

linux内核目前实现了6中调度策略(即调度算法), 用于对不同类型的进程进行调度, 或者支持某些特殊的功能,其中SCHED_NORMAL和SCHED_BATCH调度普通的非实时进程, SCHED_FIFO和SCHED_RR和SCHED_DEADLINE则采用不同的调度策略调度实时进程, SCHED_IDLE则在系统空闲时调用idle进程.

上面说的CFS全程是CFS(Completely fair schedule).
下面是对上面表格中三种算法进一步的解释:
SCHED_FIFO: 先进先出调度在先进先出的调度方式下,一个线程直到它被更高优先级的线程抢占或者运行结束,才会交出控制权。相同优先级的任务不能打断该线程。当线程完成后,内核会去寻找处于就绪状态相同优先级的线程,如果不存在, 则寻找低优先级线程。FIFO调度本身实现了数据的互斥, 在线程运行的时间内其他相同优先级线程无法进行资源抢占。
SCHED_RR: 时间片轮转调度在时间片轮转(RR: RoundRobin)调度下,一个线程放弃内核有三种情况:运行结束,被更高级优先级抢占或者消耗完自己的时间片。时间片是线程运行的最小时间单元,由操作系统预先设定。当时间片用完时,该线程自动交出控制权, 之后内核会按照和FIFO相同的方式搜索下一个工作线程。轮转调度可以防止某一个任务连续占用太多的资源,而导致其他线程信息得不到及时处理。缺点是轮转调度会增大由于任务切换而导致的开销。
SCHED_OTHER: 分时调度,一般采用CFS算法,CFS定义了一种新调度模型,它给cfs_rq(cfs的run queue)中的每一个进程都设置一个虚拟时钟-virtual runtime(vruntime)。如果一个进程得以执行,随着执行时间的不断增长,其vruntime也将不断增大,没有得到执行的进程vruntime将保持不变。
而调度器将会选择最小的vruntime那个进程来执行。这就是所谓的“完全公平”。不同优先级的进程其vruntime增长速度不同,优先级高的进程vruntime增长得慢,所以它可能得到更多的运行机会。
Linux 进程的优先级跟随调度算法的不断发展,其意义在不同的阶段也有着不同的含义,所以本来想从 Linux 的调度发展史写起,但是无奈那一部分的涉猎不是很深入。不管怎样,发展到最后,结果是 Linux 系统可以在同一个系统上扩展多个调度算法,于是在同一个系统上面优先级也有了不同的含义,本文只对较新的 Linux 系统(4.4)的优先级做一个基本介绍,这个过程需要逐步深入,前面的一坨看起来与优先级不相关的东西并不是废话,别说话,耐心看。
字义上的优先级
所谓优先级就字面的意思来看就是事情的紧急程度,虽说有一个先来后到的说法,但是优先级则打破了这一规则。在可抢占的操作系统上面,高优先级的进程可以在后来者的情况下优先占据 cpu 的使用权,而更低优先级的进程则只能选择被动出让 cpu,无论其是否心甘情愿,也就是不管它的事情有咩有完成,都得让路给高优先级的进程。
通常意义上来讲,我们平时说优先级也正是指的上面字面意义上的优先级,代表对 cpu 的优先使用级别,高优先级的进程先使用,低优先级的进程后使用。对于没有时间片限制的一些调度算法来说,只有最高优先级的进程主动让出 cpu(完成它自己的工作),次低一点优先级的进程才可以获取 cpu 使用权。而对于有时间片限制的调度算法,优先级高的进程则代表它优先、较多地享有 cpu 使用权,注意:优先、较多。它意味着可能不等到高优先级任务主动出让 cpu,就会被强制切换到更低一点优先级的进程,但是总体来说,高优先级的进程会有比其它进程更多的 cpu 使用时间。

内核角度看优先级
在内核里面 task_struct 用于描述进程的各个属性,属于进程的结构体抽象,其中有几个字段如下:
-
struct task_struct {
-
... ...
