
对上面这几个名词认识,但要说对他们的理解,不知道。在项目开发过程中,经常会遇到说什么从缓存读取数据,拷贝到内存, 什么值存在寄存器中等等,但都是傻傻分不清。没有自己的理解。
下面从volatile关键字引入本节的学习
原文链接:https://blog.csdn.net/Goforyouqp/article/details/131309962 下面这段话
`volatile`是一个C/C++关键字,它用于告诉编译器当前变量是易变的,需要在每次使用时都从内存中重新获取值,而不是使用缓存中的旧值。
一般来说,对于定义在函数中的自动变量,编译器会尽量利用寄存器来提高访问速度,这样就会使得该变量的值可能被缓存起来,不一定会立即被写入内存。如果这时候要访问这个变量的值,就可能会出现错误的结果。特别是在并发编程或者嵌入式开发等场景下,可能会对内存进行随时修改,此时使用`volatile`关键字就可以防止出现这种错误。
使用`volatile`关键字时需要注意,它仅仅告诉编译器该变量是易变的,不应该使用寄存器来存储其值,但并不保证进程访问该变量的正确性,仍然需要考虑对多线程的并发安全问题,要遵循原子操作和加锁等操作。
因此,使用 `volatile` 关键字可以告诉编译器,该变量的值是不稳定的,可能会在程序执行期间被修改,编译器必须每次读取该变量的实际值而不是使用寄存器中的旧值。
需要注意的是,`volatile` 并不能保证线程安全或原子性,它只能避免编译器对该变量的过度优化,而并不能保证其他线程或硬件设备对其的修改操作。如果需要保证线程安全和原子性,通常需要使用更高级别的同步原语,例如互斥锁、条件变量、原子变量等。
一:内存,寄存器,缓存
按与CPU远近来分,离得最近的是寄存器,然后缓存(CPU缓存),最后内存。
CPU计算时,先预先把要用的数据从硬盘读到内存,然后再把即将要用的数据读到寄存器。于是 CPU<--->寄存器<--->内存,这就是它们之间的信息交换。
那为什么有缓存呢?因为如果经常操作内存中的同一址地的数据,就会影响速度。于是就在寄存器与内存之间设置一个缓存。
因为从缓存提取的速度远高于内存。当然缓存的价格肯定远远高于内存,不然的话,机器里就没有内存的存在。
由此可以看出,从远近来看:CPU〈---〉寄存器〈---> 缓存 <---> 内存。
先附上一张计算机硬件组成图片:
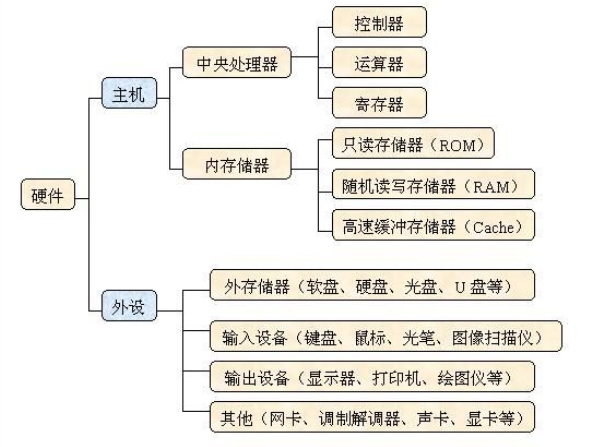
CPU:
中央处理器(CPU,Central Processing Unit)是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit)。它的功能主要是解释计算机指令以及处理计算机软件中的数据。
中央处理器主要包括运算器(算术逻辑运算单元,ALU,Arithmetic Logic Unit)和高速缓冲存储器(Cache)及实现它们之间联系的数据(Data)、控制及状态的总线(Bus)。它与内部存储器(Memory)和输入/输出(I/O)设备合称为电子计算机三大核心部件。

