

一、先看下django的admin是如何实现过滤操作
首先在配置类中顶一个list_filter的列表,把要过滤的字段作为元素写i进去就可以了
class testbook(admin.ModelAdmin):
# 第一步,定义一个函数,必须要接受三个参数
def test_action(self,request,queryset):
"""
:param request:
:param queryset:这个就是需要批量操作的queryset对象
:return:
"""
print(queryset)
# 第二步,为这个函数对象赋值一个新的属性
test_action.short_description = "测试批量操作的函数"
# 第三步,将函数对象添加到actions这个列表中
actions = [test_action]
list_filter = ["auther","publish"]
重点是这里

最后我们看下页面的效果
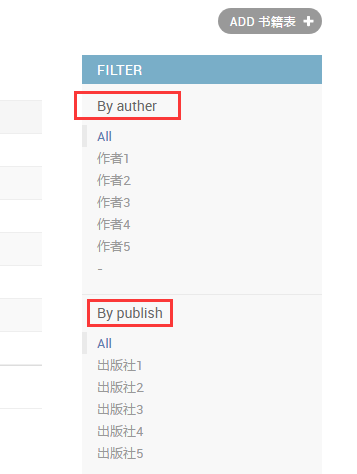
下面我们重点看下点击过滤的元素的url
先点击一下作者2

然后在点击一下出版社2
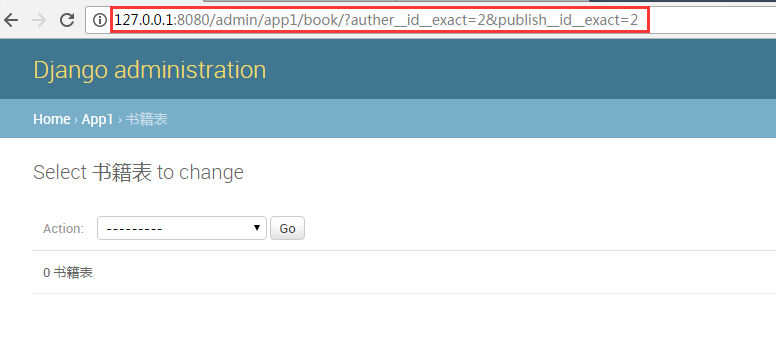
二、下面在我们自己是如何实现类似Django的admin的过滤操作
1、先把用到的知识点梳理一下
.active{
color: #2b542c!important;
}
如果一个class的属性优先级不够,可以用上面的方式来实现
2、从request.GET中拿到参数,然后把这个参数中的一些数值改一下,然后在渲染回到GET方式在url中传参的样式,用urlencode方法
import copy
parms = copy.deepcopy(self.request.GET)
parms[filter_str] = obj.id
_url = "?{url}".format(url = parms.urlencode())
3、通过字段的字符串去获取对应的字段对象,然后在通过字段对象获取这个字段对象的表对象的方法,这里注意,只有一对多,一对一,外键的字段可以这样操作
filter_obj = self.config.model._meta.get_field(filter_str)
# 通过字符串拿到这个字符串对应的字段对象
# filter_obj
# app1.book.auther <
#
# class 'django.db.models.fields.related.ManyToManyField'>
#
# filter_obj
# app1.book.publish <
#
# class 'django.db.models.fields.related.ForeignKey'>
#
# filter_obj
# app1.book.price <
#
# class 'django.db.models.fields.DecimalField'>
data_list = filter_obj.rel.to.objects.all()
# <QuerySet [<auther: 作者1>, <auther: 作者2>, <auther: 作者3>, <auther: 作者4>, <auther: 作者5>]>
# < QuerySet[ < publist: 出版社1 >, < publist: 出版社2 >, < publist: 出版社3 >, < publist: 出版社4 >, < publist: 出版社5 >] >
3、判断字典中是否有某个k,这里直接用get方法
if parms.get("p",None):
del parms["p"]
# 这 if parms.get("p",None):
del parms["p"]
# 这里做一个处理,点击过滤,把page的参数干掉里做一个处理,点击过滤,把page的参数干掉
4、判断某个实例是否为某个类的实例,下面这个例子是判断i_obj这个对象是否为一个多对多这个类的实例的,这个类必须要用元组传递进去
from django.db.models.fields.related import ManyToManyField
i_obj = obj._meta.get_field(i)
if isinstance(i_obj,(ManyToManyField,)):
many = getattr(obj, i)
many_query_set = many.all()
temp = ""
for o in many_query_set:
temp = temp + str(o) + "--"
先导入类,然后在判断

