

开始学Java的时候,听到好多都说Java编程不用考虑内存管理,比C方便多了。但是后来看一些基础知识,发现不了解Java各个部分内存分布,有些概念很难理解。
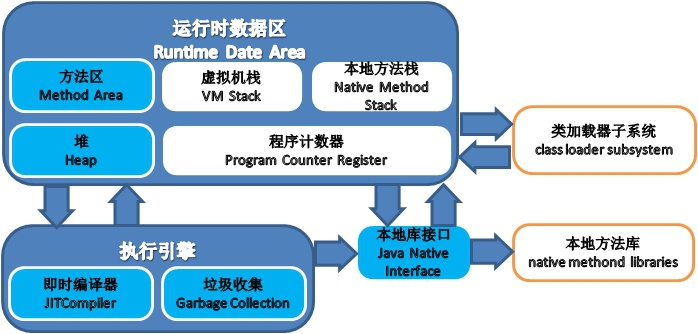
JVM内存分为5个部分:方法区,JVM堆,JVM栈,本地方法栈,程序计数器。
程序计数器:线程私有,用于记录当前线程执行的位置。用于切换回来之时的程序入口。
本地方法栈:线程私有,用于本地native方法运行,本地方法被执行的时候,在本地方法栈会创建一个栈帧,用于存放本地方法的局部变量表、操作数栈、动态链接、出口信息。
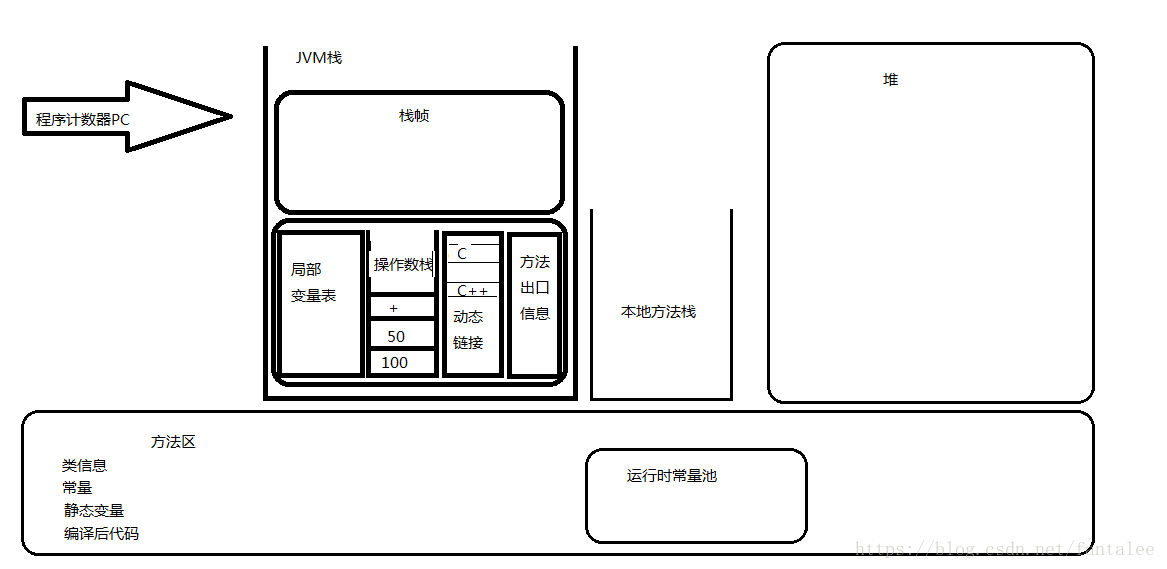
JVM栈:线程私有,它的生命周期与线程相同。描述的是java方法执行的内存模型:每个方法在执行的同时创建一个栈帧,用于存放局部变量表,操作数栈,方法入口,动态链接
等。每一个方法被调用直至执行完成的过程,就对应着一个栈帧在 虚拟机栈中从入栈到出栈的过程。
局部变量表用来存放一些基本数据类,和引用。操作数栈的话,是用来作运算用的。
局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用和returnAddress 类型。局部变量表所需的内存空间在
编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
JVM堆:线程共享,在虚拟机启动时创建。存放对象实例,几乎所有的对象实例都在这里分配内存。所有的对象实例以及数组都要在堆上分配。Java垃圾回收也主要是指处理堆。
方法区:线程共享,它用于存 储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
方法区中的信息一般需要长期存在,回收一遍内存之后可能只有少量垃圾。对方法区的内存回收的主要目标是:对常量池的回收 和 对类型的卸载。
运行时常量池:(Runtime Constant Pool)是方法区的一部分。Class 文件中除了有类的版本、字段、方法、接口等描述等信息外,还有一项信息是常量池(Constant PoolTable),
用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后存放到方法区的运行时常量池中
Object obj = new Object();假设这句代码出现在方法体中,那“Object obj”这部分的语义将会反映到Java 栈的本地变量表中,作为一个reference 类型数据出现。而“new Object()”这部分的语义将会反映到Java 堆中,形成一块存储了Object 类型所有实例数据值(Instance Data,对象中各个实例字段的数据)的结构化内存,根据具体类型以及虚拟机实现的对象内存布
局(Object Memory Layout)的不同,这块内存的长度是不固定的。
由于reference 类型在Java 虚拟机规范里面只规定了一个指向对象的引用,并没有定义这个引用应该通过哪种方式去定位,以及访问到Java 堆中的对象的具体位置,因此
不同虚拟机实现的对象访问方式会有所不同,主流的访问方式有两种:使用句柄和直接指针。具体可以参考博文:https://www.cnblogs.com/dingyingsi/p/3760447.html
相当于是堆内部结构不同的划分。
堆区:
1.存储的全部是对象,每个对象都包含一个与之对应的class的信息。(class的目的是得到操作指令)
2.jvm只有一个堆区(heap)被所有线程共享,堆中不存放基本类型和对象引用,只存放对象本身
栈区:
1.每个线程包含一个栈区,栈中只保存基础数据类型的对象和自定义对象的引用(不是对象),对象都存放在堆区中
2.每个栈中的数据(原始类型和对象引用)都是私有的,其他栈不能访问。
下面举一个例子:
