
一、zookeeper概述
a、zookeeper是一个开源的分布式的项目,为分布式业务提供协调服务的apache顶级项目
那什么是分布式的呢,通俗的说就是多个机器可以同时去处理一件事情
b、zookeeper相当于大数据生态体系的润滑剂,保存各个组件的配置文件;zoo是什么意思,动物园的意思,而大数据各个组件的标志都是一些动物,所以zookeeper又被称为动物园的管理员,可以管理大数据生态体系的很多组件
c、zookeeper的本质就是:文件系统+通知机制
二、工作机制
a、zk的设计是基于观察者模式设计的分布式服务管理框架,他负责存储和管理大家都关心的数据,然后接受观察者注册
b、一旦这些数据发生变化,zk就将负责通知已经在zk上注册的那些观察者,观察者会通过会根据相应的变化做出相应的行为
什么是观察者模式,通俗的讲就是一个人在干活,另外一个人在监视,就比如我们现在在这里培训,摄像头就是一个观察者
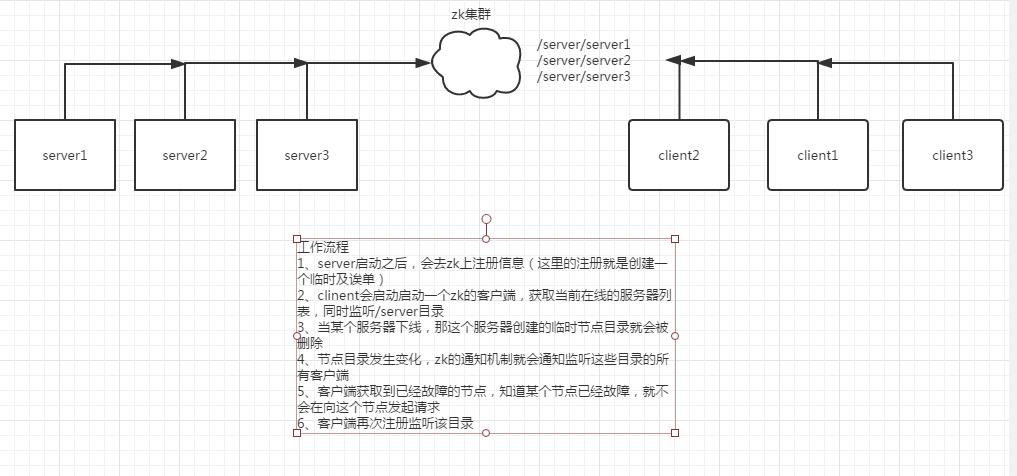
工作机制如何
三、zoopeeper特点
四、数据结构
zookeeper的数据模型结构和unix的文件系统类似,整体上可以看做是一个树,每个节点称为一个ZNode,每一个ZNode默认只只能够存储1MB的数据,每个ZNode都可以通过路径唯一标示

五、应用场景
zk可以提供如下服务,统一命名服务,统一配置管理,统一集群管理,服务器节点动态上下线,软负载均衡
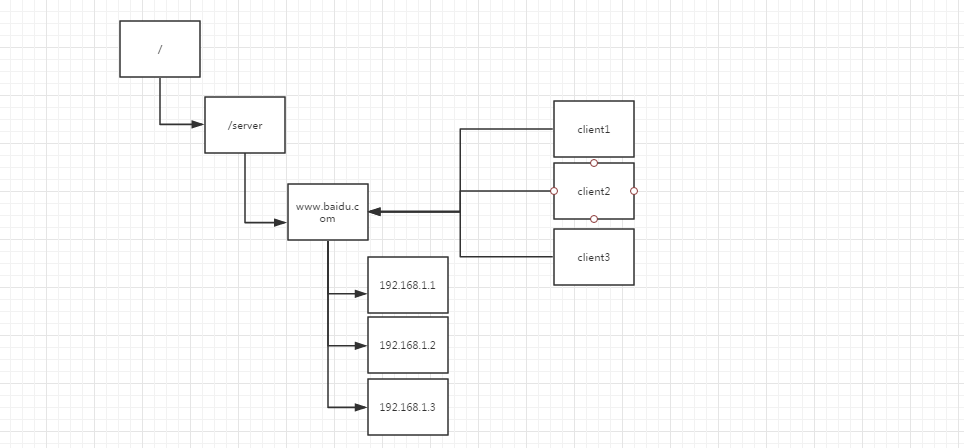
a、统一命名服务
在分布式环境中,经常需要对应用服务进行统一命名,便于识别,例如ip不容易记住,而域名容易记住
b、统一配置管理
在分布式环境中,配置同步是非常常见的,这里监听模式就体现的非常的明显
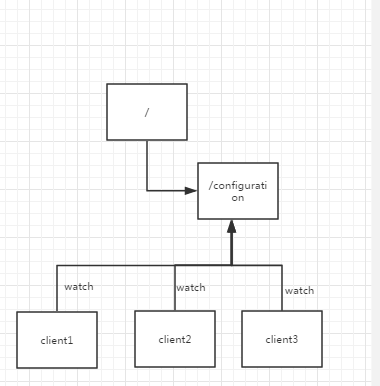
一般在一个分布式集群中,所有节点的配置是一致的,比如kafka集群 ;而且一旦配置更改之后,所有的节点都可以快速同步到最新的配置
