Kubernetes服务发现之Service详解
一、引子
Kubernetes Pod 是有生命周期的,它们可以被创建,也可以被销毁,然后一旦被销毁生命就永远结束。通过ReplicationController 能够动态地创建和销毁Pod(列如,需要进行扩缩容,或者执行滚动升级);每个Pod都会获取它自己的IP地址,即使这些IP地址不总是稳定可依赖的。这会导致一个问题;在Kubernetes集群中,如果一组Pod(称为backend)为其他Pod(称为frontend)提供服务,那么哪些frontend该如何发现,并连接到这组Pod中的那些backend呢?
关于Service
Kubernetes Service定义了这样一种抽象:一个Pod的逻辑分组,一种可以访问它们不同的策略--通常称为微服务。这一组Pod能够被Service访问到,通常是通过Label Sekector实现的;
举个例子,考虑一个图片处理backend,它运行了3个副本。这些副本是可交换的 -- frontend不需要关心它们调用了哪个backend副本。然后组成这一组backend程序的Pod实际上可能会发生变化,frontend客户端不应该也没必要知道,而且也不需要跟踪这一组backend的状态。Service定义的抽象能够解耦这种关联。
对Kubernetes集群中的应用,Kubernetes提供了简单的Endpoints API,只要service中的一组Pod发生变更,应用程序就会被更新。对非Kubernetes集群中的应用,Kubernetes提供了基本VIP的网桥的方式访问Service,再由Service重定向到backend Pod。
二、定义Service
一个Service在Kubernetes中是一个REST对象,和Pod类似。像所有的REST对象一样,Service定义可以基于POST方式,请求apiserver创建新的实例。例如,假定有一组Pod,它们对外暴漏了9376端口,同时还被打上“app=MyApp”标签。
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
上述配置将创建一个名称为“my-service”的Service对象,它会将请求代理到使用TCP端口9376,并且具有标签“app=MyApp”的pod上。这个Service将被指派一个IP地址(通常为“Cluster IP”)它会被服务的代理使用。该Service的selector将会持续评估,处理结果将被POST到一个名称为"my-service"的Endpoints对象上。
需要注意的是,Servie能够将一个接收端口映射到任意的targetPort。默认情况下,targetPort将被设置为与port字段相同的值。可能更有趣的是,targetPort可以是一个字符串,引用了backend Pod的一个端口的名称;但是,实际指派给该端口名称的端口号,在每个backend Pod中可能并不相同。对于部署和设计Service,这种方式会提供更大的灵活性。例如,可以在backend软件下一个版本中,修改Pod暴露的端口,并不会中断客户端的调用。
Kubernetes service能够支持TCP和UDP协议,默认TCP协议
三、没有selector的Service
Service抽象了该如何访问Kubernetes Pod,但也能抽象其他类型的backend,例如:
- 希望在生产环境中使用外部的数据库集群,但测试环境使用自己的数据库。
- 希望服务指向另一个Namespace中或其他集群中的服务。
- 正在将工作负载转移到Kubernetes集群,和运行在Kubernetes集群之外的backend。