1、寄存器
寄存器(register)是CPU(中央处理器)的组成部分,是一种直接整合到cpu中的有限的高速访问速度的存储器,它是有一些与非门组合组成的,分为通用寄存器和特殊寄存器。cpu访问寄存器的速度是最快的。那为什么我们不把数据都存储到寄存器中呢,因为寄存器是一种容量有限的存储器,并且非常小。因此只把一些计算机的指令等一些计算机频繁用到的数据存储在其中,来提高计算机的运行速度。
2、缓存(Cache)
缓存就是数据交换的缓冲区(称作Cache),当某一硬件要读取数据时,会首先从缓存中查找需要的数据,如果找到了则直接执行,找不到的话则从内存中找。由于缓存的运行速度比内存快得多,故缓存的作用就是帮助硬件更快地运行。
因为缓存往往使用的是RAM(断电即掉的非永久储存),所以在用完后还是会把文件送到硬盘等存储器里永久存储。电脑里最大的缓存就是内存条了,最快的是CPU上镶的L1和L2缓存,显卡的显存是给显卡运算芯片用的缓存,硬盘上也有16M或者32M的缓存。
CACHE是在CPU中速度非常块,而容量却很小的一种存储器,它是计算机存储器中最强悍的存储器。由于技术限制,容量很难提升。
对于大多数人来说Cache,是透明的、不存在的。其中一个原因是Cache是集成到CPU中,对于程序员来说是透明的。
2.1、寄存器和缓存的区别
按与CPU远近来分,离得最近的是寄存器,然后缓存,最后内存。所以,寄存器是最贴近CPU的,而且CPU只与寄存器中进行存取。寄存器从内存中读取数据,但由于寄存器和内存读取速度相差太大,所以有了缓存。即读取数据的方式为:
CPU <------>寄存器 <---->缓存<----->内存
当寄存器没有从缓存中读取到数据时,也就是没有命中,那么就从内存中读取数据。
2.2、一级缓存和二级缓存
CPU读取数据的顺序为先缓存后内存。
CPU内部集成的缓存称为一级缓存(L1 Cache),外部的称为二级缓存(L2 Cache)。
一级缓存中又分为数据缓存(D-Cache)和指令缓存(I-Cache)。二者可以同时被CPU进行访问,减少了争用Cache所造成的冲突,提高了CPU的效能。
CPU的一级缓存通常都是静态RAM(Static RAM/SRAM),速度非常快,但是贵。
为提高系统的性能和速度又必须扩大缓存,所以在不扩大原来的静态RAM缓存容量的情况下,仅仅增加一些高速动态RAM(Dynamic RAM/DRAM)做为L2级缓存。高速动态RAM速度要比常规动态RAM快,但比原来的静态RAM缓存慢,而且成本也较为适中。一级缓存和二级缓存中的内容都是内存中访问频率高的数据的复制品(映射),它们的存在都是为了减少高速CPU对慢速内存的访问。
二级缓存是CPU性能表现的关键之一,在CPU核心不变化的情况下,增加二级缓存容量能使性能大幅度提高。而同一核心的CPU高低端之分往往也是在二级缓存上存在差异.
