

python的内存回收是面试中经常会问到一个问题,今天我来给大家深度剖析下python的内存回收和缓存机制
1、引用计数器
我们知道,python是通过引用计数器来做内存回收的,下面我们来重点讲下引用计数器
提到引用计数器,我们需要先讲下python中的环状双向链表refchain。
1.1 双向链表refchain
在python程序中,创建的任意一个对象,都会加到这个refchain双向链表中
不同的类型的对象在放到refchain中会有不同的地方,也会有相同的地方
1.2 refchain结构体
可以看下,cpython中的源码中定义的结构体

PyObject这个结构体封装了四个值,其他类型的对象会基于PyObject这个结构体作为基类,在封装其他需要的类型
下面我们看不同给类型的结构体封装格式
比如float类型

比如int类型

list类型

tuple类型

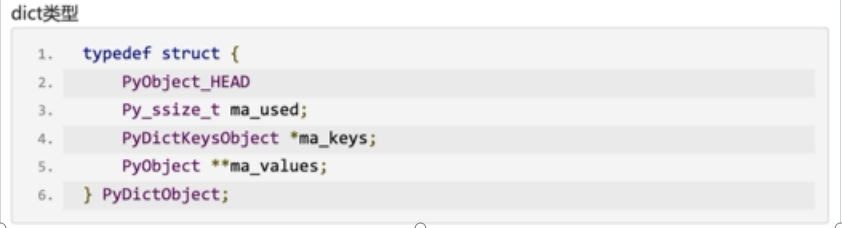
dict类型
1.3 引用计数器
我们上面讲的 引用计数器
Ob_refcnt就是引用计数器,默认是1,当有其他对象引用对象的时候,这个值就会发生变化
name = "test" #ob_refcnt的值是1 new = name #ob_refcnt的值是2 del new #ob_refcnt的值是1
当ob_refcnt为0的时候,就会对该对象做垃圾回收,会做两件事情
1、从refchain双向链表中移除
2、将这个对象进行销毁,归还内存给操作系统
2、标记清除
大家认为引用计数器的方式很牛逼,但是其实这里有个场景,引用计数器是解决不了的
# 存在双向引用的场景,引用计数器就会出问题 v1 = [1,2,3] v2 = [4,5,6] v1.append(v2) v2.append(v1) # 此时 # v1的ob_refcnt为2 # v2的ob_refcnt为2 del v1 del v2 # 此时 # v1的ob_refcnt为1 # v2的ob_refcnt为1 # # 此时v1和v2不会被回收,但是其实已经没有对象引用v1和v2了 此时就会出现内存泄露的现象
为了解决上面的场景,python又引入了标记清除
在python底层,会维护另外一个链表(A),这个链表中存放可能存在双向应用的对象。在python中,只有list,tupule、dict、set会存在双向引用的场景,如果我们创建这样的对象,这个对象会被存在到两个链表中
在python内部,会有规律的扫描这个链表A中的每个元素,检查是否有双向引用,如果有,会让双方的引用计数器分别减1,然后在判断ob_refcnt来判断是否做垃圾回收
3、分代回收
那在链表A中,扫描一次链表A还是比较耗时的,因为每个元素都要扫描一次,扫描一次的代价比较大,python是以什么规律下会触发扫描链表A呢?
在分代回收中,把链表A中的数据,也就是可能存在双向引用的元素,划成3个链表,依次来提升扫描的效率
0代:0代中的对象个数达到700个,在触发扫描一次0代链表;第一次扫描0代中的对象,如果0代中有垃圾,则回收,如果不是垃圾,则清空0代,把不是 垃圾的对象放到1代
1代:0代扫描超过10次,则1代扫描一次