下面我们看下我们的过滤是如何实现的
1、先看下页面的效果,右边就是我们实现的效果
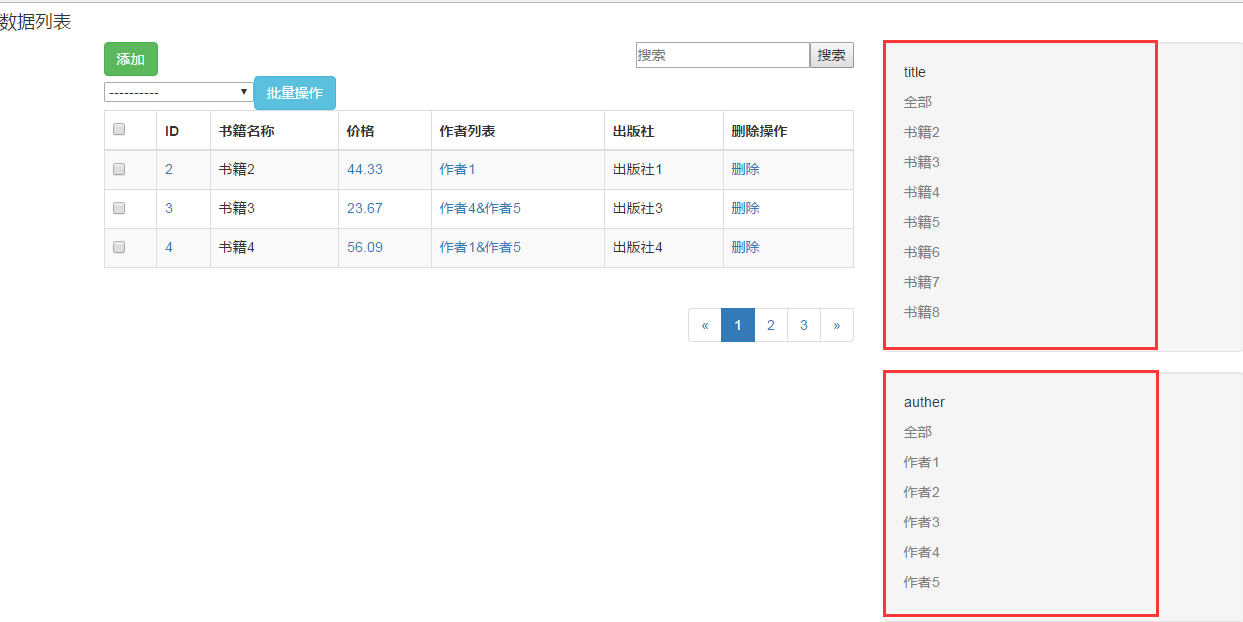
2、首先在模型表的配置类里定了一个我们要支持的过滤的字段
class bookclass(stark.Starkclass):
list_display = ["id","title","price","auther","publish"]
list_display_links = ["id","price","auther"]
search_fields = ["title","price"]
def test_action(self,request,queryset):
print(queryset,)
actions = [test_action]
# test_action.__name__ = "测试批量操作的函数"
test_action.short_description = "测试批量操作的函数"
modelformclass = mybookmodelform
list_filter = ["title","auther", "publish",]

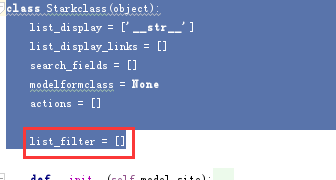
当然我们也需要在父类中定义了一个同样的字段,这个是我们的常规套路
class Starkclass(object):
list_display = ['__str__']
list_display_links = []
search_fields = []
modelformclass = None
actions = []
list_filter = []
3、然后我们看下前端的代码的实现
<div class="col-md-4">
<div class="filter">
{% for k,v in get_filter.items %}
<div class="well">
<p>{{ k }}</p>
{% for tag in v %}
<p>{{ tag|safe }}</p>
{% endfor %}
</div>
{% endfor %}
</div>
这里我们在截图看下前端的效果