-
int prio, static_prio, normal_prio;
-
unsigned int rt_priority;
-
... ...
-
}
可以看到内核里面的优先级有一坨,分别记录为:
- prio:动态优先级。,该值使用 effective_prio 函数进行计算,在 CFS 类或者 EDF 类的调度策略中与 normal_prio 是一致的,在 RT 策略当中就直接返回当前的动态优先级值(其值与静态优先级相同),该值主要是用于在运行过程中动态改变程序优先级的值,保证调度的公平性,低优先级的进程在长时间得不到运行状况下会暂时调高其动态优先级,这个计算过程比较复杂,这里不深入。
- static_prio:静态优先级。只有 CFS 类的才有静态优先级,其他的类在内核当中也为其设置了该成员,但是并没有实际的物理意义,**也就是静态优先级只有在 CFS 类中才有其实际的作用,其它的只是个幌子。**该值的计算方式是通过一个宏定义来完成:#define NICE_TO_PRIO(nice) ((nice) + DEFAULT_PRIO),展开之后就是 nice + (100+(19-(-20)+1)/2)。
- normal_prio:归一化优先级。所谓归一化就是统一的意思,因为对于不同的调度类来说,它们的优先级的概念是不一样的,但是对于内核来说,它需要一个简单的概念来区分归根结底到底是谁的优先级更高一点。可以理解为不同的调度类优先级就是不同国家的货币,归一化优先级就是黄金,把不同国家的货币(不同调度类)转换为等量黄金,之后才能够比较到底谁才是土豪(谁拥有优先调度权)。
- rt_priority:RT 调度算法类的优先级,其值与用户空间传进来的值一致(用户空间使用 sched_setparam 等函数传递),取值范围 1~99.
在内核的 INIT_TASK 宏定义中可以看到上面三个值初始化默认都是 MAX_PRIO-20,也就是 120.后面有一张表列出了不同调度类情况下的归一化优先级的计算方法与值的范围。内核里面的归一化优先级值越小,代表实际优先级越高,目前最小的值是 -1
DEADLINE 调度类
该调度类在目前的 Linux 内核里面属于优先级最高的调度类,也就是说假设系统上面存在多个调度类,那么每次重新调度的时候,都是先从该调度类下面去找到一个可以投入运行的进程进行调度。归属于该调度类的进程其归一化优先级都是 -1,在该调度类内部不再区分多个优先级,统一归为 -1.
如果要切换某一个进程的调度类到 DEADLINE,那么就采用 sched_setattr 函数进行设置,大概的方式如下(由于本文章不讨论调度类的使用与原理,此处简略若干):
-
struct sched_attr attr;
-
-
memset(&attr, 0, sizeof(attr));
-
attr.size = sizeof(attr);
-
-
/* This creates a 200ms / 1s reservation */
-
attr.sched_policy = SCHED_DEADLINE;
-
attr.sched_runtime = 20*1000*1000;
-
attr.sched_deadline = attr.sched_period = 33*1000*1000;
-
ret = sched_setattr(0, &attr, flags);
内核里面关于该调度类优先级的一个宏定义是:MAX_DL_PRIO,它的值是0,转换为归一化优先级就是 -1.目前为止,这个归一化优先级值的优先级最高。
FIFO、RR 等 RT 调度类
从内核的定义中可以看到宏定义:
可以看到它的优先级最大是 100,转换之后就是 99(内核要减去1),也就是 RT 类型的调度类优先级范围在 0~99 之间,该调度类可以采用 sched_setparam 函数来完成优先级的设置,该函数的参数是 pid 号与一个叫做 sched_param 的结构体,该结构体只有一个参数,那就是优先级的值,该值越大(用户空间值越大优先级越高)表示优先级越高,值范围是 1~99(对原文这里尚有疑问,是否应该是1~100?),但需要注意的是从内核的角度来看归一化优先级的值越小,优先级才越高,而在用户user 空间设置的这个值是与内核里面的值是翻转着来的,值越大优先级越高。
上面 task_struct->rt_priority 成员的值就是 sched_setparam 函数第二个参数的 sched_priority 成员传递的值。
CFS 调度类
主要就是 NORMAL/OTHER,BATCH 这两种调度类。它们的优先级可以通过 setpriority 函数来进行设置,可以设置的范围是 -20~19,需要注意的是这个范围指的是 nice 值,它与优先级有一定的区别(详情参考后面),分别对应内核里面的归一化优先级 100~139.
