


1、通过requests.get方法
1 2 3 4 | r = requests.get("http://200.20.3.20:8080/job/Compile/job/aaa/496/artifact/bbb.iso")with open(os.path.join(os.path.dirname(os.path.abspath("__file__")),"bbb.iso"),"wb") as f: f.write(r.content) |
2、urllib2方法
1 2 3 4 5 6 7 | import urllib2print "downloading with urllib2"url = '"http://200.21.1.22:8080/job/Compile/job/aaa/496/artifact/bbb.iso"'f = urllib2.urlopen(url)data = f.read()with open(os.path.join(os.path.dirname(os.path.abspath("__file__")),"bbb.iso"),"wb") as f: f.write(data) |
3、下载大文件
很多时候,我们下载大文件python报内存错误,你打开任务管理器,会很明显的看到python程序的内存在不停的增大,最终会导致程序奔溃
self._content = bytes().join(self.iter_content(CONTENT_CHUNK_SIZE)) or bytes()
MemoryError
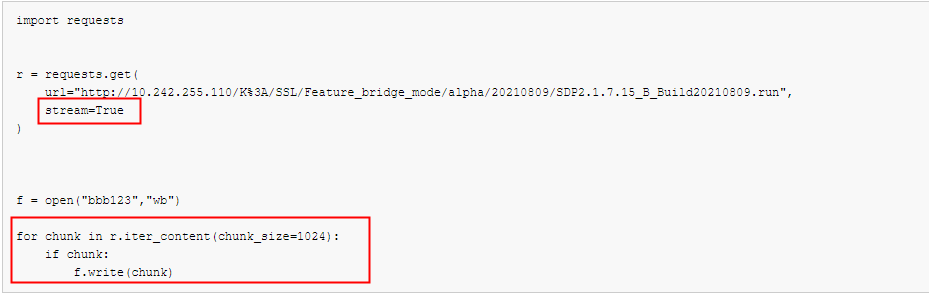
我们可以采用下面的代码来解决大文件下载的问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | import requestsr = requests.get( url="http://10.242.255.110/K%3A/SSL/Feature_bridge_mode/alpha/20210809/SDP2.1.7.15_B_Build20210809.run", stream=True)f = open("bbb123","wb")for chunk in r.iter_content(chunk_size=1024): if chunk: f.write(chunk) |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
2018-07-22 django的model操作整理
2017-07-22 python之socket运用之传输大文件
2017-07-22 python之socket运用之执行命令