
深入拷贝构造和运算符的重载
1、复习
1.1 指针s是否加const以及const位置不同的引用
int *s = &a;
int main()
{
int a = 10, b = 20;
int *s = &a;
int *p = s;
int *&p1 = s;
const int *&p2 = s; //error
int *const &p3 = s;
const int *const p4 = s;
}
int const *s = &a 等同于const int *s = &a
int main()
{
int a = 10, b = 20;
int const *s = &a;
int *p = s;
int *&p1 = s;
const int *&p2 = s;
int *const &p3 = s;
const int *const p4 = s;
}
int *const s = &a;
int main()
{
int a = 10, b = 20;
int* const s= &a;
int *p = s;
int *&p1 = s;
const int *&p2 = s;
int *const &p3 = s;
const int *const p4 = s;
}
1.2 引用数组
int main()
{
int arr[10] = {19,23,66,32,32,1,3,32,1,10};
int &a = arr[0]; //引用数组的某个元素
int &b = arr; //error:b去引用a。与构成数组的要素不同,数组名 + 数组长度。
//指针数组
int(*p)[10] = &arr; //首先是一个指针,大小是10。类型 + 大小
//引用数组
int (&br)[10] = arr;
}
问题1:那么引用数组的含义是什么呢?
回答:可以和模板函数结合来进行对数组的操作。
二、模板函数的定义
有以下函数,要求分别打印处数组ar和dx,并且只能有一个函数。
int main()
{
int ar[] = { 12,23,34,45,56,67,78 };
double dx[] = { 1.2,2.3,3.4,4.5,5.6,6.7,7.8 };
Print_Ar(ar);
Print_Ar(dx);
return 0;
}
这个应该怎么实现呢,我们都知道C++中函数是通过命名规则来识别的,是由返回值 + 函数名 + 形参构成的一套规则。我们想使用Print_Ar函数来打印ar数组和dx数组的全部内容,但是接口只是将数组名传递给函数本身,并没有传递数组长度。我们知道,在C语言中,如果需要打印数组一定要传递 数组名 和 数组长度 。(但是如果我们并不知道数组长度)。那么我们该如何定义Print_Ar函数呢?我们通过模板来定义Print_Ar函数。
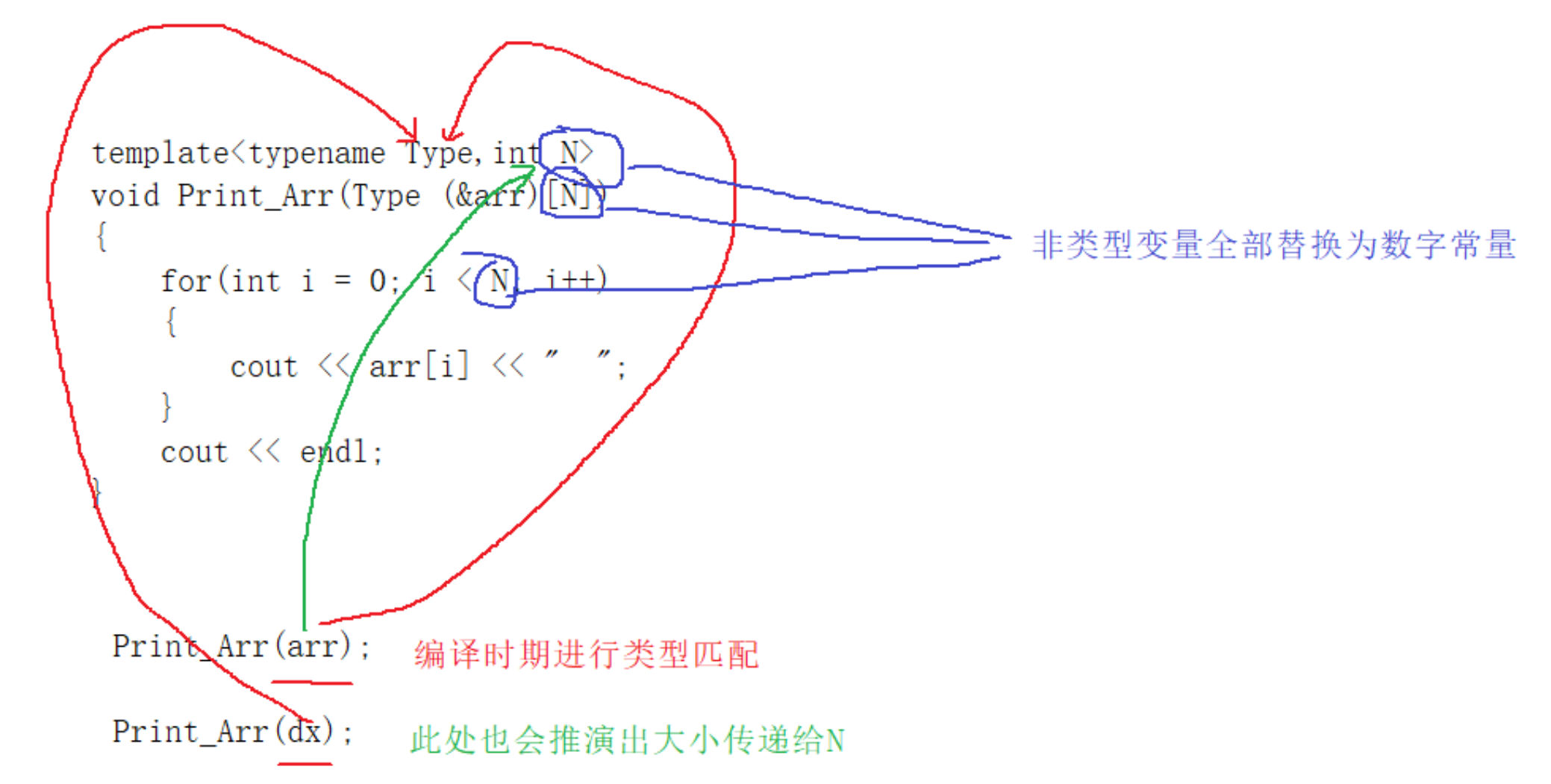
2.1 类型与非类型的处理方式
template<typename Type,int N> //类型概念,非类型概念
void Print_Arr(Type (&arr)[N])
{
for(int i = 0; i < N; i++)
{
cout << arr[i] << " ";
}
cout << endl;
}
上面就是一个模板函数,我们要分清一个重要的概念:类型概念 和 非类型概念。
首先我们看模板的定义:template<typename Type,int N>
- 类型概念:template Type
- 非类型概念:int N
模板有一个重要的特点:对类型和非类型采取了不同的识别方案。
这个是什么意思呢?我们深入模板的本质去理解。上述代码为Print_Arr函数的定义,它在编译的时候会实例化,并且进行模板推演过程,首先类型概念会自动将int 和 double类型 替换进模板函数中;非类型变量在替换过程中类似于宏,会将原先变量存在的地方进行值替换。如下:
//处理 int类型数组 的函数
typedef int Type;
void Print_Arr<int ,7>(Type(&arr)[7]) //N被7替换
{
for(int i = 0; i < 7; i++) //N被7替换
{
cout << arr[i] << " ";
}
cout << endl;
}
//处理double类型数组的函数
typedef double Type;
void Print_Arr<double,7>(Type(&arr)[7]) //N被7替换
{
for(int i = 0; i < 7; i++) //N被7替换
{
cout << arr[i] << " ";
}
cout << endl;
}
三、左值引用、右值引用、将亡值引用
首先我们引入这几个概念:
lvalue左值 xvalue rvalue右值 prvalue 纯右值
3.1左值
左值:凡是可以寻址的值(可以对他取地址)
const int b = 20;
//b 左值,可以&b;
3.2 右值
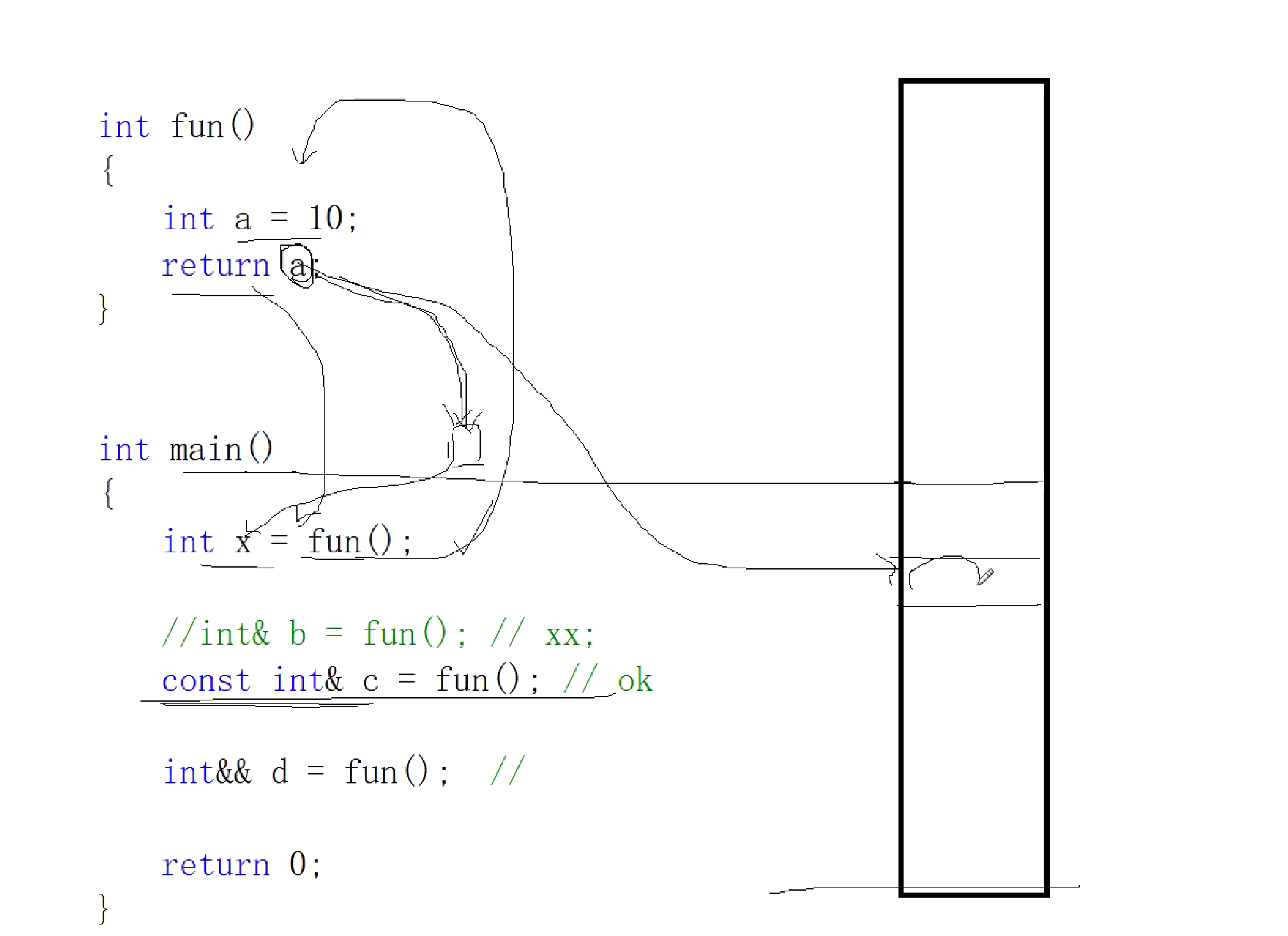
将亡值引用