在 CFS 调度算法中,优先级并不会特别大地影响到程序被调用的先后顺序,在这种调度算法当中,优先级影响最大的是 cpu 使用时间,优先级越高可以占有的 cpu 使用时间就相对越多。所以如果拼命提高某些进程的优先级,最后发现它的实时性还不是很好,那不是因为优先级失效了,而是因为使用不当,要想提高程序的响应速度与实时性,最好是将它设置为 RT 调度类。
上述的有些调度类如果是在 ubuntu 桌面版上面做的实验,有些可能是不起作用的,因为 ubuntu 系统对非 root 用户的权限做了限制,比如优先级减少不能增加,调度类也不能随意更换(内核相关的选项没有被编译进去等),切换到 root 用户就可以正确地得到部分实验效果。
调度类的优先级
在内核里面,调度类的优先级顺序如下所示:
SCHED_DEADLINE > SCHED_FIFO/SCHEDRR > SCHED_NORMAl/SCHED_OTHER/SCHED_BATCH > SCHED_ID
区分一下调度类的优先级与进程的优先级,调度类包含了归属其下的进程,优先级高的调度类所包含的进程自然会被优先调度,然后在调度类内部才会进一步区分进程的优先级,其中优先级高的调度类中的进程总是会优先于优先级低的调度类中的进程被调度。比较绕,简单说调度顺序的选择有两个层级,调度类是第一层,进程是第二层。
对于使用同一种调度算法的调度类(RT、EDF、CFS),其调度类的优先级是一样的,实际调度中会在这几个调度类内部找到优先级比较高的进程去进行下一次调度,也就是优先级高的先调度。需要注意的是,就算是属于同一个调度算法的调度类,其实现上也有所不同,进程的调度行为也有所不同(比如 SCHED_RR 与 SCHED_FIFO 的调度行为有所不同),但是优先级的概念一定是统一的。
看下内核里面是怎样计算归一化优先级的
static inline int normal_prio(struct task_struct *p)
{
int prio;
if (task_has_dl_policy(p)) -------sched_deadline
prio = MAX_DL_PRIO-1;
else if (task_has_rt_policy(p)) --------sched_fifo/schedRR
prio = MAX_RT_PRIO-1 - p->rt_priority;
else
prio = __normal_prio(p);
return prio;
}
如果是 DEADLINE 调度类,那么它的归一化优先级就是 MAX_DL_PRIO-1,也就是 -1, MAX_DL_PRIO这个定义为0.
如果是实时的调度类,它的优先级是 MAX_RT_PRIO-1 - p->rt_priority,范围是 0~98(没有 99 的原因是 rt_priority 的取值范围是 1~99),
如果是 CFS 调度类,那么归一化优先级就和静态优先级是相等的,计算公式上面给出过,是一个叫 NICE_TO_PRIO 的宏定义完成计算的,这里再重复下:
#define MAX_NICE 19
#define MIN_NICE -20
#define NICE_WIDTH (MAX_NICE - MIN_NICE + 1) //40
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
#define MAX_PRIO (MAX_RT_PRIO + NICE_WIDTH) //140
#define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH / 2) //120
#define NICE_TO_PRIO(nice) ((nice) + DEFAULT_PRIO) //120
#define PRIO_TO_NICE(prio) ((prio) - DEFAULT_PRIO)
展开之后就是:静态优先级=nice值+MAX_USER_RT_PRIO+(MAX_NICE - MIN_NICE + 1)/2,带入计算一下就知道范围是 100~139(内核里面的 nice 取值范围是 -20~19).