CPU在缓存中找到有用的数据被称为命中,当缓存中没有CPU所需的数据时(这时称为未命中),CPU才访问内存。从理论上讲,在一颗拥有二级缓存的CPU中,读取一级缓存的命中率为80%。也就是说CPU一级缓存中找到的有用数据占数据总量的80%,剩下的20%从二级缓存中读取。由于不能准确预测将要执行的数据,读取二级缓存的命中率也在80%左右(从二级缓存读到有用的数据占总数据的16%)。那么还有的数据就不得不从内存调用,但这已经是一个相当小的比例了。
在较高端CPU中,还会带有三级缓存,它是为读取二级缓存后未命中的数据设计的一种缓存,在拥有三级缓存的CPU中,只有约5%的数据需要从内存中调用,这进一步提高了CPU的效率,从某种意义上说,预取效率的提高,大大降低了生产成本却提供了非常接近理想状态的性能。
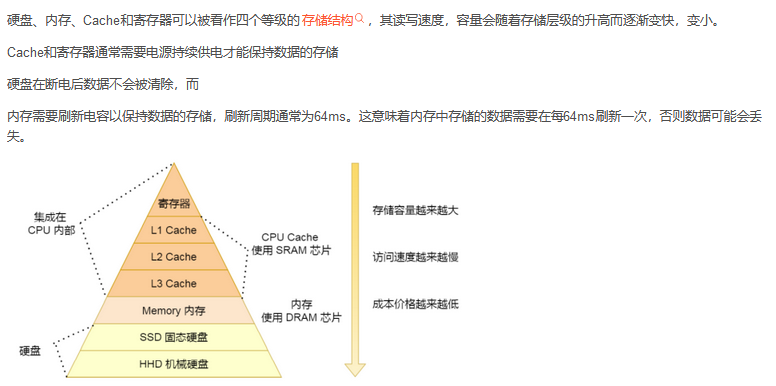
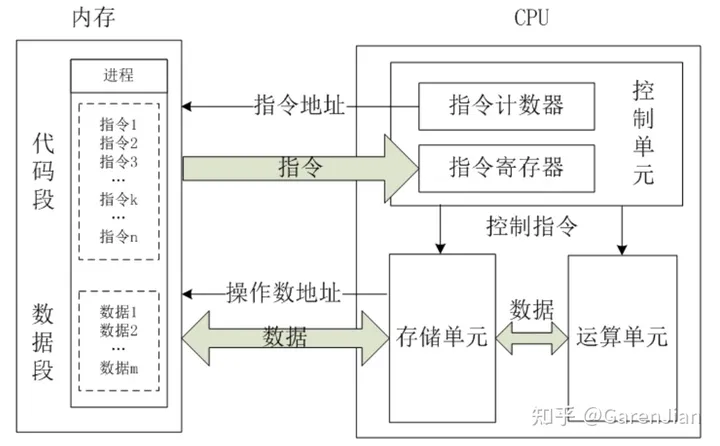
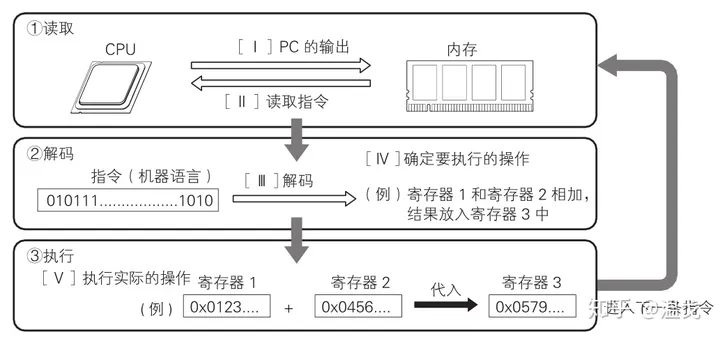
到这里基本就明白这几个名词的定义和关系。那么下面就是要理解在某个程序运行过程中,是怎么访问上述几个内存的。
下面再详细描述下缓存的概念。
缓存
在处理器看来,缓存是一个透明部件。因此,程序员通常无法直接干预对缓存的操作。但是,确实可以根据缓存的特点对程序代码实施特定优化,从而更好地利用缓存。
一、 基础知识
CPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。CPU高速缓存的出现主要是为了解决CPU运算速度与内存读写速度不匹配的矛盾,因为CPU运算速度要比内存读写速度快很多,这样会使CPU花费很长时间等待数据到来或把数据写入内存。在缓存中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可先缓存中调用,从而加快读取速度。
当CPU需要读取数据并进行计算时,首先需要将CPU缓存中查到所需的数据,并在最短的时间下交付给CPU。如果没有查到所需的数据,CPU就会提出“要求”经过缓存从内存中读取,再原路返回至CPU进行计算。而同时,把这个数据所在的数据也调入缓存,可以使得以后对整块数据的读取都从缓存中进行,不必再调用内存。
缓存大小是CPU的重要指标之一,而且缓存的结构和大小对CPU速度的影响非常大,CPU内缓存的运行频率极高,一般是和处理器同频运作,工作效率远远大于系统内存和硬盘。实际工作时,CPU往往需要重复读取同样的数据块,而缓存容量的增大,可以大幅度提升CPU内部读取数据的命中率,而不用再到内存或者硬盘上寻找,以此提高系统性能。但是从CPU芯片面积和成本的因素来考虑,缓存都很小。
大家都知道现在CPU的多核技术,都会有几级缓存,现在的CPU会有三级内存(L1,L2, L3),如下图所示:
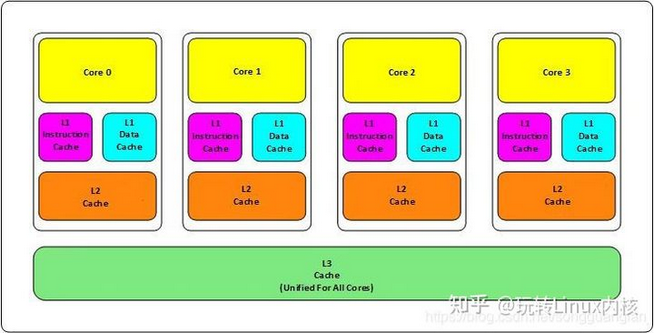
CPU一级缓存、二级缓存、三级缓存是什么意思?
