CLOSE_WAIT问题-TCP
环境简述
要说清楚问题,先要简单说下生产环境的网络拓扑(毕竟是个网络问题对吧)
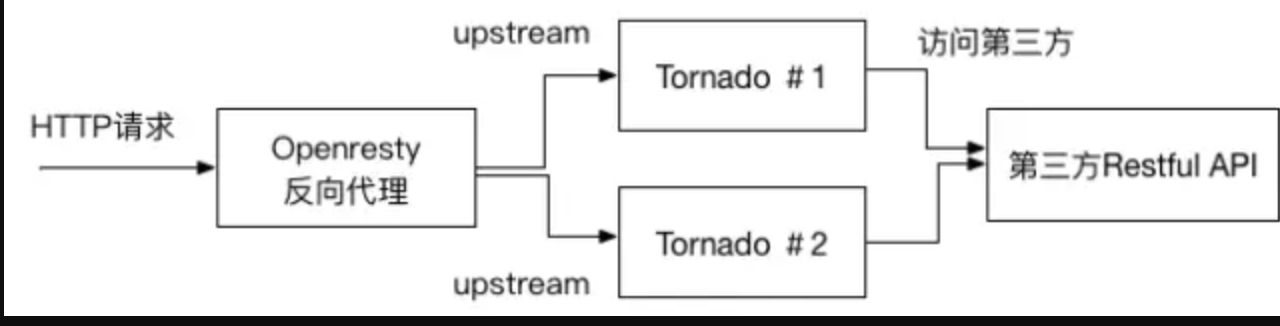
看,挺简单的对吧,一个OpenResty做SLB承受客户端请求,反响代理到几台应用服务器。由于业务要求,必须要同步调用第三方运营商的接口并返回结果到客户端。
怎么”挂“了
深夜接到某妹子电话本该是激动人心的事,但是奈何怎么都高兴不起来,因为来电是来告诉我环境挂了。赶紧问清楚,回答说是一开始响应很慢,后来就彻底拿不到数据了。
好吧,自己摸出手机试下,果然.... 此时夜里11点。
第一反应(请注意:这里开始是我的排查思路)
从开始打开电脑到电脑点亮的时间里我已经想好了一个初步的排查检查思路,既然是拿不到数据,哪有哪些可能呢?
- 是不是特例还是所有情况下的数据都获取不到?
- 是不是网络断了?
- 是不是服务停了?
- 是不是应用服务器都CPU 100%了?
- 看看监控系统有没有报警?
- 看看DB是不是被人删了?
好,因为我们有云监控,看了下
- SLB的心跳还活着,排除网络问题
- 所有服务器CPU/Memory/IO 都还在正常没有峰值
- 关键进程还在
- DB也还健在
开始检查
既然初步排除上述的问题,那下一步基本就是SSH到服务器上去看情况了。 自然从网络开始,这里要想说给很多在做或者即将做在线生产环境支持的小伙伴说的第一句话: “先听听操作系统的声音,让操作系统来告诉你问题在哪”。 不论是windows和Linux都提供了一堆小工具小命令,在过度依赖安装第三方工具前请先看看是否操作系统自带的工具已经不够支撑你了。
好,第一个检查就是本机的网络连接:netstat -anop tcp
结果:

.......此处省略100多行.....