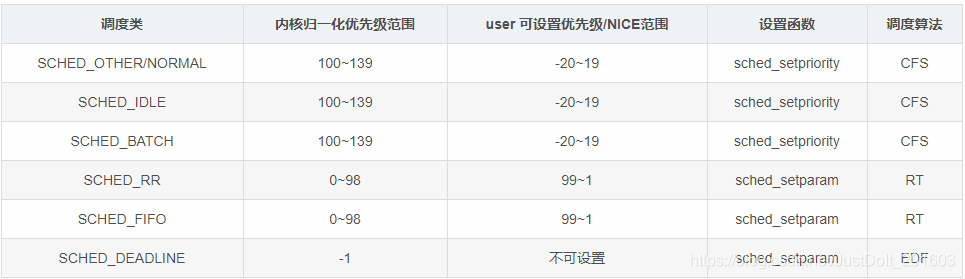
可以注意到 RT 调度类有一个奇怪的问题,它的范围是 0~98,而不是 0~99,至于它的历史来由是什么我也不清楚,这里只是指出这个现象。另外前期 Linux 对不同的调度类极其优先级有一大堆的不同设置函数,从上表就可以看得出,后来在 DEADLINE 加入之后,估计是开发人员也受不了记忆这么多的函数,于是有了一个万能的函数:sched_setattr,在系统里面可能找不到这个函数实现,使用 __NR_sched_setattr 系统调用号结合 syscall 就可以自行实现,该系统调用的第二个参数 sched_attr 如下所示(不解释了,很容易看懂它是如何统一各个调度类的设置的):
struct sched_attr {
u32 size;
u32 sched_policy;
u64 sched_flags;
/* SCHED_NORMAL, SCHED_BATCH */
s32 sched_nice;
/* SCHED_FIFO, SCHED_RR */
u32 sched_priority;
/* SCHED_DEADLINE */
u64 sched_runtime;
u64 sched_deadline;
u64 sched_period;
};
用户空间的 NI,PRI
除了内核空间里面繁杂、错综的优先级概念,在用户空间也有一些容易混淆的概念,它们之间有着某种联系,这里主要就说用户空间使用 htop 或者 top 命令看到的 NI 与 PRI 值是怎么一回事儿。
NI 就是 nice 值,顾名思义,就是这个进程的友好程度,越友好的程序 NI 值越大(取值范围 -20~19),也就越慷慨,它们会使用相对较少的 cpu 时间,所谓优先级低;而不那么友好的进程则使用相对较多的 cpu 时间,所谓优先级高。很怀疑起这个名字(nice)这是内核开发者的恶趣味,老实人就一定要慷慨,要付出更多,坏人就可以得到更多。由此可见,nice 值代表了可以使用的 cpu 资源的比例。
PRI 就是优先级,这个优先级不对应内核里面任何一个优先级的概念,可以看到它的值跟随 NI 值不断变化,在 CFS 调度时关系看起来就像是:PRI = 20+NI。实际上:PRI(new)=PRI(old)+nice,用户空间的进程刚初始化是默认都是 PRI=20,NI=0,当 NI 的值改变的时候,PRI 的值就显而易见。
在用户空间,我们想要设置某一个进程的 nice 值,那么这个进程一定是 CFS 调度算法下面的调度类,否则无意义,如果想让这个程序尽可能优先的运行,那么通过 nice 值修改可能并不会得到想象中的效果,更好的办法是提升进程的调度类,比如从 SCHED_OTHER 升级到 SCHED_RR。如果想让自己的进程尽可能多地使用 cpu 时间,那么减少 nice 值就是一个很好的选择。
End
Linux 里面优先级绝不是那么简单就可以区分的,并且在使用的时候很可能会误用,需要针对内核角度、用户空间角度对优先级有一个全面的了解才能够更好地去使用它。本文的文字比较多,要想更加细致的理解就需要自己动手操作一番,在不同的调度类里面辗转腾挪一波,调调优先级,改改 nice 值就很容易理解这些概念了。
在/usr/src/kernels/4.18.0-394.el8.x86_64/include/linux/sched/prio.h
#ifndef _SCHED_PRIO_H
#define _SCHED_PRIO_H
#define MAX_NICE 19
#define MIN_NICE -20
#define NICE_WIDTH (MAX_NICE - MIN_NICE + 1)
下面这句话的意思:整个进程的优先级范围是0-139. RT优先级范围是0-99. 而 SCHED_NORMAL/SCHED_BATCH线程的优先级范围是100--139. 并且优先级值越低,表示优先级越高。
/*
* Priority of a process goes from 0..MAX_PRIO-1, valid RT
* priority is 0..MAX_RT_PRIO-1, and SCHED_NORMAL/SCHED_BATCH
* tasks are in the range MAX_RT_PRIO..MAX_PRIO-1. Priority
* values are inverted: lower p->prio value means higher priority.