一级缓存(L1 Cache)
CPU一级缓存,就是指CPU的第一层级的高速缓存,主要当担的工作是缓存指令和缓存数据。一级缓存的容量与结构对CPU性能影响十分大,但是由于它的结构比较复杂,又考虑到成本等因素,一般来说,CPU的一级缓存较小,通常CPU的一级缓存也就能做到256KB左右的水平。
二级缓存(L2 Cache)
CPU二级缓存,就是指CPU的第二层级的高速缓存,而二级缓存的容量会直接影响到CPU的性能,二级缓存的容量越大越好。例如intel的第八代i7-8700处理器,共有六个核心数量,而每个核心都拥有256KB的二级缓存,属于各核心独享,这样二级缓存总数就达到了1.5MB。
三级缓存(L3 Cache)
CPU三级缓存,就是指CPU的第三层级的高速缓存,其作用是进一步降低内存的延迟,同时提升海量数据量计算时的性能。和一级缓存、二级缓存不同的是,三级缓存是核心共享的,能够将容量做的很大。
其中:
- L1缓存分成两种,一种是指令缓存,一种是数据缓存。L2缓存和L3缓存不分指令和数据。在L1缓存中,有一个叫做Cache line的东西。 他表示cpu从一级缓存读取数据的最小单位
- L1和L2缓存在每一个CPU核中,L3则是所有CPU核心共享的内存。
- L1、L2、L3的越离CPU近就越小,速度也就越快,越离CPU远,速度也越慢。
再往后面就是内存,内存的后面就是硬盘。我们来看一些他们的速度
- L1的存取速度:4个CPU时钟周期
- L2的存取速度:11个CPU时钟周期
- L3的存取速度:39个CPU时钟周期
- RAM内存的存取速度:107个CPU时钟周期
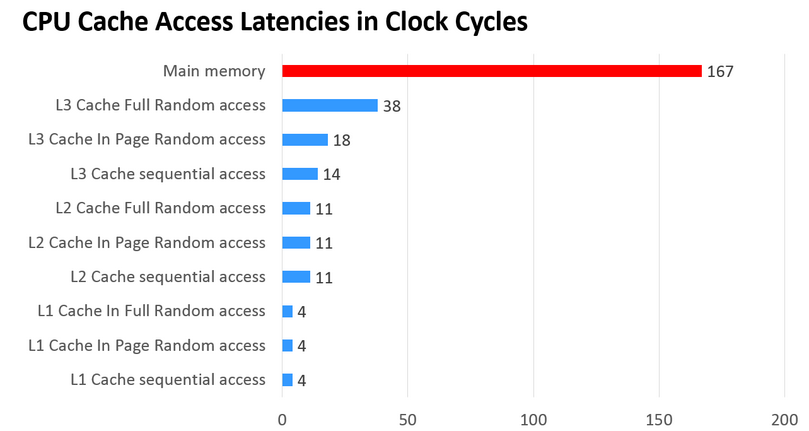
我们可以看到,L1的速度是RAM的27倍,L1和L2的存取大小基本上是KB级的,L3则是MB级别的。例如,Intel Core i7-8700K,是一个6核的CPU,每核上的L1是64KB(数据和指令各32KB),L2是256K,L3有2MB。
我们的数据从内存向上,先到L3,再到L2,再到L1,最后到寄存器进行计算。那么,为什么会设计成三层?这里有以下几方面的考虑:
物理速度,如果要更大的容量就需要更多的晶体管,除了芯片的体积会变大,更重要的是大量的晶体管会导致速度下降,因为访问速度和要访问的晶体管所在的位置成反比。也就是当信号路径变长时,通信速度会变慢,这就是物理问题。
另外一个问题是,多核技术中,数据的状态需要在多个CPU进行同步。我们可以看到,cache和RAM的速度差距太大。所以,多级不同尺寸的缓存有利于提高整体的性能。
这个世界永远是平衡的,一面变得有多光鲜,另一方面也会变得有多黑暗,建立多级的缓存,一定就会引入其它的问题。这里有两个比较重要的问题。
一个是比较简单的缓存命中率的问题,另一个是比较复杂的缓存更新的一致性问题
尤其是第二个问题,在多核技术下,这就很像分布式系统了,要面对多个地方进行更新。
因此引入了MESI协议
由于Cache位于CPU内部,意味着对于多个CPU,缓存之对于所在的CPU可见,那么对于每个CPU在处理数据的时候就不免会造成缓存和主存的数据不一致的问题