1 package lesson; 2 3 public class JVMDemo {//运行时, jvm 把JVMDemo的信息都放入方法区 4 private static int n = 0; //static静态变量存入方法区 5 private final int m=1; //final常量存入方法区 6 7 public static void main(String[] args) { //main 方法本身放入方法区。 8 9 Test test = new Test("Test 1");//test是引用,所以放到栈区里, Test是自定义对象应该放到堆里面 10 Test test1 = new Test("Test 2"); 11 test.printname(); 12 test1.printname(); 13 } 14 } 15 16 class Test{//运行时, jvm 把Test的信息都放入方法区 17 private String name; //new Test实例后, name 引用放入栈区里, name 对象放入堆里 18 19 public Test(String name) { 20 super(); 21 this.name = name; 22 } 23 24 public void printname(){ //printname方法本身放入 方法区里。 25 System.out.println("name is "+ this.name); 26 } 27 }
启动了一个Java虚拟机进程,这个进程首先从classpath中找到JVMDemo.class文件,读取这个文件中的二进制数据,然后把Appmain类的类信息存放到运行时数据区的方法区中。这一过程称为AppMain类的加载过程。接着,Java虚拟机定位到方法区中JVMDemo类的Main()方法的字节码,开始执行它的指令。这个main()方法的第一条语句就是:
Test test=new Test("测试1");
让java虚拟机创建一个Sample实例,并且呢,使引用变量test1引用这个实例。让我们来跟踪一下Java虚拟机,看看它究竟是怎么来执行这个任务的:
1、
Java虚拟机一看,不就是建立一个Test实例吗,简单,于是就直奔方法区而去,先找到Test类的类型信息再说。但是方法区里还没有Test类呢。可Java虚拟机也不是一根筋的笨蛋,于是,立马加载了Sample类,把Sample类的类型信息存放在方法区里。
2、 信息找到了。Java虚拟机做的第一件事情就是在堆区中为一个新的Test实例分配内存,
这个Test实例持有着指向方法区的Test类的类型信息的引用。这里所说的引用,实际上指的是Test类的类型信息在方法区中的内存地址,而这个地址呢,就存放了在Test实例的数据区里。
3、
在JAVA虚拟机进程中,每个线程都会拥有一个方法调用栈,用来跟踪线程运行中一系列的方法调用过程,栈中的每一个元素就被称为栈帧,每当线程调用一个方法的时候就会向方法栈压入一个新帧。这里的帧用来存储方法的参数、局部变量和运算过程中的临时数据。OK,原理讲完了,就让我们来继续我们的跟踪行动!位于“=”前的test是一个在main()方法中定义的变量,可见,它是一个局部变量,因此,它被会添加到了执行main()方法的主线程的JAVA方法调用栈中。而“=”将把这个test变量指向堆区中的Test实例,也就是说,它持有指向Test实例的引用。
接下来,JAVA虚拟机将继续执行后续指令,在堆区里继续创建另一个Test实例,然后依次执行它们的printname()方法。当JAVA虚拟机执行test1.printName()方法时,JAVA虚拟机根据局部变量test1持有的引用,定位到堆区中的Test实例,再根据Test实例持有的引用,定位到方法去中Sample类的类型信息,从而获得printname()方法的字节码,接着执行printname()方法包含的指令。
上面这部分参考https://www.cnblogs.com/dingyingsi/p/3760730.html
通过上面的了解,应该知道整个程序是在JVM中如何分配内存的了,也大概知道程序是跑在哪一块了。如果理解有错误请指正。
栈的大小可以通过-XSs设置,如果不足的话,会引起java.lang.StackOverflowError的异常
- 堆得内存由-Xms指定,默认是物理内存的1/64;最大的内存由-Xmx指定,默认是物理内存的1/4。
- 默认空余的堆内存小于40%时,就会增大,直到-Xmx设置的内存。具体的比例可以由-XX:MinHeapFreeRatio指定
- 空余的内存大于70%时,就会减少内存,直到-Xms设置的大小。具体由-XX:MaxHeapFreeRatio指定。
因此一般都建议把这两个参数设置成一样大,可以避免JVM在不断调整大小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号