在任何这些场景中,都能够定义没有selector 的 Service :
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
由于这个Service没有selector,就不会创建相关的Endpoints对象。可以手动将Service映射到指定的Endpoints:
kind: Endpoints
apiVersion: v1
metadata:
name: my-service
subsets:
- addresses:
- ip: 1.2.3.4
ports:
- port: 9376
注意:Endpoint IP地址不能loopback(127.0.0.0/8),link-local(169.254.0.0/16),或者link-local多播(224.0.0.0/24)。
访问没有selector的Service,与selector的Service的原理相同。请求被路由到用户定义的Endpoint(该示例中为1.2.3.4:9376)
ExternalName service是Service的特别,它没有selector,也没有定义任何的端口和Endpoint。相反地,对于运行在集群外部的服务,它通过返回该外部服务的别名这种方式来提供服务。
kind: Service
apiVersion: v1
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
当查询主机 my-service.prod.svc.CLUSTER时,集群的DNS服务将返回一个值为my.database.example.com的CNAME记录,访问这个服务的功能方式与其他的相同,唯一不同的是重定向发生的DNS层,而且不会进行代理或转发。如果后续决定要将数据库迁移到Kubetnetes中,可以启动对应的Pod,增加合适的Selector或Endpoint,修改service的typt。
四、VIP和Service代理
在Kubernetes集群中,每个Node运行一个kube-proxy进程。kube-proxy负责为Service实现了一种VIP(虚拟IP)的形式,而不是ExternalName的形式。在Kubernetes v1.0版本,代理完全在userspace。在Kubernetes v1.1版本,新增了iptables代理,但并不是默认的运行模式。从Kubernetes v1.2起,默认就是iptables代理。
在Kubernetes v1.0版本,Service是“4层”(TCP/UDP over IP)概念。在Kubernetes v1.1版本,新增了 Ingress API(beta版),用来表示“7层”(HTTP)服务。
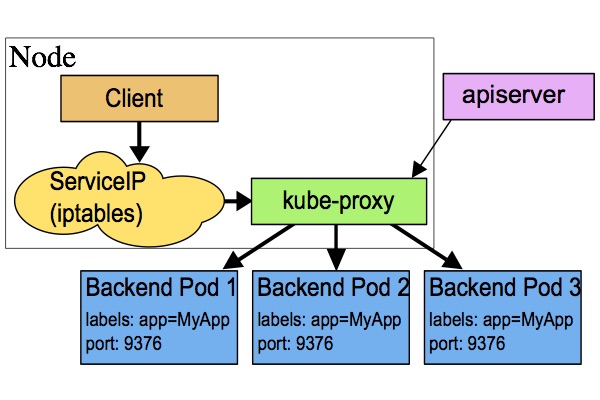
五、userspace代理模式
这种模式,kube-proxy会监视Kubernetes master对service对象和Endpoints对象的添加和移除。对每个Service,它会在本地Node上打开一个端口(随机选择)。任何连接到“代理端口”的请求,都会被代理到Service的backend Pods中的某一个上面(如 Endpoints 所报告的一样)。使用哪个backend Pod,是基于Service的SessionAffinity来确定的。最后,它安装iptables规则,捕获到达该Service的clusterIP(是虚拟IP)和Port的请求,并重定向到代理端口,代理端口再代理请求到backend Pod。
网络返回的结果是,任何到达Service的IP:Port的请求,都会被代理到一个合适的backend,不需要客户端知道关于Kubernetes,service或pod的任何信息。