为了解决这个问题,CPU厂商提出了两种解决方案
1,总线锁定:当某个CPU处理数据时,通过锁定系统总线或者时内存总线,让其他CPU不具备访问内存的访问权限,从而保证了缓存的一致性
2,缓存一致性协议(MESI):缓存一致性协议也叫缓存锁定,缓存一致性协议会阻止两个以上CPU同时修改缓存了相同主存数据的缓存副本
总线锁定开销太大,现代的处理器已经很少采用这种方式保证缓存数据一致性,重点分析一下MESI协议,这对于JMM模型的理解也很有帮助
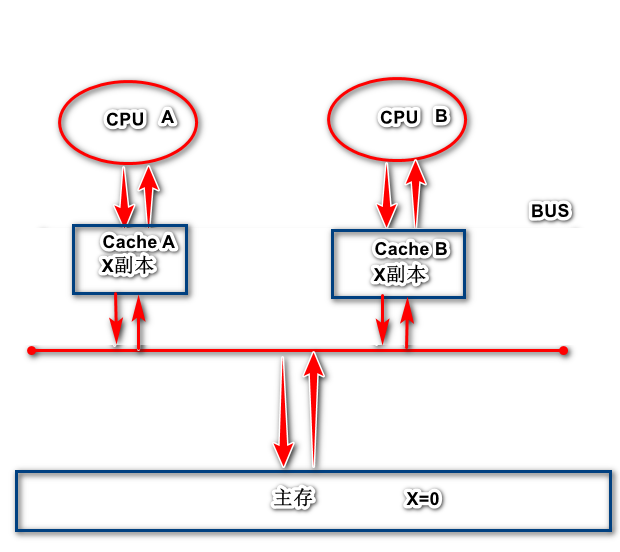
1.当CPU A将主存中的x cache line读入缓存中时,此时X副本的状态为E独占。
2.当CPU B将主存中的X cache line读入缓存中时,AB同时嗅探总线,得知X cache line不止一个副本,此时X的状态变为S共享
3,当CPU A将CACHE A中的x cache line修改为1后,Cache A中的X cache line 的状态变为M修改,并发送消息给CPU B,CPU将X cache line的状态变为I无效
4.当CPU A确认所有CPU缓存中的都提交了I无效状态,将修改后的值刷新到主存中,此时主存中的X变为了1,此时Cache A中的x cache line变为E独享
5.当CPU B需要用到X,发出读取X指令,于是读取主存中的x,于是重复第二步
为什么要设置那么多缓存
根据摩尔定律,CPU 的访问速度每 18 个月就会翻倍(是指研发的新CPU访问速度),相当于每年增长 60% 左右,内存的速度当然也会不断增长,但是增长的速度远小于 CPU,平均每年只增长 7% 左右。于是,CPU 与内存的访问性能的差距不断拉大。
1 MB 大小的 CPU Cache 需要 7 美金的成本,而内存只需要 0.015 美金的成本,成本方面相差了 466 倍,所以 CPU Cache 不像内存那样动辄以 GB 计算,它的大小是以 KB 或 MB 来计算的。
为了解决这一问题,CPU设置了多级缓存结构
其中较为典型的有L1,L2,L3高速缓存
其中L1高速缓存具有和寄存器差不多的速度。
L1,L2,L3缓存都位于芯片内部,这些缓存我们统称为Cache
Cache line是什么,对数读取有什么影响
- 在L1缓存中,有一个叫做Cache line的东西。 他表示cpu从一级缓存读取数据的最小单位。
- L1和L2缓存在每一个CPU核中,L3则是所有CPU核心共享的内存。
二、 缓存命中
缓存需要把内存里的数据放进来,英文叫CPU Associativity,Cache的数据放置策略决定了内存中的数据会拷贝到CPU Cache中的哪个位置上,因为Cache的大小远远小于内存,所以,需要有一种地址关联算法,能够让内存中的数据被映射到Cache中。这个就有点像内存地址从逻辑地址到物理地址的映射方法。但是不完全一样。 具体方法就不学习了。
三、缓存一致
对于主流的CPU来说,缓存的写操作基本上是两种策略