int x = fun();
//int& b = fun(); //error ?
const int& c = fun(); //right:常引用
int&& d = fun(); //right:右值引用

int x = fun()
在此处我们将临时量a的值赋值给x。这样做没有任何问题。
我们在调动的时候也会产生一个临时变量。
const int &c = fun()
在当常引用引用的时候,我们不会创建一个临时变量存储a的值,而是直接将a放入到主函数的栈帧空间,并且用c来引用这个空间,以常引用接收这个空间也就意味着这个值不可改变。
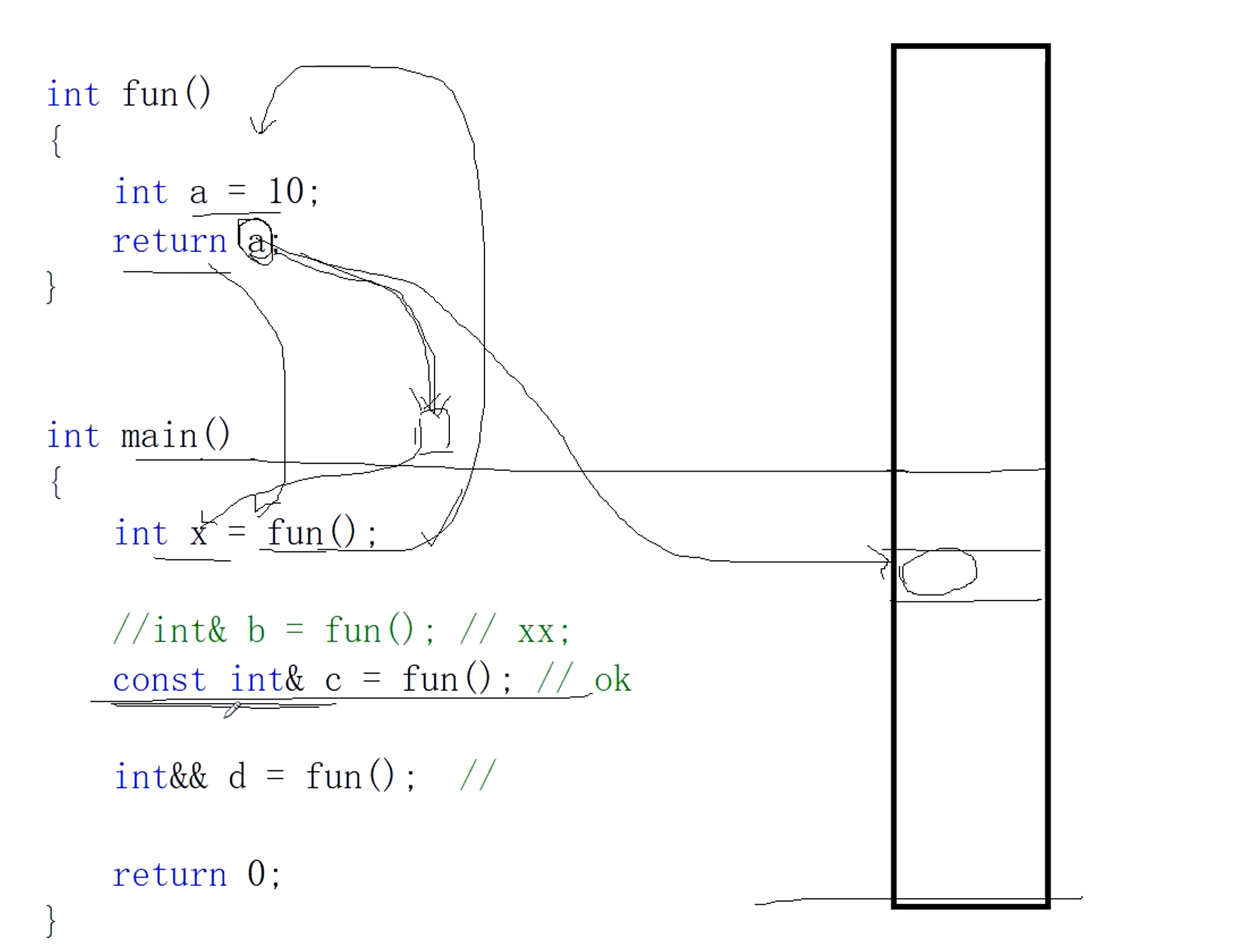
int &&d = fun()
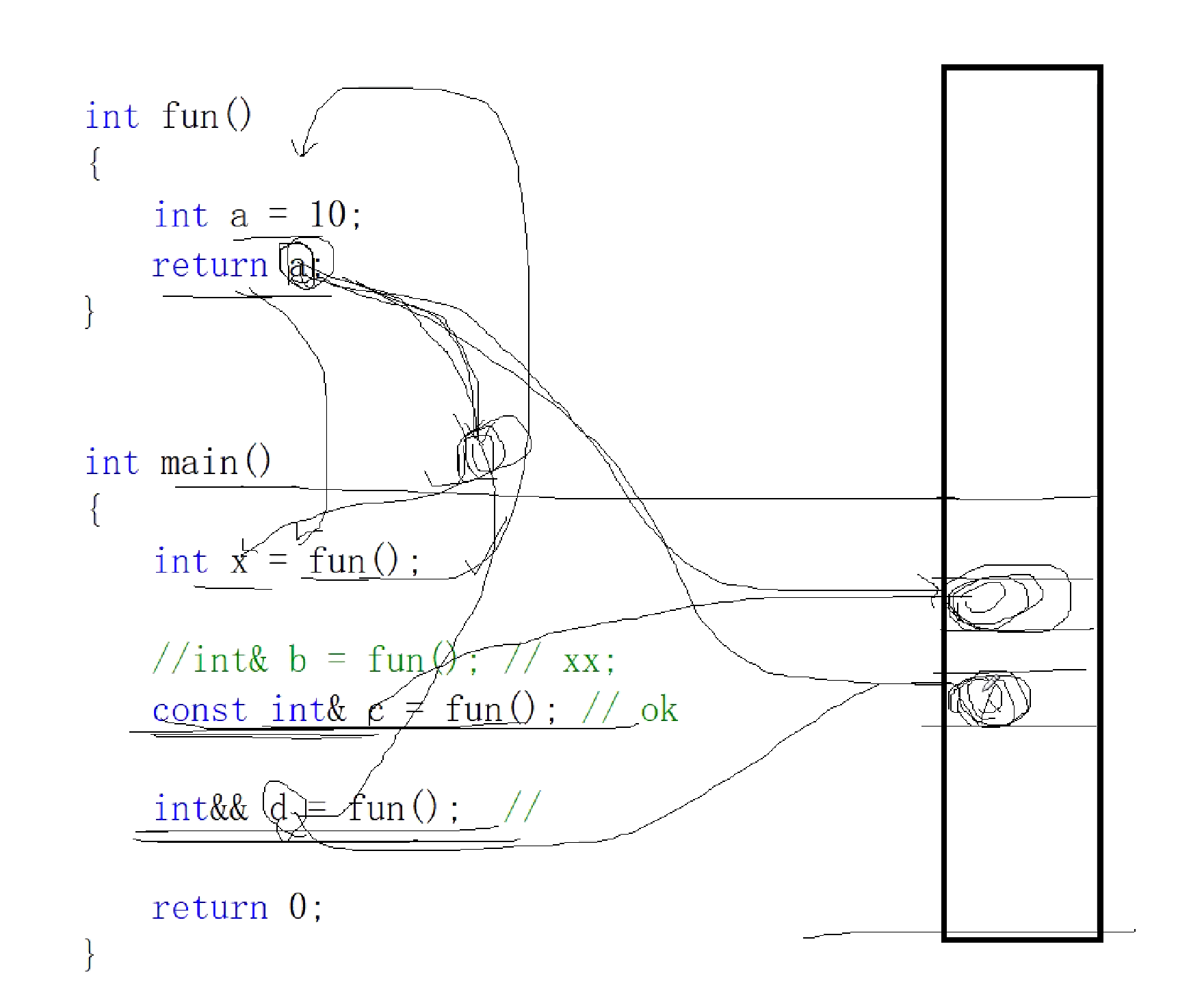
此处我们将a也是通过一个临时变量赋值给d。等到函数结束时,将亡值会小时。根据右值引用,我们还会将a的值放入主函数的栈帧空间。我们拿d去引用将亡值,将亡值也就会消失。并且使C去
一波两折。可以说是将将亡值的生存期拉长了,拉长到与d这个名字一样
C++
1、对于内置类型:char,int,double有一套处理规则
2、对于自定义类型:class等
又是另一套处理规则
右值引用主要是处理自定义类型的处理规则,怎么去优化它
3、介于 内置类型和自定义类型:pud类型
结构体类型struct
class 和 struct 区别
class在默认是私有
struct在默认是公有
class设计的是一个类型,最终实例化的是一个对象,属性和方法的集合
struct设计的时候,两个特点:
- 要么只包含数据
- 光有一堆纯虚方法,只有属性
struct作为数据集合时,和内置类型一致,处理方式一样。
没有数据,作为纯虚函数的集合,也叫做接口,和自定义类型处理一致。
右值的两个特点:
- 纯右值(字面常量)
- 函数返回的过程中产生的将亡值(可能是内置类型产生,自定义类型产生的将亡值,这样处理策略又不一样)
不论怎样的处理策略都是为了:代码优化,减少内存的拷贝
//上节课代码
class Object
{
int value;
public:
Object() { cout << "Object::Object " << this << endl; }
Object(int x = 0) : value(x) { cout << "Object::Object " << this << endl; }
~Object() { cout << "Object::~Object " << this << endl; }
Object(const Object& obj) :value(obj.value)
{
cout << "Copy Create " << this << endl;
}
Object& operator=(const Object& obj)
{
if (this != &obj) //防止自赋值
{
this->value = obj.value;
}
cout << this << " == " << &obj << endl;
return *this;
}//obja = objb = objc
int& Value() { return value; }
const int& Value() const { return value; }
};
Object fun(const Object &obj)
{
int val = obj.Value() + 10;
Object obja(val);
return obja;
}
int main()
{
Object objx(0);
Object objy(0);
objy = fun(objx);
cout << objy.Value() << endl;
cout << &objx << endl;
return 0;
}
不以引用返回:
Object fun(const Object &obj)
{
int val = obj.Value() + 10;
Object obja(val);
return obja;
}
小复习
过程:
fun函数中,形参是引用类型,所以fun(objx)是将objx的地址传递给obj,并不用再次构造一个新的对象。当执行到Object obja(val)时,构建一个存活在fun函数栈帧中的obja对象。return obja,调用拷贝构造函数创建一个将亡值对象。这时已经退出了fun函数,那么obja对象也就析构掉了,但是将亡值对象还没被析构掉。随后将亡值对象的值赋值给objy对象,将亡值对象也将析构。当main函数结束后,objx和objy对象也将析构
当结束fun函数的调用,obja对象会被析构。真正保存的obja值的是拷贝构造函数创建的将亡值对象,不必担心函数调用结束后返回不了。
新