默认的策略是,通过round-robin算法来选择backend Pod。实现基于客户端IP的会话亲和性,可以通过设置service.spec.sessionAffinity的值为“ClientIP”(默认值为“None”);
六、iptables代理模式
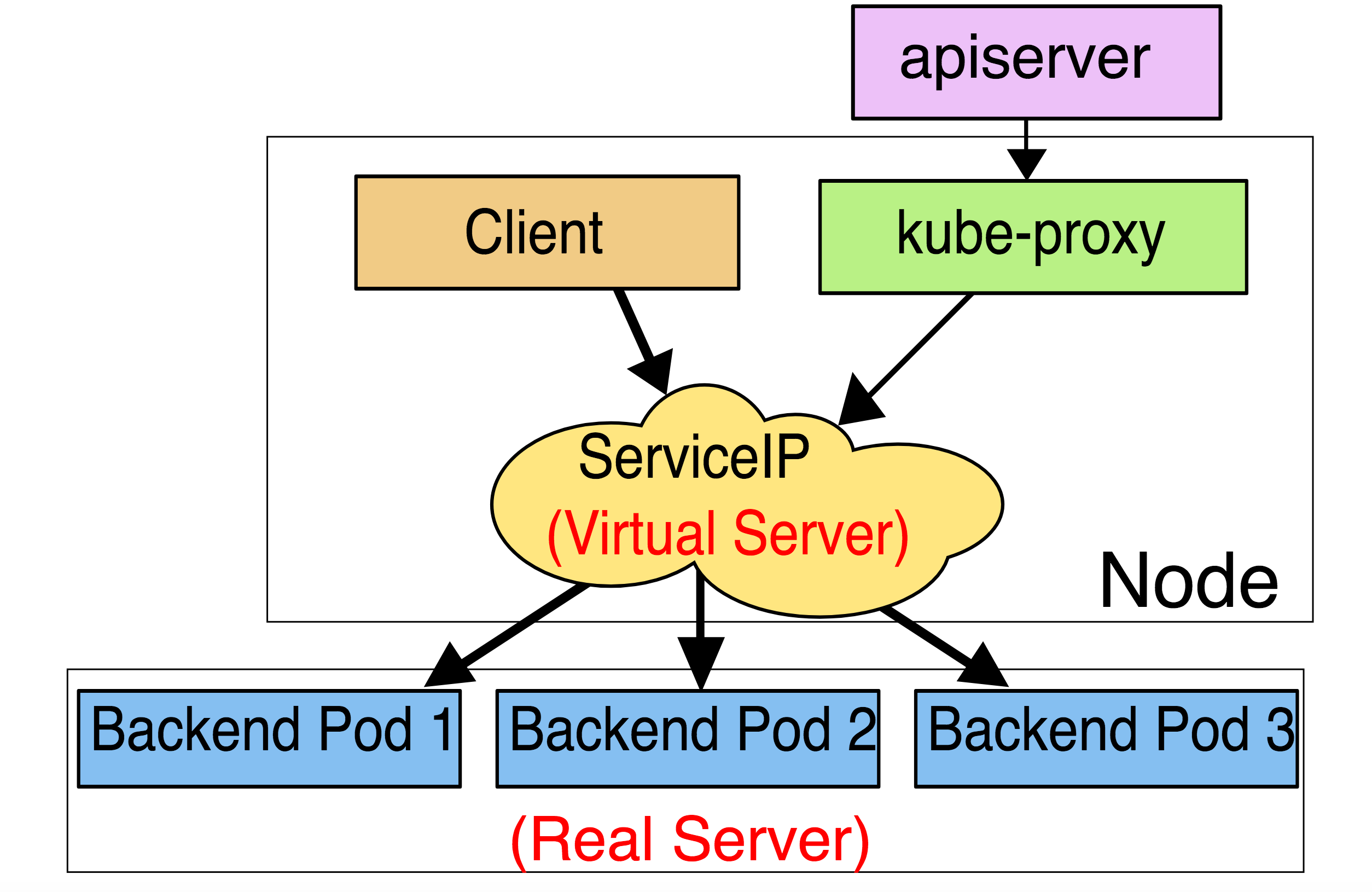
这种模式,kube-proxy会监视Kubernetes master对象和Endpoinnts对象的添加和移除。对每个Service,它会安装iptables规则,从而捕获到达该Service的clusterIP(虚拟IP)和端口的请求,进而将请求重定向到Service的一组backend中某个上面。对于每个Endpoints对象,它也会安装iptables规则,这个规则会选择一个backend Pod。
默认的策略是,随机选择一个backend。实现基于客户端IP的会话亲和性,可以将service.spec.sessionAffinity的值设置为“ClientIP”(默认值为“None”)
和userspace代理类似,网络返回的结果是,任何到达Service的IP:Port的请求,都会被代理到一个合适的backend,不需要客户端知道关于Kubernetes,service或Pod的任何信息。这应该比userspace代理更快,更可靠。然而,不想userspace代理,如果始出选择的Pod没有响应,iptables代理不能自动地重试另一个Pod,所以它需要依赖readiness probes;
https://jimmysong.io/kubernetes-handbook/images/services-iptables-overview.jpg
七、ipvs代理模式
这种模式,kube-proxy会监视Kubernetes service对象和Endpoints,调用netlink接口以相应地创建ipvs规则并定期与Kubernetes service对象和Endpoints对象同步ipvs规则,以确保ipvs状态与期望一致。访问服务时,流量将被重定向到其中一个后端Pod。
与iptables类似,ipvs基于netfilter的hook功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着ipvs可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外,ipvs为负载均衡算法提供了更多的选项,例如:
- rr:轮询调度
- lc:最小连接数
- dh:目标哈希
- sh:源哈希
- sed:最短期望延迟
- nq: 不排队调度
注意: ipvs模式假定在运行kube-proxy之前在节点上都已经安装了IPVS内核模块。当kube-proxy以ipvs代理模式启动时,kube-proxy将验证节点上是否安装了IPVS模块,如果未安装,则kube-proxy将回退到iptables代理模式。
八、多端口Service
很多Service需要暴露多个端口。对于这种情况,Kubernetes 支持在Service对象中定义多个端口。当使用多个端口时,必须给出所有端口的名称,这样Endpoint就不会产生歧义,例如:
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 9376
- name: https
protocol: TCP
port: 443
targetPort: 9377
九、选择自己的IP地址
