数
"obj" : "java.lang:type=GarbageCollector,name=*"
"attr" : [ "CollectionCount","CollectionTime" ]
"resultAlias":"GC"
"tags" : {"application" : "GC"}
线程的使用情况
"obj" : "java.lang:type=Threading"
"attr" : [ "PeakThreadCount","ThreadCount" ]
"resultAlias":"Thread"
"tags" : {"application" : "Thread"}
副本落后主分片的最大消息数量
"obj" : "kafka.server:type=ReplicaFetcherManager,name=MaxLag,clientId=Replica"
"attr" : [ "Value" ]
"resultAlias":"ReplicaFetcherManager"
"tags" : {"application" : "MaxLag"}
该broker上的partition的数量
"obj" : "kafka.server:type=ReplicaManager,name=PartitionCount"
"attr" : [ "Value" ]
"resultAlias":"ReplicaManager"
"tags" : {"application" : "PartitionCount"}
正在做复制的partition的数量
"obj" : "kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions"
"attr" : [ "Value" ]
"resultAlias":"ReplicaManager"
"tags" : {"application" : "UnderReplicatedPartitions"}
Leader的replica的数量
"obj" : "kafka.server:type=ReplicaManager,name=LeaderCount"
"attr" : [ "Value" ]
"resultAlias":"ReplicaManager"
"tags" : {"application" : "LeaderCount"}
一个请求FetchConsumer耗费的所有时间
"obj" : "kafka.network:type=RequestMetrics,name=TotalTimeMs,request=FetchConsumer"
"attr" : [ "Count","Max" ]
"resultAlias":"TotalTimeMs"
"tags" : {"application" : "FetchConsumer"}
一个请求FetchFollower耗费的所有时间
"obj" : "kafka.network:type=RequestMetrics,name=TotalTimeMs,request=FetchFollower"
"attr" : [ "Count","Max" ]
"resultAlias":"TotalTimeMs"
"tags" : {"application" : "FetchFollower"}
一个请求Produce耗费的所有时间
"obj" : "kafka.network:type=RequestMetrics,name=TotalTimeMs,request=Produce"
"attr" : [ "Count","Max" ]
"resultAlias":"TotalTimeMs"
"tags" : {"application" : "Produce"}
topic的监控指标
falcon_monitor_us每秒的写入流量
"kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec,topic=falcon_monitor_us"
"attr" : [ "Count" ]
"resultAlias":"falcon_monitor_us"
"tags" : {"application" : "BytesInPerSec"}
falcon_monitor_us每秒的输出流量
"kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec,topic=falcon_monitor_us"
"attr" : [ "Count" ]
"resultAlias":"falcon_monitor_us"
"tags" : {"application" : "BytesOutPerSec"}
falcon_monitor_us每秒写入消息的数量
"obj" : "kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec,topic=falcon_monitor_us"
"attr" : [ "Count" ]
"resultAlias":"falcon_monitor_us"
"tags" : {"application" : "MessagesInPerSec"}
falcon_monitor_us在每个分区最后的Offset
"obj" : "kafka.log:type=Log,name=LogEndOffset,topic=falcon_monitor_us,partition=*"
"attr" : [ "Value" ]
"resultAlias":"falcon_monitor_us"
"tags" : {"application" : "LogEndOffset"}
参数说明
obj对应jmx的ObjectName,就是要监控的指标
attr对应ObjectName的属性,可以理解为要监控的指标的值
resultAlias对应metric 的名称,在InfluxDb里面就是MEASUREMENTS名
tags对应InfluxDb的tag功能,对与存储在同一个MEASUREMENTS里面的不同监控指标可以做区分,我们在用Grafana绘图的时候会用到,建议对每个监控指标都打上tags
对于全局监控,每一个监控指标对应一个MEASUREMENTS,所有的kafka节点同一个监控指标数据写同一个MEASUREMENTS ,对于topc监控的监控指标,同一个topic所有kafka节点写到同一个MEASUREMENTS,并且以topic名称命名
四、安装与配置
kafka
因为需要通过jmx采集kafka的监控数据,所以在kafka的启动时候需要启动jmx端口,启动方式如下:
cd /data/kafka/bin/ JMX_PORT=9999 nohup ./kafka-server-start.sh ../config/server.properties >/dev/null 2>&1 &
或者在启动kafka的脚本kafka-server-start.sh中找到堆设置,添加export JMX_PORT="9999"
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" export JMX_PORT="9999" fi
influxDb
创建jmxDB数据库:
[devuser@annie thirdparties]$ influx Connected to http://localhost:8086 version 1.6.2 InfluxDB shell version: 1.7.7 > CREATE DATABASE "jmxDB" > create retention policy "72_hour" on jmxDB duration 72h replication 1 DEFAULT >
jmxtrans
#判断是否已安装此软件 rpm -qa |grep jmx #卸载 rpm -e jmxXXXXXX #下载 wget https://github.com/downloads/jmxtrans/jmxtrans/jmxtrans-20121016.145842.6a28c97fbb-0.noarch.rpm#安装 rpm -ivh jmxtrans-20121016.145842.6a28c97fbb-0.noarch.rpm#启动[启动前配置好/var/lib/jmxtrans下的json配置]
#启动 必须root用户启动
/etc/init.d/jmxtrans start
#或
./jmxtrans.sh start
说明:
这些只是默认目录,如果用 jmxtrans.sh start 启动的话,是不会默认这些目录的 ,如果用 /etc/init.d/jmxtrans start 启动,会有一些报错
jmxtrans安装目录:/usr/share/jmxtrans
jmxtrans配置文件 :/etc/sysconfig/jmxtrans
json配置文件默认目录:/var/lib/jmxtrans/
去安装目录建立json和log目录
cd /usr/share/jmxtrans
mkdir json
mkdir logs
这里在用 /etc/init.d/jmxtrans start 启动时报错如下:
报错一:
Caused by: java.lang.IllegalArgumentException: Invalid type id 'com.googlecode.jmxtrans.model.output.InfluxDbWriterFactory' (for id type 'Id.class'): no such class found
at org.codehaus.jackson.map.jsontype.impl.ClassNameIdResolver.typeFromId(ClassNameIdResolver.java:89)
at org.codehaus.jackson.map.jsontype.impl.TypeDeserializerBase._findDeserializer(TypeDeserializerBase.java:73)
at org.codehaus.jackson.map.jsontype.impl.AsPropertyTypeDeserializer.deserializeTypedFromObject(AsPropertyTypeDeserializer.java:65)
at org.codehaus.jackson.map.deser.AbstractDeserializer.deserializeWithType(AbstractDeserializer.java:81)
at org.codehaus.jackson.map.deser.CollectionDeserializer.deserialize(CollectionDeserializer.java:118)
解决方案:
官网找到github地址下载源码,重新编译将jar包替换,去修改jmxtrans.sh脚本,将项目所用jar包替换为重新编译生成的
git clone https://github.com/jmxtrans/jmxtrans.git mvn clean package -Dmaven.test.skip=true -DskipTests=true;

cd /usr/share/jmxtrans vim jmxtrans.conf #export JAR_FILE="/usr/share/jmxtrans/jmxtrans-all.jar" export JAR_FILE="/usr/share/jmxtrans/jmxtrans-271-all.jar" vim jmxtrans.sh #JAR_FILE=${JAR_FILE:-"jmxtrans-all.jar"} JAR_FILE=${JAR_FILE:-"jmxtrans-271-all.jar"}
对比一下发现编译的包是有这个类的,而自带的那个没有
[devuser@annie jmxtrans]$ grep 'com.googlecode.jmxtrans.model.output.InfluxDbWriterFactory' ./jmxtrans-271-all.jar Binary file ./jmxtrans-271-all.jar matches [devuser@annie jmxtrans]$ grep 'com.googlecode.jmxtrans.model.output.InfluxDbWriterFactory' ./jmxtrans-all.jar [devuser@annie jmxtrans]$
报错二:
Starting jmxtrans: [ OK ] Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=384m; support was removed in 8.0 Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=384m; support was removed in 8.0 MaxTenuringThreshold of 16 is invalid; must be between 0 and 15 Error: Could not create the Java Virtual Machine. Error: A fatal exception has occurred. Program will exit.