我擦,close_wait又让我撞见了. 看了几台应用服务器都是上百个close_wait. (加起来有近千个close_wait, 发财了)。
网上有太多文章描述这个东西了所以我不会展开去解释,就浓缩成以下几点,大家参考这图理解
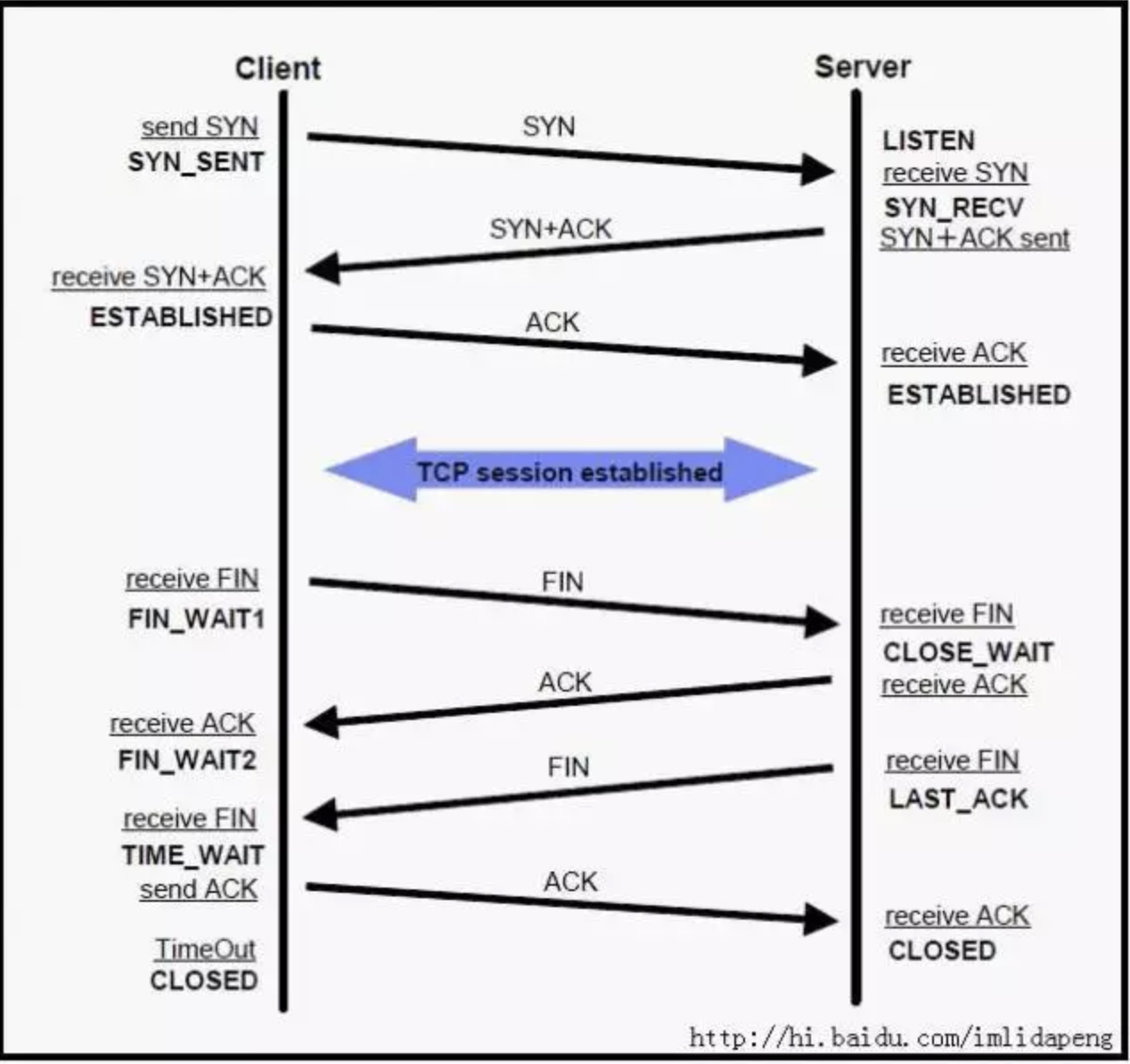
- close_wait 是TCP关闭连接过程中的一个正常状态
- close_wait 只会发生在被动关闭链接的那一端(各位姑娘们,请不要把图里的client/server和项目里的客户端服务端混淆)
- close_wait 除非你杀进程,close.wait是不会自动消失的。当然不消失意味着占着资源呢,这里就是占的FD。
看到这里基本拿不到数据的原因之一找到了,大量的close_wait,我之前项目也见过有的开发见到这种情况的直觉反应就是重启大法,其实也不能算这个做法有错,毕竟这个服务当了,客户疯了,夜已深了,你想休息了。但,这样真的对吗?
“停” 先别急着重启
如果你这时候重启了,的确立竿见影解决了当前问题,但你却失去真正解决问题的机会。这就是我想说的第二句话:保留一下现场,不是所有问题的根源都能从日志里找到的。close_wait 绝对就是这类问题,如果你是一位有过类似经历的开发或者DevOps,你到现在应该有了下面2个疑问:
- 为啥一台机器区区几百个close_wait就导致不可继续访问?不合理啊,一台机器不是号称最大可以开到65535个端口吗?