在Service创建的请求中,可以通过设置spec.cluster IP字段来指定自己的集群IP地址。比如,希望替换一个已经存在的DNS条目,或者遗留系统已经配置了一个固定IP且很难重新配置。用户选择的IP地址必须合法,并且这个IP地址在service-cluster-ip-range CIDR 范围内,这对 API Server 来说是通过一个标识来指定的。 如果 IP 地址不合法,API Server 会返回 HTTP 状态码 422,表示值不合法。
十、为何不使用round-robin DNS?
一个不时出现的问题是,为什么我们都使用VIP的方式,而不使用标准的round-robin DNS,有如下几个原因:
- 长久以来,DNS 库都没能认真对待 DNS TTL、缓存域名查询结果
- 很多应用只查询一次 DNS 并缓存了结果
- 就算应用和库能够正确查询解析,每个客户端反复重解析造成的负载也是非常难以管理的
我们尽力阻止用户做那些对他们没有好处的事情,如果很多人都来问这个问题,我们可能会选择实现它。
十一、服务发现
Kubernetes 支持2种基本的服务发现模式 —— 环境变量和 DNS。
十二、环境变量
当Pod运行在NOde上,kubelet会为每个活跃的Service添加一组环境变量。它同时支持Docker links兼容变量,简单的{SVCNAME}_SERVICE_HOST 和 {SVCNAME}_SERVICE_PORT 变量,这里 Service 的名称需大写,横线被转换成下划线。
举个例子,一个名称为 "redis-master" 的 Service 暴露了 TCP 端口 6379,同时给它分配了 Cluster IP 地址 10.0.0.11,这个 Service 生成了如下环境变量:
REDIS_MASTER_SERVICE_HOST=10.0.0.11
REDIS_MASTER_SERVICE_PORT=6379
REDIS_MASTER_PORT=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP=tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO=tcp
REDIS_MASTER_PORT_6379_TCP_PORT=6379
REDIS_MASTER_PORT_6379_TCP_ADDR=10.0.0.11
这意味着需要有顺序的要求 —— Pod 想要访问的任何 Service 必须在 Pod 自己之前被创建,否则这些环境变量就不会被赋值。DNS 并没有这个限制。
十三、DNS
一个可选(尽管强烈推荐)集群插件 是 DNS 服务器。 DNS 服务器监视着创建新 Service 的 Kubernetes API,从而为每一个 Service 创建一组 DNS 记录。 如果整个集群的 DNS 一直被启用,那么所有的 Pod 应该能够自动对 Service 进行名称解析。
例如,有一个名称为 "my-service" 的 Service,它在 Kubernetes 集群中名为 "my-ns" 的 Namespace 中,为 "my-service.my-ns" 创建了一条 DNS 记录。 在名称为 "my-ns" 的 Namespace 中的 Pod 应该能够简单地通过名称查询找到 "my-service"。 在另一个 Namespace 中的 Pod 必须限定名称为 "my-service.my-ns"。 这些名称查询的结果是 Cluster IP。
Kubernetes 也支持对端口名称的 DNS SRV(Service)记录。 如果名称为 "my-service.my-ns" 的 Service 有一个名为 "http" 的 TCP 端口,可以对 "_http._tcp.my-service.my-ns" 执行 DNS SRV 查询,得到 "http" 的端口号。