以引用返回
Object &fun(const Object &obj)
{
int val = obj.Value() + 10;
Object obja(val);
return obja;
}
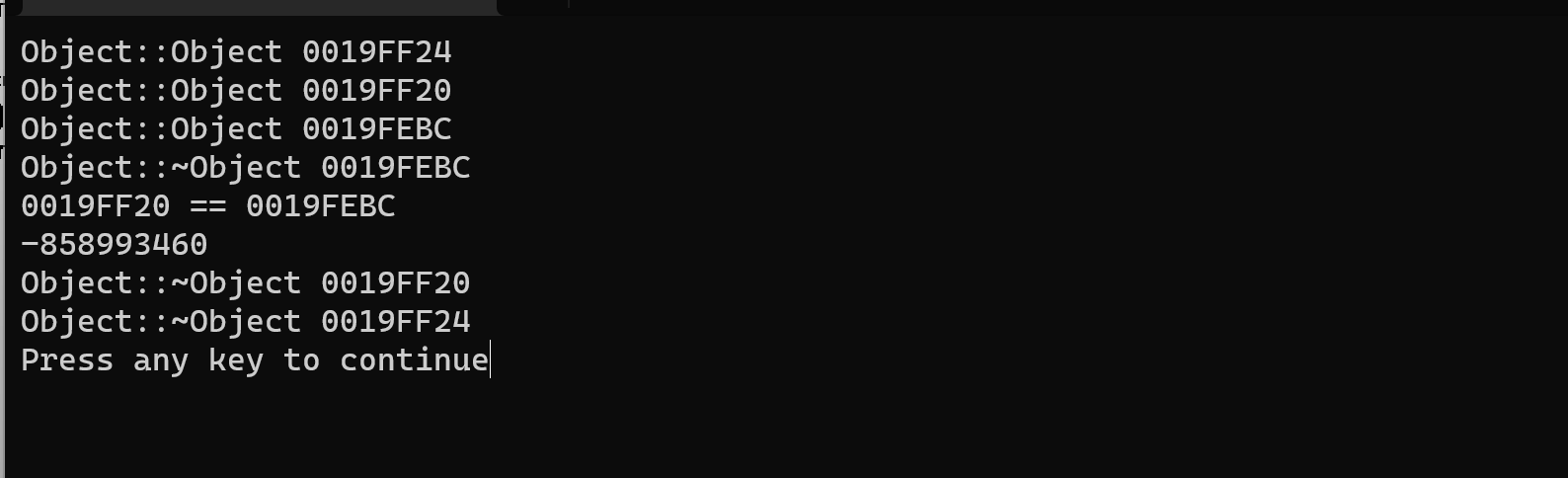
此处应该是返回随机值,但是vs2019有优化,打印仍然为10

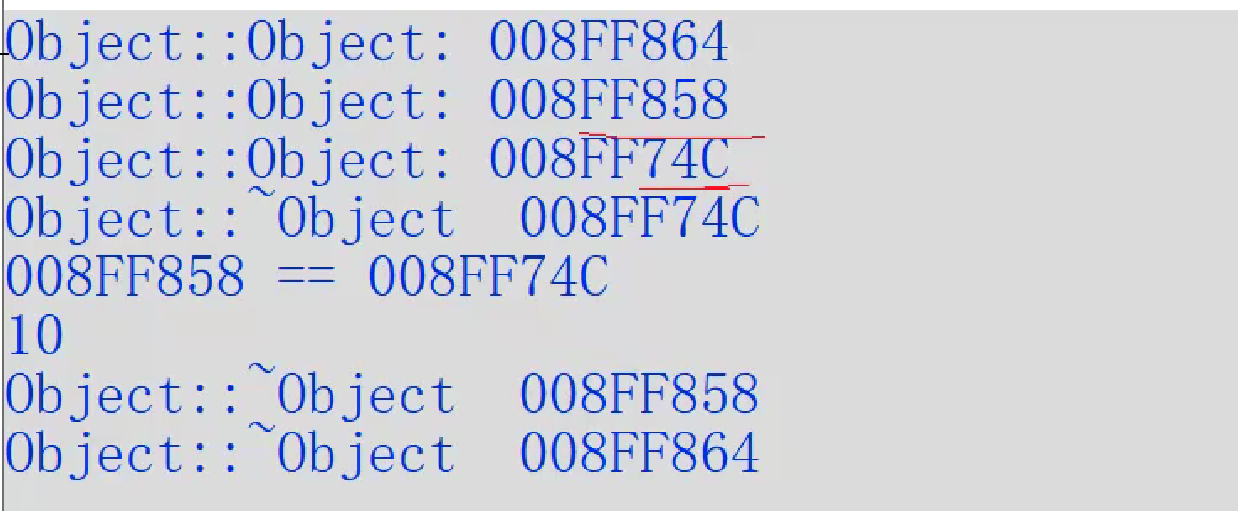
VC6.0中无优化:
return obja的时候我们只需要返回obja对象的地址,并不需要返回obj对象的本身。
在fun(obj)拿到了obja的地址我们并不是将地址给objy,我们将地址所指向的对象给objy。
我们调用赋值语句,将已死亡的对象给objy,打印出随机数。而VS打印10,过度优化bug,关键点在于赋值函数。
赋值函数的特点:

此处下方是main的栈帧,中间是fun函数的栈帧。obja是fun函数栈帧中的对象,当执行到fun(objx)的时候,
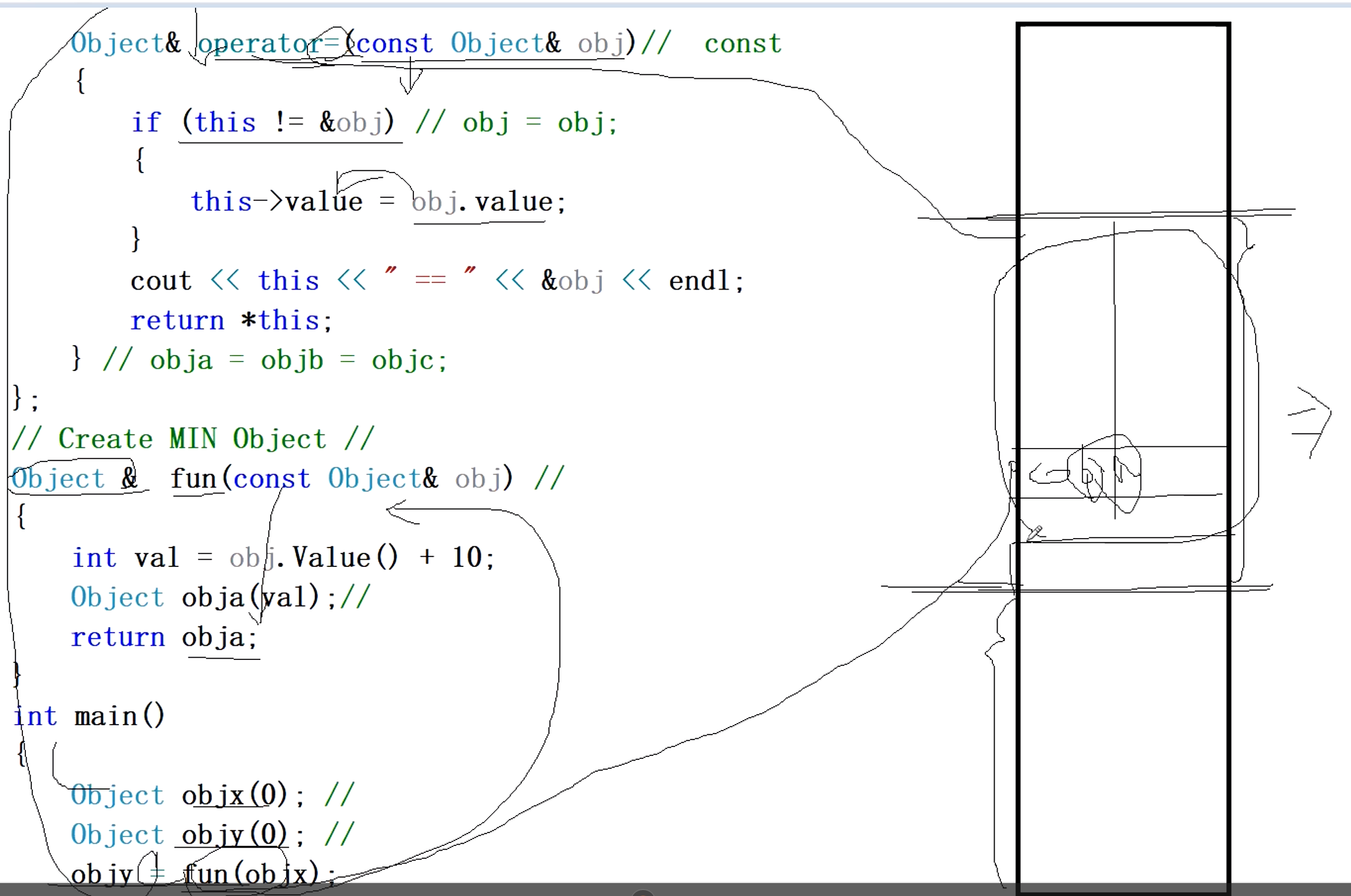
随后赋值调用赋值函数,会对之前fun函数的栈帧进行清扫,但在赋值函数中仅在形参定义了一个obj对象的引用,所以对fun函数占用的栈帧清扫力度不大(覆盖了一点)在圆圈上面并没有清扫,只对下面进行了清扫,并没有把obja的对象空间清扫到,造成我们从已死亡对象取到的值还是10。
那我们怎么清扫呢?
我们可以在赋值函数中多定义几个变量
Object& operator=(const Object& obj)
{
int a = 100;
int b = 100;
if (this != &obj)
{
this->value = obj.value;
}
cout << this << " == " << &obj << endl;
return *this;
}
结果不是10,是随机值
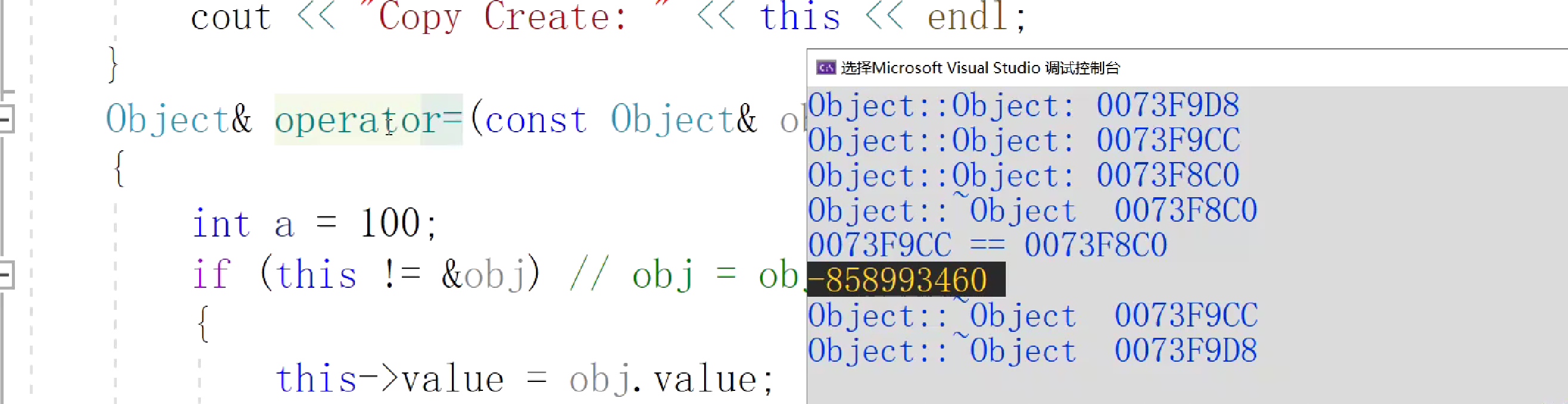
VS2019的特点,我们在调用函数的时候,如果没有局部变量或者局部对象的时候,就不对栈帧进行清扫。再次调用的时候,已死亡的对象会被取到,一旦定义了一个变量,我们就会对它整个栈帧空间进行清扫,将残留空间进行清空。
//新课,完成拷贝构造函数
class Object
{
private:
int num;
int ar[5];