这里其实一个面板,我们使用了bootstrap的well的样式,我们后端传递给前端的其实是一个字段,字典的k值是我们的要过滤的字段,字典的v值是我们这个字段对应的所有的值的a标签
4、下面我们看下具体的视图函数,首先因为这个和显示相关,我们还是把主要代码放在showlist这个类中来实现
get_filter = showlist.get_filter_link_tag()
return render(request,"list_view.html",{"data_list":data_list,"title_list":title_list,"page_str":page_str,"search_fields":self.search_fields,"action_str":action_str,
"get_filter":get_filter
})
调用showlist类的get_filter_link_tag这个函数,然后将返回值渲染到前端
5、下面我们看下get_filter_link_tag这个函数的代码
def get_filter_link_tag(self):
link_dict = {}
import copy
for filter_str in self.config.list_filter:
parms = copy.deepcopy(self.request.GET)
# 通过字符串拿到这个字符串对应的字段对象
filter_obj = self.config.model._meta.get_field(filter_str)
print("filter_obj",filter_obj,type(filter_obj))
# filter_obj
# app1.book.auther <
#
# class 'django.db.models.fields.related.ManyToManyField'>
#
# filter_obj
# app1.book.publish <
#
# class 'django.db.models.fields.related.ForeignKey'>
#
# filter_obj
# app1.book.price <
#
# class 'django.db.models.fields.DecimalField'>
# 获取当前的参数值,主要是为了吧选中的a标签加一个active的属性
cid = int(self.request.GET.get(filter_str,0))
from django.db.models.fields.related import ManyToManyField
from django.db.models.fields.related import ForeignKey
if isinstance(filter_obj,(ManyToManyField,ForeignKey)):
print(filter_obj.rel.to.objects.all())
# 通过字段对象跨表查询,必须是ManyToManyField或者ForeignKey的字段,
# <QuerySet [<auther: 作者1>, <auther: 作者2>, <auther: 作者3>, <auther: 作者4>, <auther: 作者5>]>
# < QuerySet[ < publist: 出版社1 >, < publist: 出版社2 >, < publist: 出版社3 >, < publist: 出版社4 >, < publist: 出版社5 >] >
data_list = filter_obj.rel.to.objects.all()
else:
data_list = self.config.model.objects.all()
temp = []
# 这里要加一个全选的a标签,如果点出版社的是全部,则把参数中的出版社的标签全部去掉,如果点的是作者的全部,则把参数中作者的标签全部去掉
all_dict = copy.deepcopy(parms)
if all_dict:
if all_dict.get(filter_str,None):
del all_dict[filter_str]
print(parms,"parms",filter_str)
_url = "?{url}".format(url=all_dict.urlencode())
all_label = "<a href='{url}'>全部</a>".format(url = _url)
temp.append(all_label)
# 处理全部的a标签的的代码
# --------------------------------------------------------------------
for obj in data_list:
parms[filter_str] = obj.id
if parms.get("p",None):
del parms["p"]
# 这里做一个处理,点击过滤,把page的参数干掉
_url = "?{url}".format(url = parms.urlencode())
# print(cid,obj.id,"------------------------------")
# 这里做一下判断,如果当前的id和现在循环的id一样,则需要给这个a标签加一个属性,用以区分
if int(cid) == obj.id:
a_str = "<a class='active' href='{url}'>{obj}</a>".format(obj=str(obj), url=_url)
else:
a_str = "<a href='{url}'>{obj}</a>".format(obj=str(obj),url = _url)
temp.append(a_str)
link_dict[filter_str] = temp
return link_dict
首先循环我们定义的过滤的字典,通过字符串拿到这个字符串对应的字段对象