*
* The MAX_USER_RT_PRIO value allows the actual maximum
* RT priority to be separate from the value exported to
* user-space. This allows kernel threads to set their
* priority to a value higher than any user task. Note:
* MAX_RT_PRIO must not be smaller than MAX_USER_RT_PRIO.
*/
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
#define MAX_PRIO (MAX_RT_PRIO + NICE_WIDTH)
#define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH / 2)
/*
* Convert user-nice values [ -20 ... 0 ... 19 ]
* to static priority [ MAX_RT_PRIO..MAX_PRIO-1 ],
* and back.
*/
#define NICE_TO_PRIO(nice) ((nice) + DEFAULT_PRIO)
#define PRIO_TO_NICE(prio) ((prio) - DEFAULT_PRIO)
/*
* 'User priority' is the nice value converted to something we
* can work with better when scaling various scheduler parameters,
* it's a [ 0 ... 39 ] range.
*/
#define USER_PRIO(p) ((p)-MAX_RT_PRIO)
#define TASK_USER_PRIO(p) USER_PRIO((p)->static_prio)
#define MAX_USER_PRIO (USER_PRIO(MAX_PRIO))
/*
* Convert nice value [19,-20] to rlimit style value [1,40].
*/
static inline long nice_to_rlimit(long nice)
{
return (MAX_NICE - nice + 1);
}
/*
* Convert rlimit style value [1,40] to nice value [-20, 19].
*/
static inline long rlimit_to_nice(long prio)
{
return (MAX_NICE - prio + 1);
}
#endif /* _SCHED_PRIO_H */
程序的优先级范围为[0,139],有效的实时优先级(RT priority)范围为[0,99],SCHED_NORMAL和SCHED_BATCH这两个非实时任务的优先级为[100,139]。[100,139]这个区间的优先级又称为静态优先级(static priority)。之所以称为静态优先级是因为它不会随着时间而改变,内核不会修改它,只能通过系统调用nice去修改。静态优先级用进程描述符中的static_prio表示。优先级的值越低,表示具有更高的优先级,0的优先级最高。