public:
Object(int n, int val = 0) : num(n)
{
for (int i = 0; i < n; ++i)
{
ar[i] = val;
}
}
};
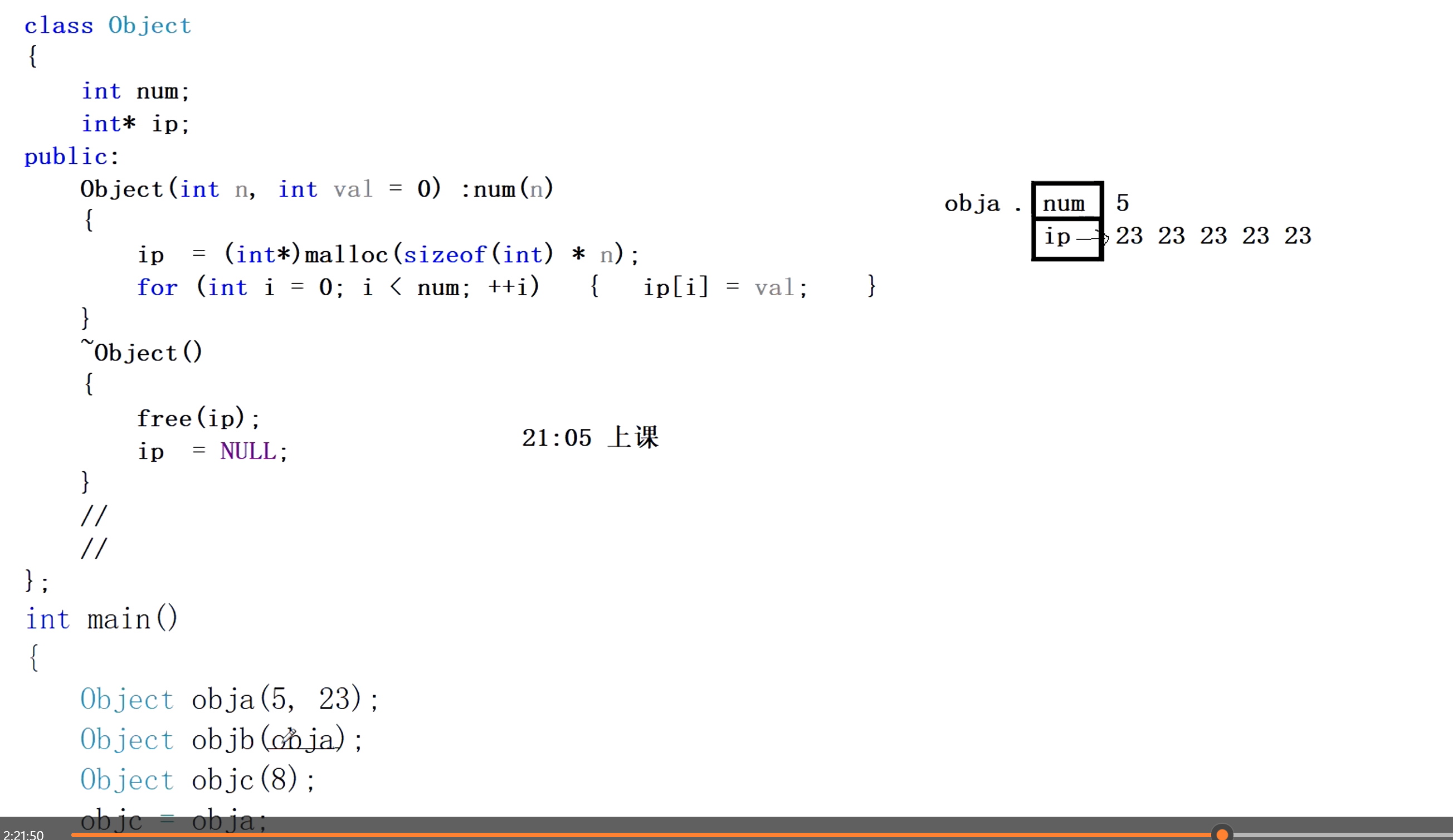
int main()
{
Object obja(5, 23);
Object objb(obja);
Object objc(5);
objc = obja;
}
内存图:
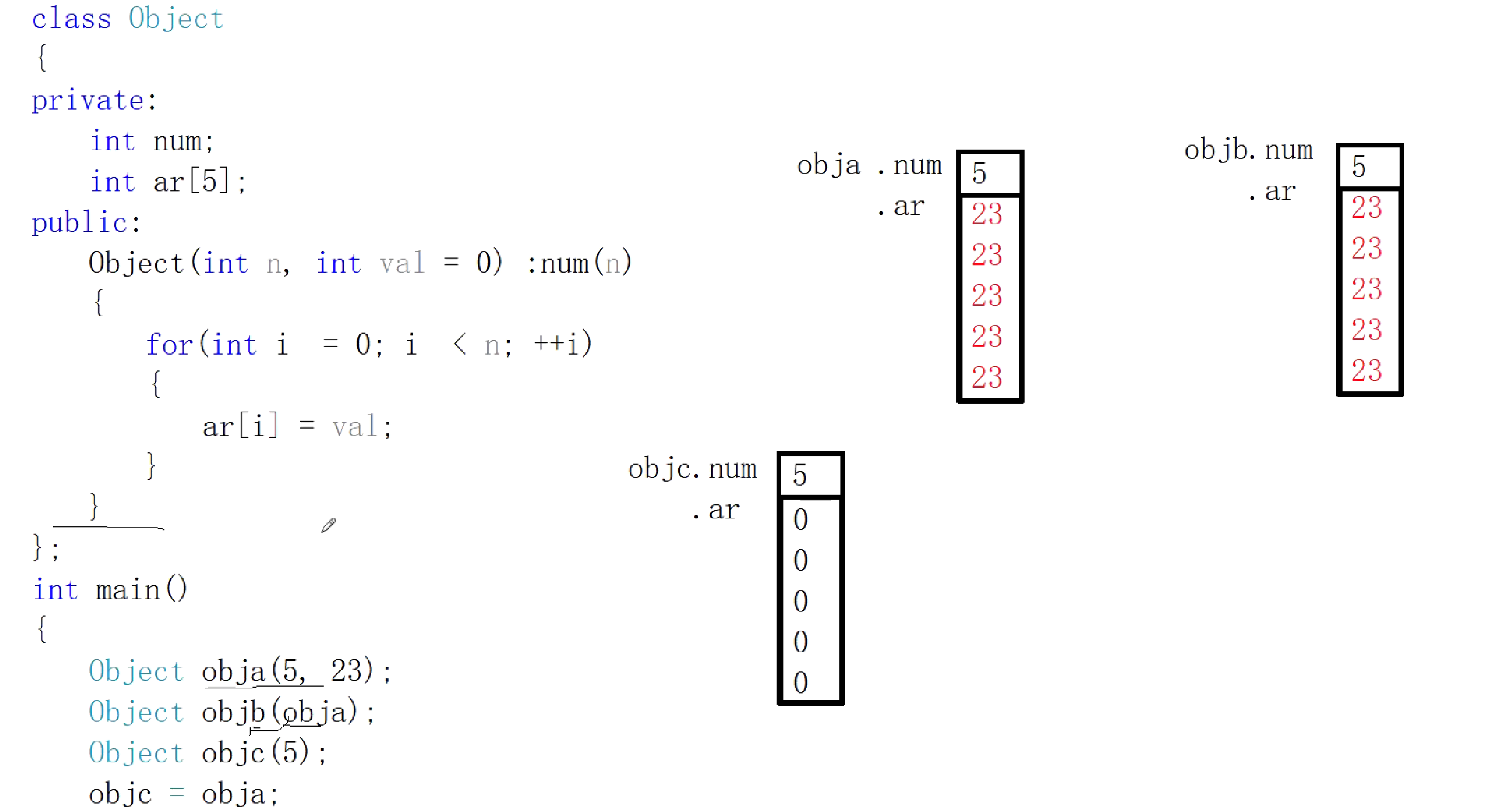
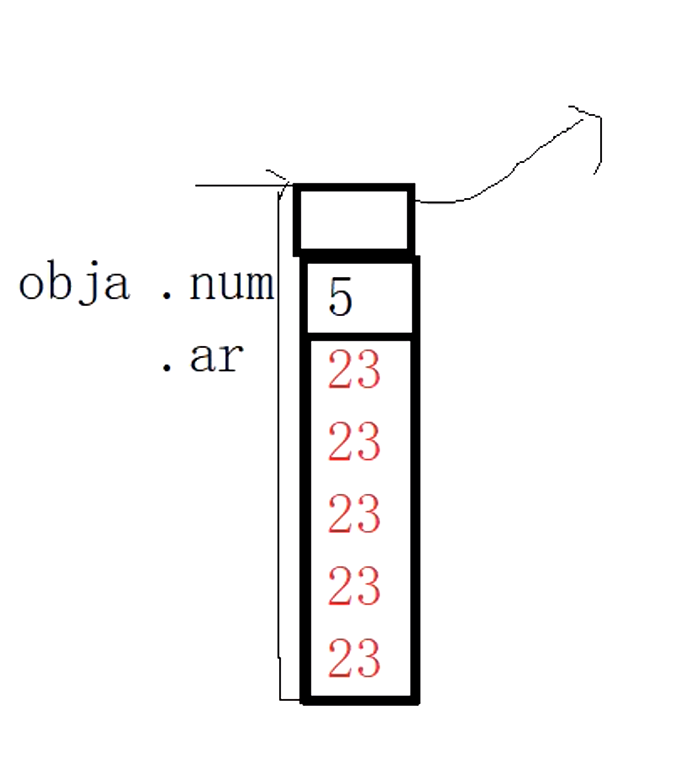
此处就要写两个函数:拷贝构造函数和赋值函数,如果没有写,系统会自动给出。那么缺省的拷贝构造和缺省的赋值函数到底是什么样子呢?
//构造函数可以用初始化列表
Object(const Object& obj):num(obj.num)
{
for(int i = 0; i < num; i++)
{
ar[i] = obj.ar[i];
}
}
Object& operator=(const Object &obj)
{
if(this != &obj)
{
num = obj.num;
for(int i = 0; i < obj.num; i++)
{
ar[i] = obj.ar[i];
}
}
return *this;
}
memset等内存拷贝函数不能用于所有构造函数或者赋值语句