- 为啥明明有多个服务器承载,却几乎同时出了close_wait?又为什么同时不能再服务?那要SLB还有啥用呢?
好,这也是我当时的问题,让我们继续往下分析:
1. 先理顺出现close_wait的链接流向
前面说过close_wait 是关闭连接过程中的正常状态,但是正常情况下close_wait的状态很快就会转换所以很难被捕捉到。所以如果你能发现大批量的close_wait基本可以确定是出问题了。那第一个要确定是自然是连接的流向,判断依据很简单(还是nnetstat -anop tcp)

命令返回里有一栏Foreign Address,这个就是代表对方的IP地址,这个时候再结合上面那张TCP的握手图,我们就知道是哪台机器和你连接着但是却主动关闭了连接。
2. 根据项目数据请求流向还原可能的场景
知道了是哪台IP,那接下来就可以根据项目实际情况还原连接的场景。在我这里所有的close_wait都发生在和SLB的连接上。因此说明,是SLB主动关闭了连接但是多台应用服务器都没有相应ack导致了close_wait。只是这样够吗?明显不够。继续SLB作为负载均衡,基本没有业务逻辑,那它会主动关闭连接的场景有哪些?
- 进程退出(正常或非正常)
- TCP连接超时
这2个情况很好判断而且大多数情况下是第二种(我遇见的也是),如果你还记得我文章一开始的环境结构图,我想基本可以得出以下结论是:
由于调用第三方的请求API太慢而导致SLB这边请求超时引起的SLB关闭了连接.
那解决方案也很容易就有了:
- 加大SLB到应用服务器的连接超时时间
- 在调用第三方的时候采用异步请求
完了吗? (我怎么那么啰嗦。。。)
**“再等等” 还有问题没被回答 **
-
为啥一台机器区区几百个close_wait就导致不可继续访问?不合理啊,一台机器不是号称最大可以开到65535个端口吗?
-
为啥明明有多个服务器承载,却几乎同时出了close_wait? 又为什么同时不能再服务?那要SLB还有啥用呢
是啊,解释了为什么出close_wait,但并不能解释这2个问题。好吧,既然找到了第一层原因,就先重启服务让服务可以用吧。剩下的我们可以两个简单的原型代码模拟一个。此时我的目光回到了我们用的Tornodo上面来,当你有问题解释不了的时候,你还没有发现真正的问题
Tornado是一个高性能异步非阻塞的HTTP 服务器(还不明白这个啥意思的可以看 “从韩梅梅和林涛的故事中,学习一下I/O模型 ” 这篇文章,生动!!!),其核心类就是IOLoop,默认都是用HttpServer单进程单线程的方式启动 (Tornado的process.fork_processes 也支持多进程方式,但官方并不建议)。我们还是通过图来大概说下