- Write Back:写操作只在Cache上,然后再flush到内存上
- Write Through:写操作同时写到cache和内存上。
为了提高写的性能,一般来说,主流的CPU(如:Intel Core i7/i9)采用的是Write Back的策略,因为直接写内存实在是太慢了。
好了,现在问题来了,如果有一个数据 x 在 CPU 第0核的缓存上被更新了,那么其它CPU核上对于这个数据 x 的值也要被更新,这就是缓存一致性的问题。
这里介绍几个状态协议,先从最简单的开始,MESI协议,这个协议跟那个著名的足球运动员梅西没什么关系,其主要表示缓存数据有四个状态:Modified(已修改), Exclusive(独占的),Shared(共享的),Invalid(无效的)。
MESI 这种协议在数据更新后,会标记其它共享的CPU缓存的数据拷贝为Invalid状态,然后当其它CPU再次read的时候,就会出现 cache miss 的问题,此时再从内存中更新数据。从内存中更新数据意味着20倍速度的降低。我们能不能直接从我隔壁的CPU缓存中更新?是的,这就可以增加很多速度了,但是状态控制也就变麻烦了。还需要多来一个状态:Owner(宿主),用于标记,我是更新数据的源。于是,出现了 MOESI 协议。
MOESI协议允许 CPU Cache 间同步数据,于是也降低了对内存的操作,性能是非常大的提升,但是控制逻辑也非常复杂。
顺便说一下,与 MOESI 协议类似的一个协议是 MESIF,其中的 F 是 Forward,同样是把更新过的数据转发给别的 CPU Cache 但是,MOESI 中的 Owner 状态 和MESIF 中的 Forward 状态有一个非常大的不一样—— Owner状态下的数据是dirty的,还没有写回内存,Forward状态下的数据是clean的,可以丢弃而不用另行通知。
需要说明的是,AMD用MOESI,Intel用MESIF。所以,F 状态主要是针对 CPU L3 Cache 设计的(前面我们说过,L3是所有CPU核心共享的)。
四、程序性能 (对这部分没有完全理解)
了解了我们上面的这些东西后,我们来看一下对于程序的影响。
示例一
首先,假设我们有一个64M长的数组,设想一下下面的两个循环:
const int LEN = 64*1024*1024;
int *arr = new int[LEN];
for (int i = 0; i < LEN; i += 2) arr[i] *= i;
for (int i = 0; i < LEN; i += 8) arr[i] *= i;
按我们的想法,第二个循环要比第一个循环少4倍的计算量。其应该要快4倍的。但实际跑下来并不是,在我的机器上,第一个循环需要128毫秒,第二个循环则需要122毫秒,相差无几。这里最主要的原因就是 Cache Line,因为CPU会以一个Cache Line 64Bytes最小时单位加载,也就是16个32bits的整型,所以,无论你步长是2还是8,都差不多。而后面的乘法其实是不耗CPU时间的。