原因:
memmove(this, &obj , sizeof(Object));
如果有虚函数

我们在创建对象的过程中,对象的上面有4个字节,虚表指针指向虚表
当this指针大小找见的时候,我们连虚表指针都进行了移动,显然不允许这样做。
更加糟糕的做法
memove(this,0,sizeof(Object));
如果有虚表,虚表在进入构造函数和拷贝构造之前,我们就对虚表进行了设置。再进入构造对象的时候,这句就会将虚表也进行清空
我们在C++的构造函数,或者任何成员函数中,必须谨慎的使用内存拷贝函数。
什么时候能使用呢?
当我们的类比较简单,没有继承关系、没有虚函数的时候,我们谨慎使用memset函数。
当我们加了虚函数的时候,不要使用memset函数。
如果没写赋值和拷贝构造函数,会有语义方面的赋值和拷贝构造函数,
什么是语义上的呢?
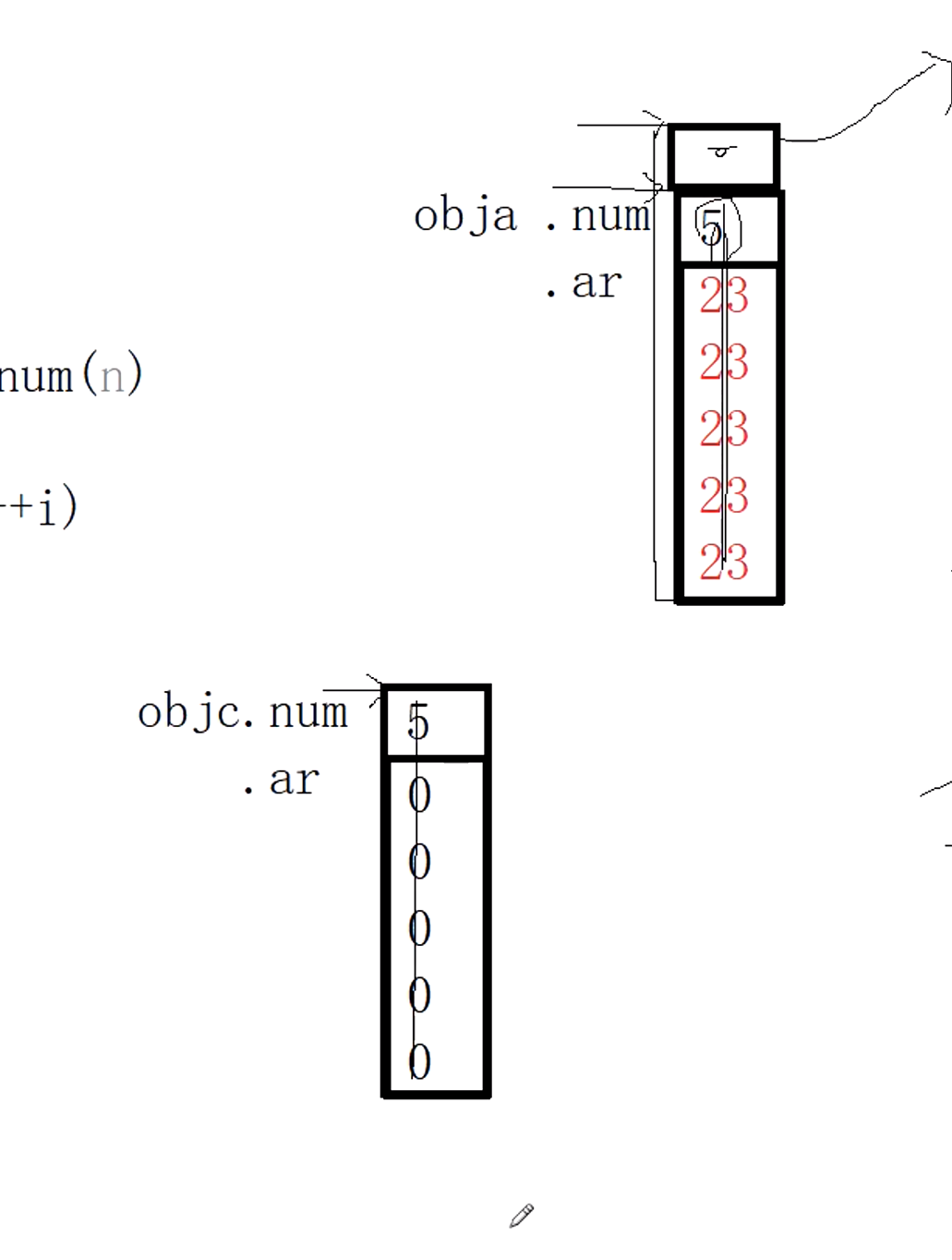
obja = objc
那么时候时候会有真正的函数呢?
会将obja中的数据从obja开始,抓住。将objc开头抓住,直接进行赋值。
如果存在虚函数,有继承关系,成员都是基本数据类型,没有自己设置的类型,那么就老老实实的给出真正的默认赋值和默认拷贝构造函数。
我们自己写出构造和赋值函数的时候,也会老老实实调用我们写出来的函数。
老老实实调用我们写出来的函数
下面我们就看看默认的情况
class Object
{
private:
int num;
int ar[5];
public:
Object(int n, int val = 0) : num(n)
{
for (int i = 0; i < n; ++i)
{
ar[i] = val;
}
}
Object(const Object& obj):num(obj.num)
{
for(int i = 0; i < num; i++)
{
ar[i] = obj.ar[i];
}
}
void Print() const
{
cout << num << endl;
for(int i = 0; i < 5; i++)
{
cout << ar[i] << endl;
}
}
};
Object& fun()
{
Object objx(5,100);
return objx;
}
int main()
{
Object obja(5, 23);
Object objb(obja);
Object objc(5);
objc = fun();
objc.Print();
return 0;
}
结果:
没有赋值还是输出了

加上赋值语句
//将赋值语句加入类中
class Object
{
private:
int num;
int ar[5];
public:
Object(int n, int val = 0) : num(n)
{
for (int i = 0; i < n; ++i)
{
ar[i] = val;
}
}
Object(const Object& obj) :num(obj.num)
{
for (int i = 0; i < num; i++)
{
ar[i] = obj.ar[i];
}
}
Object& operator=(const Object& obj)
{
if (this != &obj)
{
num = obj.num;
for (int i = 0; i < obj.num; i++)
{
ar[i] = obj.ar[i];
}
}
return *this;
}
void Print() const
{
cout << num << endl;
for (int i = 0; i < 5; i++)
{
cout << ar[i] << endl;
}
}
};
Object& fun()
{
Object objx(5, 100);
return objx;
}
int main()
{
Object obja(5, 23);
Object objb(obja);
Object objc(5);
objc = fun();
objc.Print();
return 0;
}
我们主函数调用fun会开辟栈帧,fun中有objx对象,如果没有给出赋值函数,系统会缺省一个语义上的赋值语句(并没有函数调用过程,不会形成现场保护,直接通过内存复制)。当我们执行完的时候,我们会抓住它头尾的地址,将地址直接往里面赋,直接进行objc = objx赋值。从而没有将fun释放的空间进行侵扰,数据会残留在原来的地址,所以打印出来我们想要的值 5 100 100 100 100 100。
但是我们给出了赋值函数,我们就会老老实实的进行函数调用,那么我们新开辟的栈帧会覆盖上一次fun的栈帧。在赋值的时候,可能将之前fun函数栈帧中残存的objx覆盖掉,打印的是一个随机值。

调试步骤可以看出,在进入赋值函数第一步的时候,原先的堆栈空间的值就已经崩溃
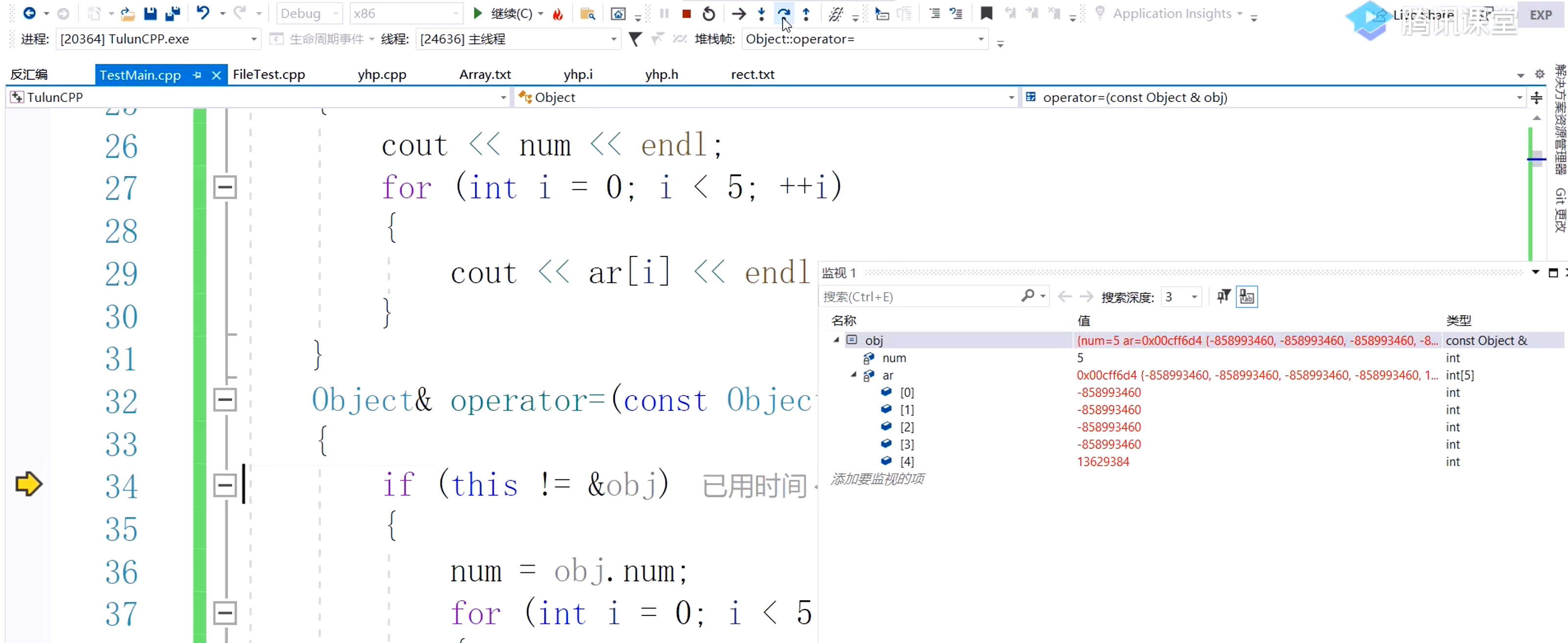
我们以引用返回objx,抓住objx的地址,我们直接将objx的地址给赋值语句。
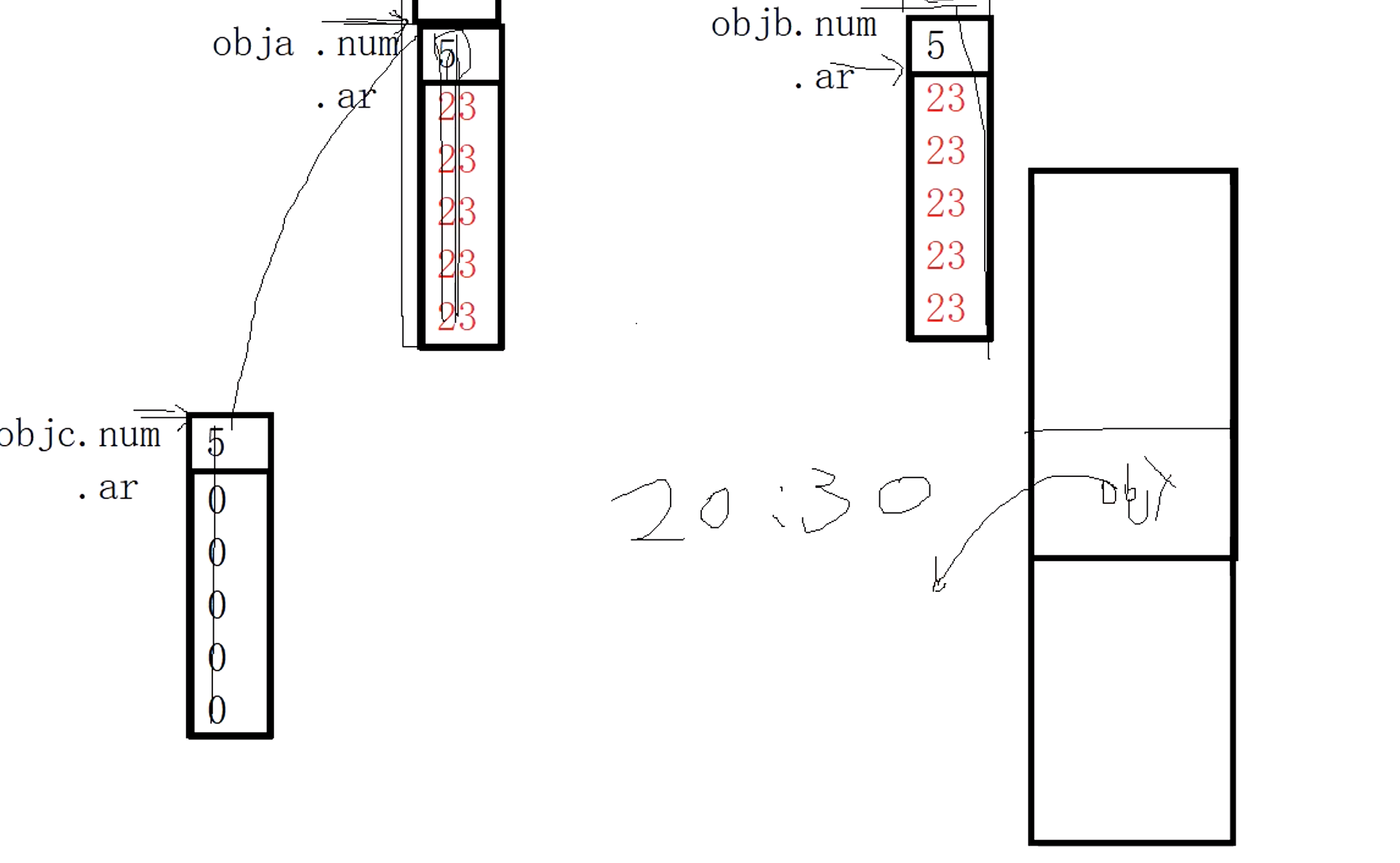
objc = &objx地址处的东西