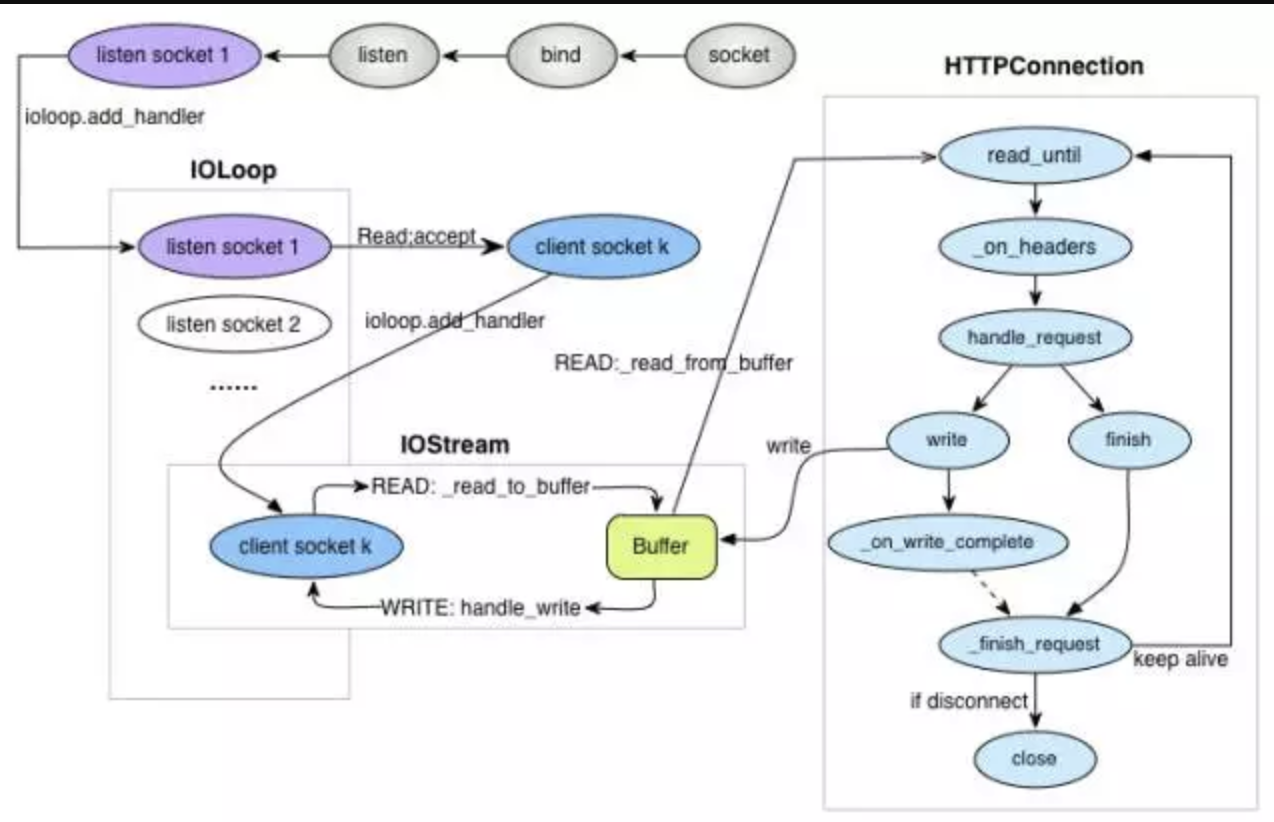
IOLoop干了啥:
-
维护每个listen socket注册的fd;
-
当listen socket可读时回调_handle_events处理客户端请求,这里面的实现就是基于epoll 模型
好,现在我们知道:
-
Tornado是单进程启动的服务,所以IOLoop也就一个实例在监听并轮询
-
IOLoop在监听端口,当对应的fd ready时会回调注册的handler去处理请求,这里的handler就是我们写业务逻辑的RequestHandler
-
如果我们启用了Tornado的 @tornado.gen.coroutine,那理论上一个请求很慢不会影响其他的请求,那一定是代码什么地方错了。
进而查看实现代码,才真相大白,虽然我们用了 @tornado.gen.coroutine 和yield,但是在向第三方请求时用的是urllib2 库。这是一个彻头彻尾的同步库,人家就不支持AIO(Tornado 有自己AsyncHTTPClient支持AIO).
由此让我们来总结下原因:
-
Tornado是单进程启动的服务,所以IOLoop也就一个实例在监听并轮询
-
Tornado在bind每个socket的时候有默认的链接队列(也叫backlog)为128个
-
由于代码错误,我们使用了同步库urllib2 做第三方请求,导致访问第三方的时候当前RequestHandler是同步的(yield不起作用),因此当IOLoop回调这个RequestHandler时会等待它返回
-
第三方接口真的不快!
最后来回答这两个问题:
- 为啥一台机器区区几百个clise_wait就导致不可继续访问?不合理啊,一台机器不是号称最大可以打开65535个端口吗?
回答:由于原因#4和#3所以导致整个IoLoop慢了,进而因为#2导致很多请求堆积,也就是说很多请求在被真正处理前已经在backlog里等了一会了。导致了SLB这端的链接批量的超时,同时又由于close_wait状态不会自动消失,导式最终无法再这个端口上创建新的链接引起了停止服务。
- 为啥明明有多个服务器承载,却几乎同时出了close_wait?又为什么同时不能再服务?那要SLB还有啥用呢?
回答:有了上一个答案,结合SLB的特性,这个也就很好解释。这就是所谓的洪水蔓延,当SLB发现下面的一个节点不可用会把请求routing到其他可用节点上,导致其他节点压力增大。也犹豫相同原因,加速了其他节点出现clise_wait.