我们可以将配置文件写在一个ZNode中,然后集群中所有的节点都监控这个节点,一旦配置节点内容发生变化,则立刻更新本地配置
c、统一集群管理
在分布式环境中,实时掌握每个节点的状态是非常有必要的。我们可以将每个节点都注册到一个节点中,只要监听这个节点的变化就可以获取节点的的状态变化
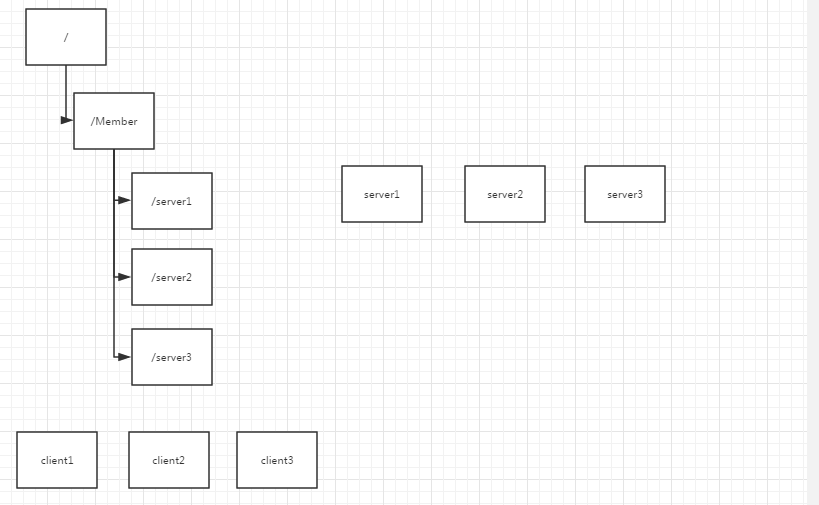
首先每个服务器启动后,到zk上创建一个临时节点目录
然后client去获取当前在线的服务器的列表,同时监听目录信息
如果一个服务器节点故障,那么该节点创建的临时节点目录被删除
客户端收到通知,获取最新的在线列表服务器
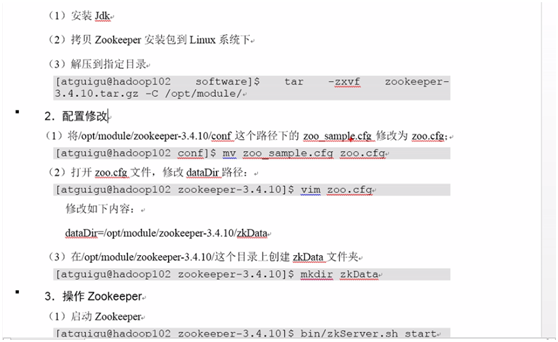
六、zk安装
七、选举机制
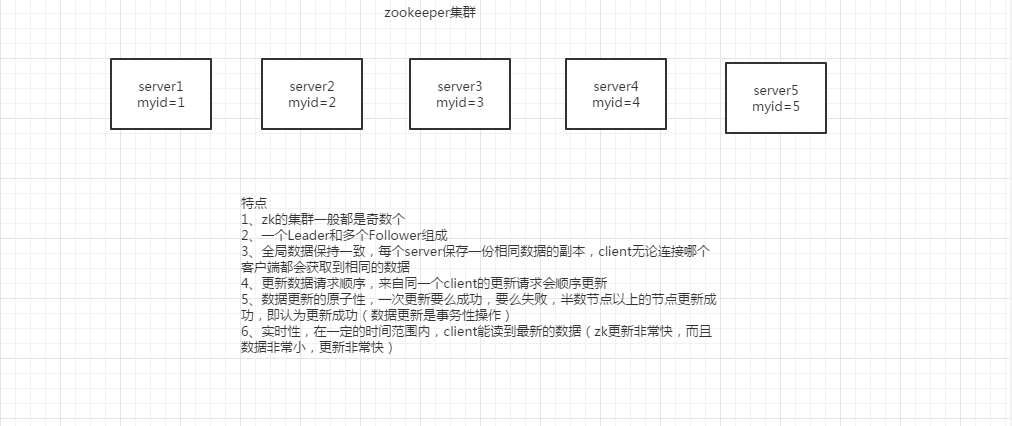
a、半数机制,集群中半数节点存活,则集群可用,所以zk集群的节点数都为奇数个
b、zk在配置文件没有指定Leader和Follower,但是在实际工作中是有一个Leader和多Follower的,Leader是临时选举产生的
c、假设有5个服务器组成zk集群,myid分别为1,2,3,4,5,同时他们都是最新启动的,假设他们是按照顺序启动的,节点1启动成功,发现没有Leader,那么他投自己一票;节点2启动成功后,发现集群中没有Leader,且自己的myid为2,节点1的myid为1,自己的myid较大,那么他投自己一票,这个时候节点1发现节点的2的myid比自己大,那么节点1就会投节点2一票,这个时候节点2有2票,但是还没有过半数;这个时候节点3启动成功,他的myid是3,节点3发现集群中没有Leader,那么他投自己一票,节点1和节点2发现节点3的myid最大,那么他们会投节点3一票,此时节点3有三票,超过半数,那么节点3就是Leader,这个时候节点4和节点5启动,虽然他们的myid较大,但是也不会在进行选举了