obja开辟8个字节 的空间,num是5还有一个ip指针指向堆区 23 23 23 23 23
我们用objb来拷贝构造obja,objb与obja一模一样,通过抓取实现

这个就是系统给出的拷贝构造。
接着objc(8)。这里的ip指针也是指向堆区,一共8个0

赋值重载函数中objc = obja;我们直接将obja赋值给objc。
用8将5填充,拿ip的值填充掉,指向5个23的位置
image
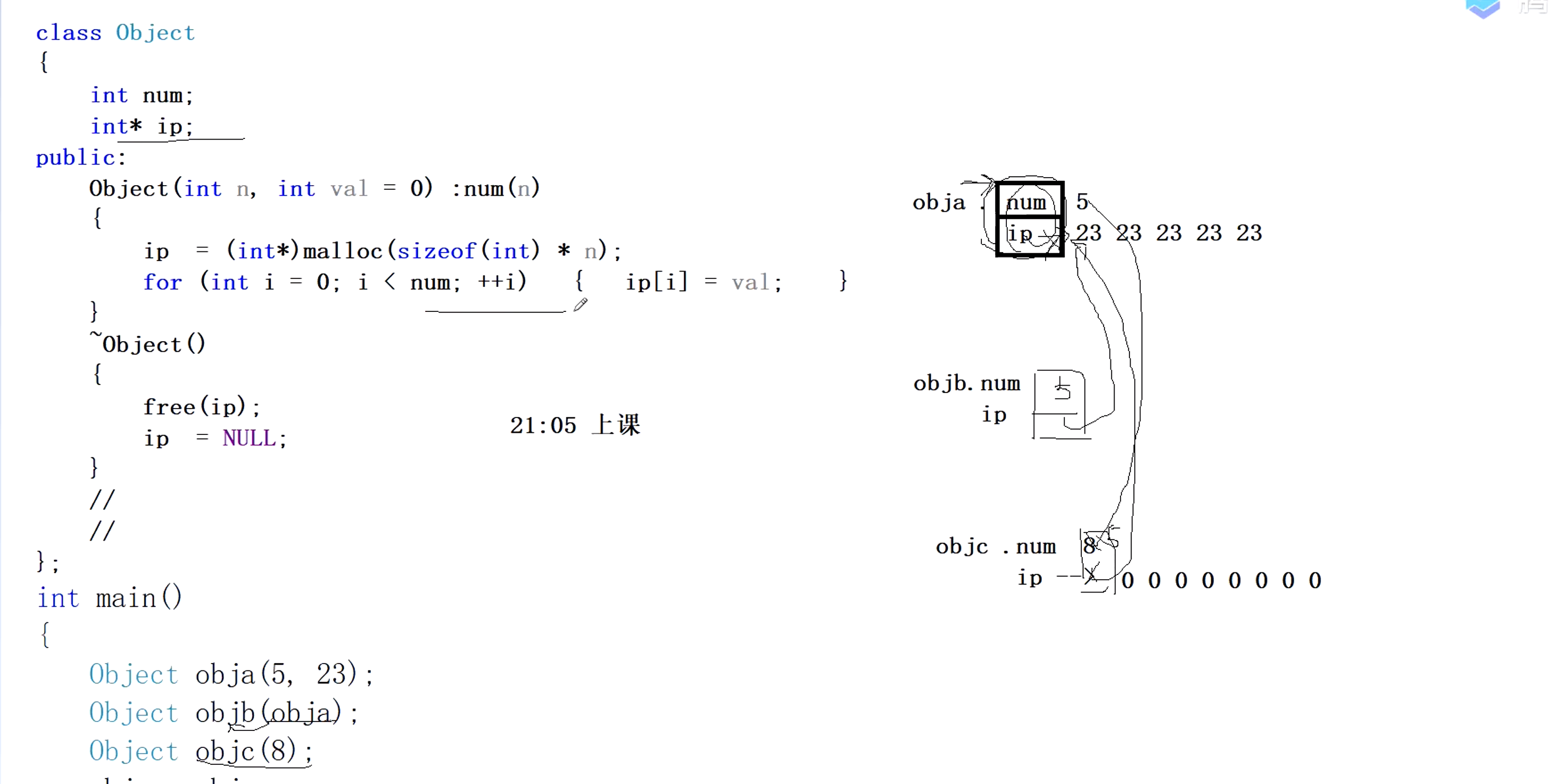
这都是系统产生的,动态开辟会造成内存丢失,析构的时候会造成2次释放空间,这时系统提供的无法满足我们的要求,我们会进行重写。
//重写
Object(const Object& obj):num(obj.num),ip(obj.ip){}
Object& operator=(const Object &obj)
{
if (this != &obj)
{
num = obj.num;
ip = obj.ip;
}
return *this;
}