一个进程可以间接地通过使用进程的nice级别来改变静态优先级。一个具有更高级别的静态优先级进程会具有更长的时间片(进程在一个处理器上运行多长时间)。也就说,在用户空间通过nice命令设置进程的静态优先级, 这在内部会调用nice系统调用, 进程的nice值在-20~+19之间. 值越低优先级越高。setpriority系统调用也可以用来设置进程的优先级。它不仅能够修改单个线程的优先级, 还能修改进程组中所有进程的优先级, 或者通过制定UID来修改特定用户的所有进程的优先级

Top中的PR和NI
top中的PR表示优先级,但是跟上述的值不是直接对等的。在top中,实时优先级的[0,99]没有具体的表示,统一用RT来表示。而静态优先级和top中的优先级关系为
top_PR = static_Priority - 100。 其中static_priority==Nice+120. 所以当Nice==0的时候,top中PR==20. 进一步也就是说对于静态优先级,top中PR==Nice+20.也就是说,top中的PR取值为[0,39],对应图1的优先级[100,139]
top中的NI表示nice等级,nice的取值为[-20,19],对应图1中的优先级为[100,139],也就是说nice等级可以改变用户进程(非实时进程的优先级)。在top界面中,输入r即可启动nice系统,先输入进程id,回车后再输入nice等级即可修改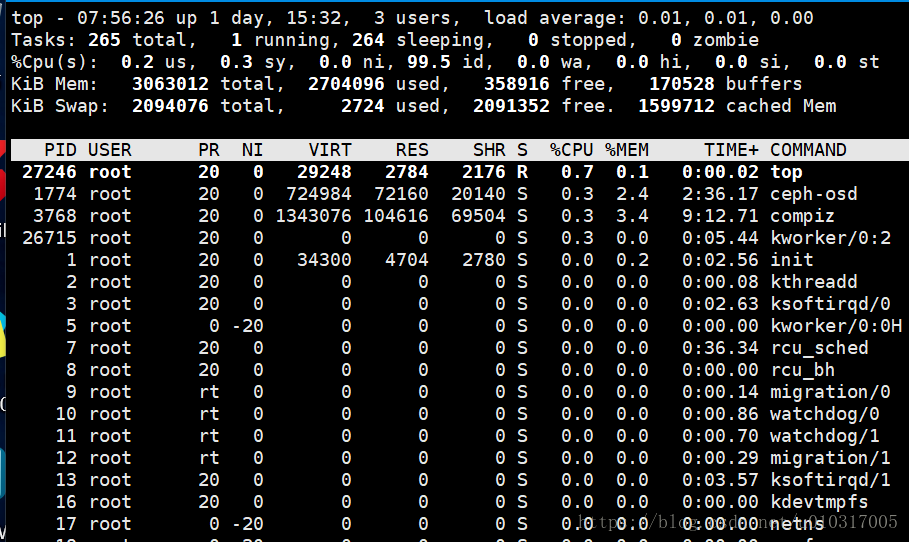
修改了nice等级的top进程
ps中的PRI
ps中的PRI也是表示优先级,通过ps -el可以显示出来,例如
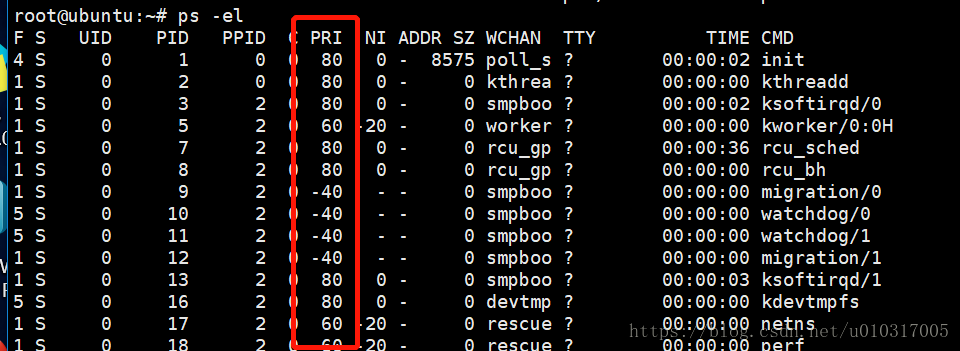
这里的PRI与图1 中的优先级关系为
ps_PRI = static_priority - 40
这边PRI的取值范围为[-40,99],也就是说,ps中PRI值为80等价于nice值为0,等价于静态优先级的120。
我觉得到这应该对linux 里面线程的优先级有了一定的理解。不一定非得要弄清楚htop里面显示的pri为什么会反转。
————————————————
版权声明:本文为CSDN博主「oba没有马」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u010317005/article/details/80531985
转载:
https://blog.csdn.net/JustDoIt_201603/article/details/103040345 -----本篇要是在后面对用htop看到的优先级显示为负的在进行说明下就更好了。
————————————————
版权声明:本文为CSDN博主「pizziars」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/pizziars/article/details/127237337

 浙公网安备 33010602011771号
浙公网安备 33010602011771号