示例二
接下来,我们再来看个示例。下面是一个二维数组的两种遍历方式,一个逐行遍历,一个是逐列遍历,这两种方式在理论上来说,寻址和计算量都是一样的,执行时间应该也是一样的。
const int row = 1024;
const int col = 512
int matrix[row][col];
//逐行遍历
int sum_row=0;
for(int _r=0; _r<row; _r++) {
for(int _c=0; _c<col; _c++){
sum_row += matrix[_r][_c];
}
}
//逐列遍历
int sum_col=0;
for(int _c=0; _c<col; _c++) {
for(int _r=0; _r<row; _r++){
sum_col += matrix[_r][_c];
}
}
然而,并不是,在我的机器上,得到下面的结果。
逐行遍历:0.083ms
逐列遍历:1.072ms
执行时间有十几倍的差距。其中的原因,就是逐列遍历对于CPU Cache 的运作方式并不友好,所以,付出巨大的代价。
示例三
接下来,我们来看一下多核下的性能问题,参看如下的代码。两个线程在操作一个数组的两个不同的元素(无需加锁),线程循环1000万次,做加法操作。在下面的代码中,我高亮了一行,就是p2指针,要么是p[1],或是 p[30],理论上来说,无论访问哪两个数组元素,都应该是一样的执行时间。
void fn (int* data) {
for(int i = 0; i < 10*1024*1024; ++i)
*data += rand();
}
int p[32];
int *p1 = &p[0];
int *p2 = &p[1]; // int *p2 = &p[30];
thread t1(fn, p1);
thread t2(fn, p2);
然而,并不是,在我的机器上执行下来的结果是:
对于 p[0] 和 p[1] :570ms
对于 p[0] 和 p[30]:105ms
这是因为 p[0] 和 p[1] 在同一条 Cache Line 上,而 p[0] 和 p[30] 则不可能在同一条Cache Line 上 ,CPU的缓存最小的更新单位是Cache Line,所以,这导致虽然两个线程在写不同的数据,但是因为这两个数据在同一条Cache Line上,就会导致缓存需要不断进在两个CPU的L1/L2中进行同步,从而导致了5倍的时间差异。
参考帖子:
https://blog.csdn.net/qq_41413211/article/details/130087712
https://www.cnblogs.com/cdaniu/p/15598997.html ------ 总结的非常好例子
https://www.zhihu.com/question/24565362/answer/3355730698

 浙公网安备 33010602011771号
浙公网安备 33010602011771号