如果1代中有垃圾,则回收,如果不是垃圾,则清空1代,把不是 垃圾的对象放到2代
2代:1代扫描超过10次,则2代扫描一次
如果2代中有垃圾,则回收,如果不是垃圾,则清空2代
4、缓存机制
Python中还有些内存管理的机制,用来优化性能,就是这里准备讲的缓存机制
4.1 池
在python中,为了避免重复申请内存和销毁内存,python会对一部分常见的对象,会提前把这些常见的对象提前申请好
Int类型是用池来做缓存
比如 -5,-4 .。。。。。。。256 这部分对象python认为非常常用,会在python启动的时候提前创建好对象,且不会去走销毁流程,
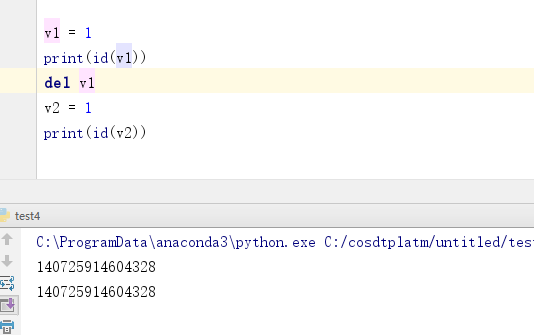
可以看到v1和v2的内存地址是一样的
4.2 free_list机制
Free_list机制(float、tupule、list、dict为典型代表)
当引用计数器ob_refcnt为0的时候,按理说应该回收的,但是在python中,为了优化性能,不会回收,而是将对象添加到free_list链表中,当作缓存,以后再次创建相同的对象,就会重新创建对象,而是直接使用free_list中的对象
v3 = 3.14 del v3 #会放到free_list中 v4 = 4.14 #会对v3的内存地址重新赋值,就不需要重新申请内存
float类型
# float类型,维护free_list链表中最多可以缓存100个float对象 v9 = 3.14 print(id(v9)) del v3 #会放到free_list中 v10 = 3.14 #会对v3的内存地址重新赋值,就不需要重新申请内存 print(id(v10)) # 当前引用计数器为0的时候,会先去判断free_list是否满,未满在缓存到free_list中,满了则销毁
list类型
# list类型,维护一个free_list对多可缓存个80个list对象 v11 = [1,2,3] print(id(v11)) del v11 v11 = ["2b","2b"] print(id(v11)) # 输出 # 2303949405888 # 2303949405888
dict类型
# dict类型,会维护一个free_list最多可缓存80个dict对象
v13 = {"k1":"v1","k2":"v2"}
print(id(v13))
del v13
v13 = {"k3":"v1","k4":"v2"}
print(id(v13))
# 2291100371392
# 2291100371392
tuple类型
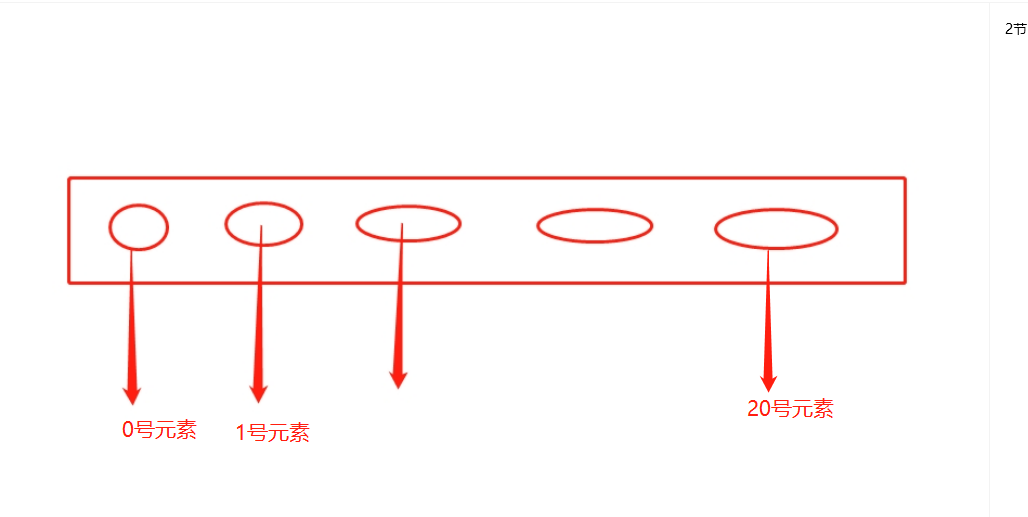
会维护一个20个元素的free_list的表。其中0号元素,缓存在只有一个元素的tuple,1号元素缓存只有2个元素的tuple。。。。。。20号元素缓存只有21个元素的tuple。其中每个元素中最多可以存储2000个列表
str类型
1、首先会把所有的ascii码元素全部会缓存起来,不会销毁
2、除此之外,python还对常用的字符串做了驻留机制,争对只有数字,字母,下划线组成的字符串做了驻留缓存,如果内存中存在相同的值,则不会去重新申请内存,而是直接使用驻留内存中的地址