Kubernetes DNS 服务器是唯一的一种能够访问 ExternalName 类型的 Service 的方式。 更多信息可以查看 DNS Pod 和 Service。
十四、发布服务 —— 服务类型
对一些应用(如 Frontend)的某些部分,可能希望通过外部(Kubernetes 集群外部)IP 地址暴露 Service。
Kubernetes ServiceTypes 允许指定一个需要的类型的 Service,默认是 ClusterIP 类型。
Type 的取值以及行为如下:
- ClusterIP:通过集群的内部 IP 暴露服务,选择该值,服务只能够在集群内部可以访问,这也是默认的 ServiceType。
- NodePort:通过每个 Node 上的 IP 和静态端口(NodePort)暴露服务。NodePort 服务会路由到 ClusterIP 服务,这个 ClusterIP 服务会自动创建。通过请求
: ,可以从集群的外部访问一个 NodePort 服务。 - LoadBalancer:使用云提供商的负载均衡器,可以向外部暴露服务。外部的负载均衡器可以路由到 NodePort 服务和 ClusterIP 服务。
- ExternalName:通过返回 CNAME 和它的值,可以将服务映射到 externalName 字段的内容(例如, foo.bar.example.com)。 没有任何类型代理被创建,这只有 Kubernetes 1.7 或更高版本的 kube-dns 才支持。
十五、NodePort 类型
如果设置 type 的值为 "NodePort",Kubernetes master 将从给定的配置范围内(默认:30000-32767)分配端口,每个 Node 将从该端口(每个 Node 上的同一端口)代理到 Service。该端口将通过 Service 的 spec.ports[*].nodePort 字段被指定。
如果需要指定的端口号,可以配置 nodePort 的值,系统将分配这个端口,否则调用 API 将会失败(比如,需要关心端口冲突的可能性)。
这可以让开发人员自由地安装他们自己的负载均衡器,并配置 Kubernetes 不能完全支持的环境参数,或者直接暴露一个或多个 Node 的 IP 地址。
需要注意的是,Service 将能够通过
十六、LoadBalancer 类型
使用支持外部负载均衡器的云提供商的服务,设置 type 的值为 "LoadBalancer",将为 Service 提供负载均衡器。 负载均衡器是异步创建的,关于被提供的负载均衡器的信息将会通过 Service 的 status.loadBalancer 字段被发布出去。
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
nodePort: 30061
clusterIP: 10.0.171.239
loadBalancerIP: 78.11.24.19
type: LoadBalancer
status:
loadBalancer:
ingress:
- ip: 146.148.47.155
来自外部负载均衡器的流量将直接打到 backend Pod 上,不过实际它们是如何工作的,这要依赖于云提供商。 在这些情况下,将根据用户设置的 loadBalancerIP 来创建负载均衡器。 某些云提供商允许设置 loadBalancerIP。如果没有设置 loadBalancerIP,将会给负载均衡器指派一个临时 IP。 如果设置了 loadBalancerIP,但云提供商并不支持这种特性,那么设置的 loadBalancerIP 值将会被忽略掉。