解决方案:
#JDK8 里Nimbus -XX:MaxTenuringThreshold 的最大值是15,默认配置里的是16 cd /usr/share/jmxtrans vim jmxtrans.sh #-XX:MaxTenuringThreshold=16 改为: -XX:MaxTenuringThreshold=15
jmxtrans默认读取/var/lib/jmxtrans下的配置文件去采集数据的,所以需要把采集kafka监控数据的配置文件都放在这个目录下,下面是是一些配置文件命名规范:
[root@annie thirdparties]# cd /var/lib/jmxtrans [root@annie jmxtrans]# ll total 0 [root@annie jmxtrans]# pwd /var/lib/jmxtrans [root@annie jmxtrans]# wget http://qu2lhckc6.hn-bkt.clouddn.com/jmxtrans-kafka/base_172.16.133.82.json [root@annie jmxtrans]# wget http://qu2lhckc6.hn-bkt.clouddn.com/jmxtrans-kafka/falcon_monitor_us_82.json [root@annie jmxtrans]# ll total 16 -rw-r--r-- 1 root root 8462 Jun 2 18:41 base_172.16.133.82.json -rw-r--r-- 1 root root 2029 Jun 2 18:41 falcon_monitor_us_82.json
重新启动 /etc/init.d/jmxtrans start
然后在influxdb里可以看到数据已经生成
[devuser@annie jmxtrans]$ influx Connected to http://localhost:8086 version 1.6.2 InfluxDB shell version: 1.7.7 > show DATABASES name: databases name ---- _internal metrics jmxDB> use jmxDB Using database jmxDB > show MEASUREMENTS name: measurements name ---- BytesInPerSec BytesOutPerSec BytesRejectedPerSec GC MemoryUsage MessagesInPerSec ReplicaFetcherManager ReplicaManager RequestsPerSec Thread TotalTimeMs jvmMemory
小插曲:
如果这里查询不到数据,先drop调database再重新创建,数据就能进去了
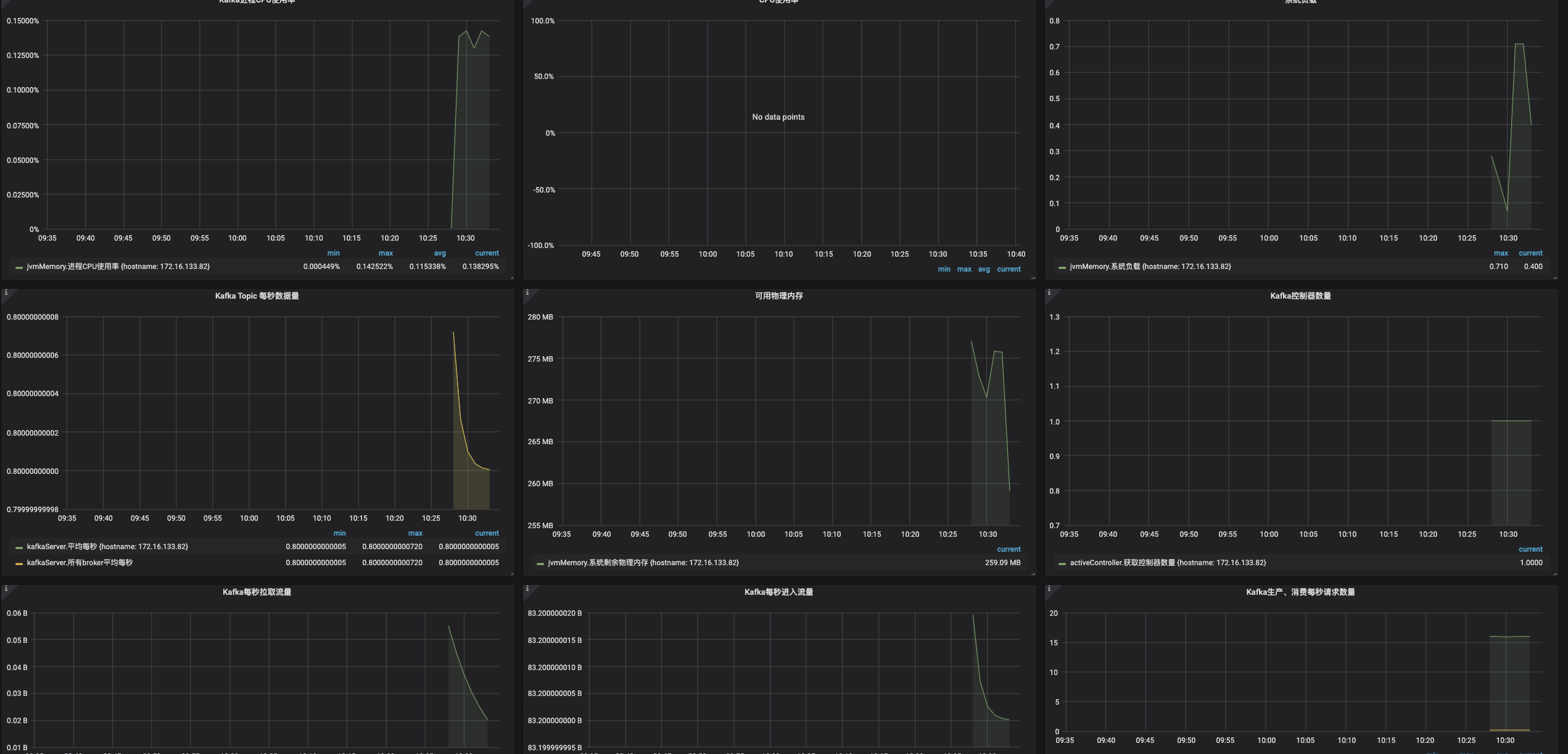
五、grafana的配置与预览
链接: https://pan.baidu.com/s/1NGqdRYKRBCkzuAEESvnfCw 提取码: qtrv
链接: https://pan.baidu.com/s/1xMMOuMwRQsEmTrrUxJf6lw
参考文献
jmxtrans介绍与安装
Kafka JMX 监控 之 jmxtrans + influxdb + grafana (内有json模板配置文件)