八、zk的节点类型
a、持久型:客户端和服务端断开连接后,创建的节点不会删除
b、持久型顺序节点:客户端和服务端断开连接后,创建的节点不会删除,只是在节点名称上会加上单调递增的序号
c、短暂型:客户端和服务端断开连接后,创建的节点会被删除
d、短暂型顺序节点:客户端和服务端断开连接后,创建的节点会被删除,只是在节点名称上会加上单调递增的序号
九、节点操作
a、创建一个持久节点
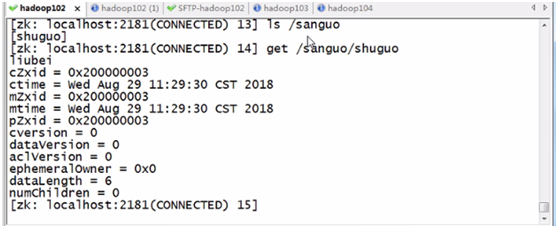
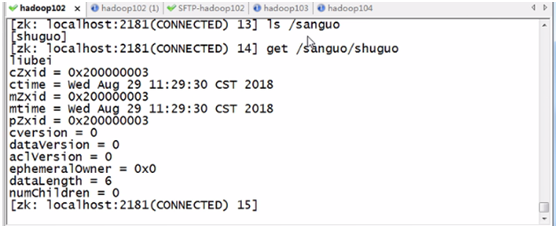
b、查看节点内容
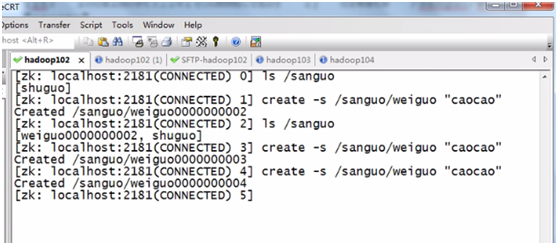
c、创建一个持久有序号的节点

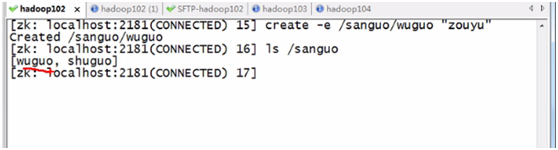
c、创建一个短暂的节点
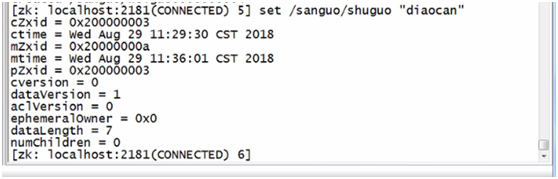
d、修改节点内容
e、监听节点的内容
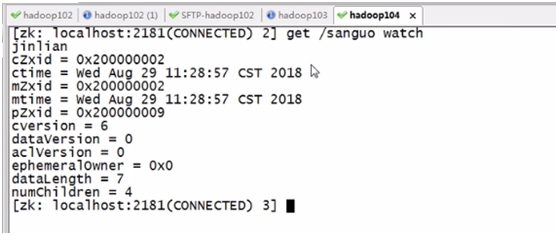
如果节点内容发生变化,则会有监听信息
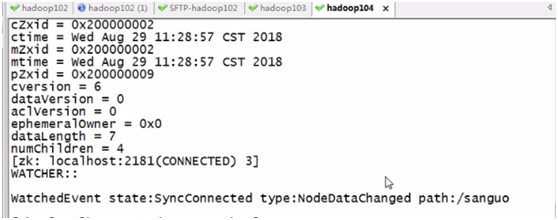
接听只是一次有效,第二次修改监听就没有效果了,需要重新监听
f、删除一个节点

十、zk写数据流程
a、client向zk集群发现写数据请求
b、如果该zk节点不是Leader,则这个请求会被转发给Leader,Leader会把请求在整个集群广播
c、节点手动请求后会通知Leader,如果半数以上的节点写入成功,则认为写入成功
d、Leader手动写入成功的返回后,则会通知Client,这次写入成功
十一、zk读数据流程
读流程相对节点,每个节点收到读请求,就会直接返回,不需要通过Leader

 浙公网安备 33010602011771号
浙公网安备 33010602011771号