看看运算符重载的法则,前置++和后置++
class Int
{
int value;
public:
Int(int x = 0) :value(x)
{
cout << "Create Int " << this << endl;
}
Int(const Int& it) :value(it.value)
{
cout << "Copy Int " << this << endl;
}
Int &operator=(const Int &it)
{
if (this != &it)
{
value = it.value;
}
cout << this << " = " << &it << endl;
return *this;
}
~Int() { cout << "Destroy Int " << this << endl; }
};
int main()
{
Int a(10), b(0), c(0);
b = ++a;
c = a++;
return 0;
}
b = ++a;先进行a的自加,在进行赋值。
c = a++;先进行赋值,在进行a的自加。
Int &operator++()
{
this->value++;
return *this;
}
Int operator++(int) //注意此对象用值类型返回,不能用对象类型返回
{
Int tmp = *this;
++* this; //* 和 ++的优先级区分,同级从右向左
return tmp;
}
前置++和后置++的本质
b = ++a;
b = a.operator++;
b = operator++(&a);
//后置++
c = a++;
c = a.operator++(0);
c = operator++(&a,0);
可以说后置++是双目,前置++是单目,通过定义一个参数来进行区分
重载+运算符
c =a + b
c = a+10;
c = 10 + a;
对象和对象相加,对象和内置类型相加,内置类型和对象相加
int main()
{
Int a(10),b(5),c(0);
c = a + b;
c = a + 10;
c = 10 + a;
return 0;
}
重载+运算符(三个)
//注意:这样写是 +=
//Int operator+(const Int& it)
//{
// Int tmp;
// tmp.value = it.value + this->value;
// return tmp;
//}
上面这样写相当于+=,是错误的
段点设置在 c = a + 10
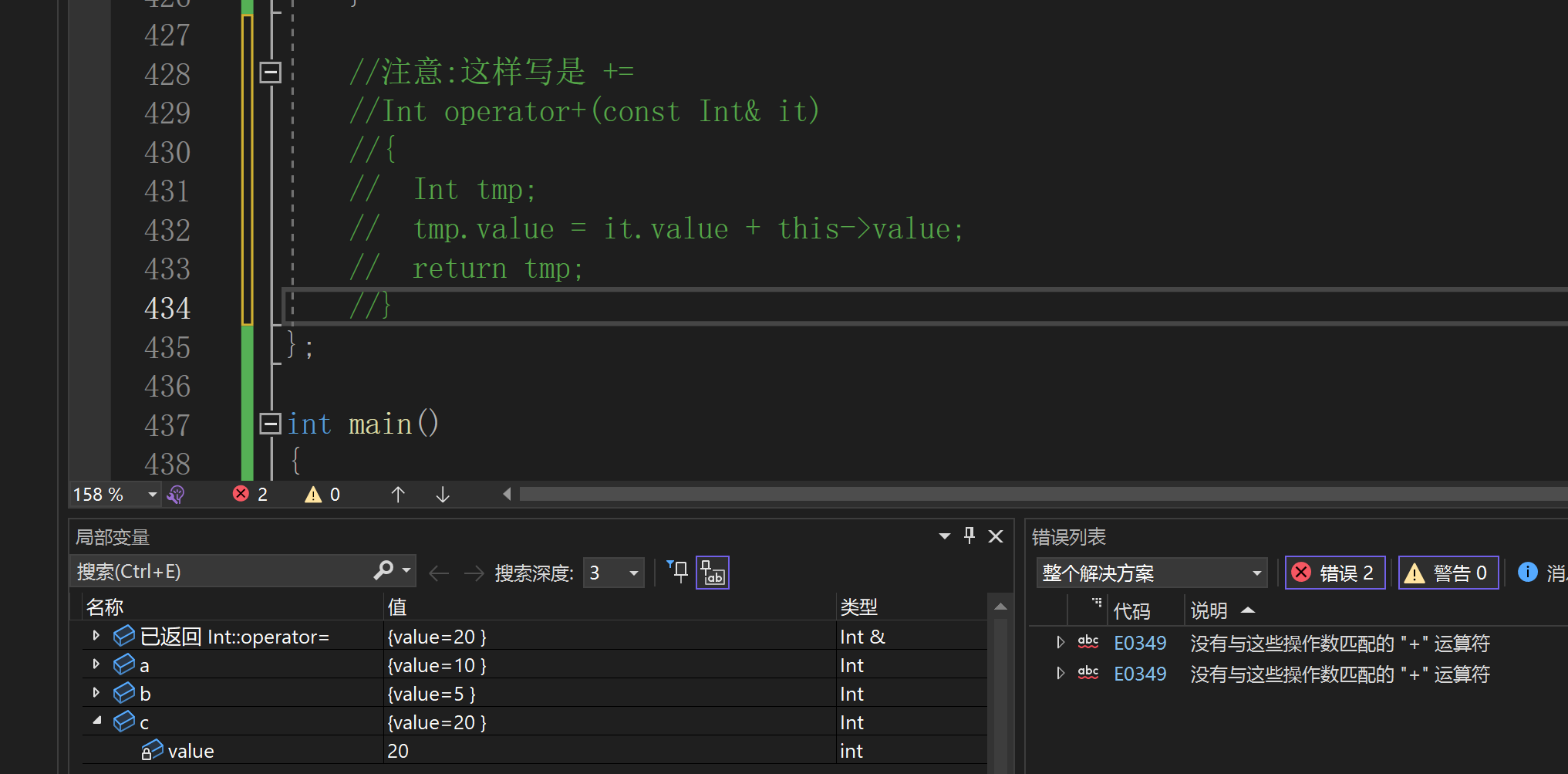
正确的重载
//这两个函数都在类中:
Int operator+(const Int& it) const
{
return Int(this->value + it.value);
}
Int operator+(const int x) const
{
return Int(this->value + x);
}
//这个函数在类外
//转成全局函数也会有些问题,我们不能操作私有成员
Int operator+(const int x, const Int& it)
{
//错误:操作私有
//return Int(x + it.value);
return it + x; //right
}
关于其他运算符的重载
bool operator==(const Int& it) const
{
return this->value == it.value;
}
bool operator!=(const Int& it) const
{
return !(*this == it);
}
bool operator<(const Int& it) const
{
return this->value < it.value;
}
bool operator >= (const int& it) const
{
return !(*this < it);
}
bool operator>(const Int& it) const
{
return this->value > it.value;
}
bool operator<=(const Int& it) const
{
return !(*this > it);
}
为什么循环里面喜欢++i而不是i++呢?
此处的i输出是多少呢?

i输出2
此处的a的value值输出是多少呢?

a输出1

为什么呢?
int main()
{
Int i = 0;
Int n = 10;
for (; i < n; ++i)
{
i.Print();
}
return 0;
}
前置++
输出非常清爽。

后置++:
for(; i < n; i++)
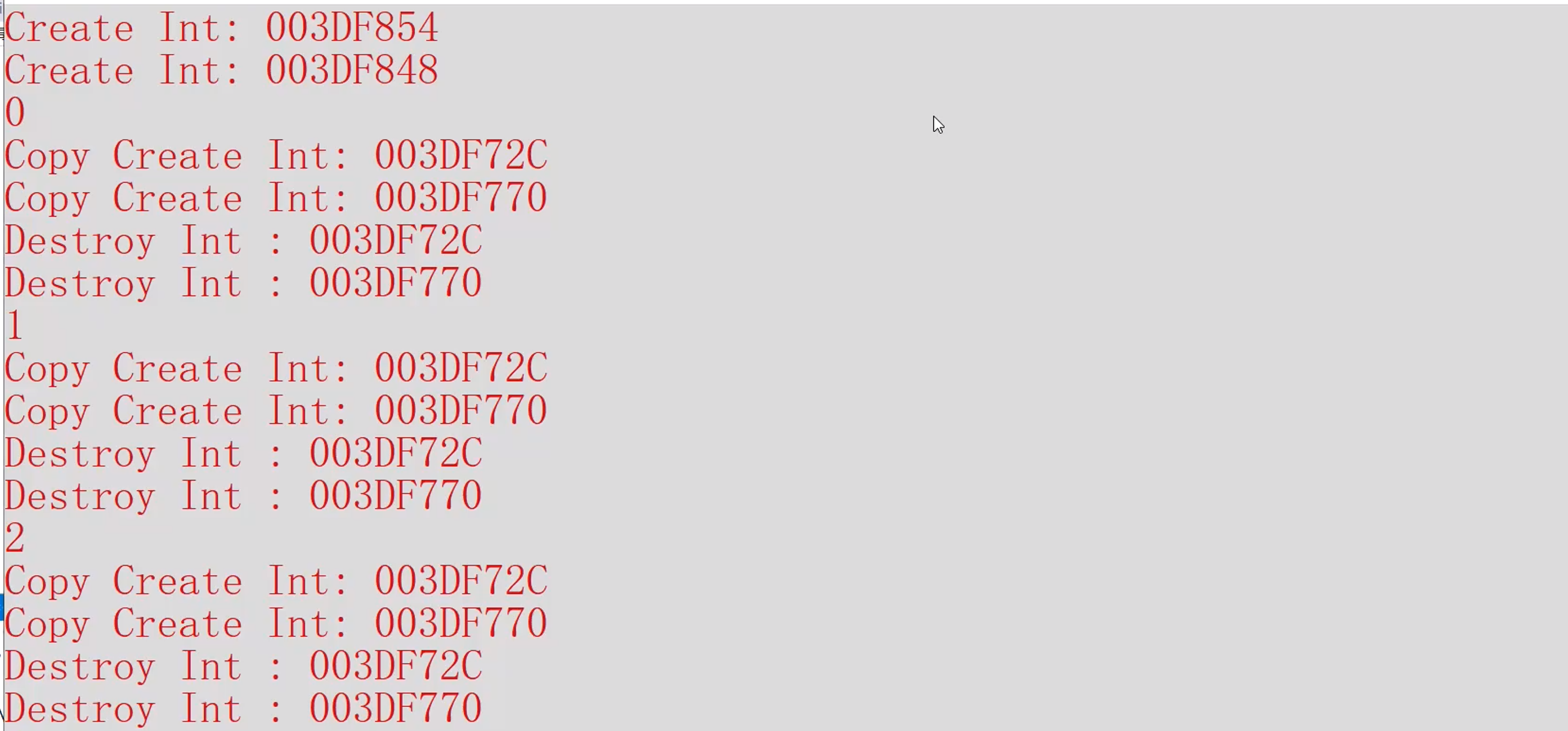
可以发现效率非常低,我们需要不断的创建对象,打印值后,还要不断的销毁对象


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!