然后拿到GET方式传递过来的参数,这个参数主要是判断当然是否有我这个字段的过滤规则,有的话,则把当前过滤规则对应的a标签用active标记出来
# 获取当前的参数值,主要是为了吧选中的a标签加一个active的属性
cid = int(self.request.GET.get(filter_str,0))
这里主要分别对多对多,一对多和普通字段做过滤,因为多对多字段和一对多可以做跨表查询,而普通字段是不能做跨表查询
from django.db.models.fields.related import ManyToManyField
from django.db.models.fields.related import ForeignKey
if isinstance(filter_obj,(ManyToManyField,ForeignKey)):
print(filter_obj.rel.to.objects.all())
# 通过字段对象跨表查询,必须是ManyToManyField或者ForeignKey的字段,
# <QuerySet [<auther: 作者1>, <auther: 作者2>, <auther: 作者3>, <auther: 作者4>, <auther: 作者5>]>
# < QuerySet[ < publist: 出版社1 >, < publist: 出版社2 >, < publist: 出版社3 >, < publist: 出版社4 >, < publist: 出版社5 >] >
data_list = filter_obj.rel.to.objects.all()
else:
data_list = self.config.model.objects.all()
下面这段代码主要是为了处理all标签的,点击一下all,会把自己这个面板的字段对应的过滤参数去掉
# 这里要加一个全选的a标签,如果点出版社的是全部,则把参数中的出版社的标签全部去掉,如果点的是作者的全部,则把参数中作者的标签全部去掉
all_dict = copy.deepcopy(parms)
if all_dict:
if all_dict.get(filter_str,None):
del all_dict[filter_str]
print(parms,"parms",filter_str)
_url = "?{url}".format(url=all_dict.urlencode())
all_label = "<a href='{url}'>全部</a>".format(url = _url)
temp.append(all_label)
这里的代码主要是把参数中的页码相关参数去掉,我们点击一下过滤会有问题
for obj in data_list:
parms[filter_str] = obj.id
if parms.get("p",None):
del parms["p"]
# 这里做一个处理,点击过滤,把page的参数干掉
_url = "?{url}".format(url = parms.urlencode())
下面的代码就是返回一个a标签了的字典,也就是渲染在前端的字典
# 这里做一下判断,如果当前的id和现在循环的id一样,则需要给这个a标签加一个属性,用以区分
if int(cid) == obj.id:
a_str = "<a class='active' href='{url}'>{obj}</a>".format(obj=str(obj), url=_url)
else:
a_str = "<a href='{url}'>{obj}</a>".format(obj=str(obj),url = _url)
temp.append(a_str)
link_dict[filter_str] = temp
return link_dict
还有一个就是显示数据相关,我们页面显示的数据应该是过滤后的数据
q_obj = self.get_search(request)
q_filter_obj = self.get_filter(request)
if q_obj and q_filter_obj:
new_data_list = self.model.objects.all().filter(q_obj).filter(q_filter_obj)
elif q_obj and not q_filter_obj:
new_data_list = self.model.objects.all().filter(q_obj)
elif not q_obj and q_filter_obj:
new_data_list = self.model.objects.all().filter(q_filter_obj)
else:
new_data_list = self.model.objects.all()
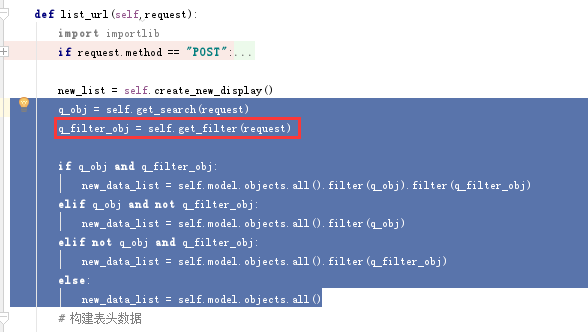
我们看到这里把获取过滤字段重新写在一个函数中了
下面我们看下这个函数,这里同样用到了Q对象,不过这里的Q对象是and的关系,之前我们做的search是or的关系
def get_filter(self,request):
from django.db.models import Q
q_filter_obj = Q()
q_filter_obj.connector = "and"
for k in self.list_filter:
if request.GET.get(k,None):
temp = (k,request.GET.get(k))
q_filter_obj.children.append(temp)
print(q_filter_obj,"q_filter_obj")
return q_filter_obj
最后我们把filter相关的所有的代码粘贴来,供大家学习
def get_filter_link_tag(self):
link_dict = {}
import copy
for filter_str in self.config.list_filter:
parms = copy.deepcopy(self.request.GET)
# 通过字符串拿到这个字符串对应的字段对象
filter_obj = self.config.model._meta.get_field(filter_str)
print("filter_obj",filter_obj,type(filter_obj))
# filter_obj
# app1.book.auther <
#
# class 'django.db.models.fields.related.ManyToManyField'>
#
# filter_obj
# app1.book.publish <
#
# class 'django.db.models.fields.related.ForeignKey'>
#
# filter_obj
# app1.book.price <
#
# class 'django.db.models.fields.DecimalField'>
# 获取当前的参数值,主要是为了吧选中的a标签加一个active的属性
cid = int(self.request.GET.get(filter_str,0))
from django.db.models.fields.related import ManyToManyField
from django.db.models.fields.related import ForeignKey
if isinstance(filter_obj,(ManyToManyField,ForeignKey)):
print(filter_obj.rel.to.objects.all())
# 通过字段对象跨表查询,必须是ManyToManyField或者ForeignKey的字段,
# <QuerySet [<auther: 作者1>, <auther: 作者2>, <auther: 作者3>, <auther: 作者4>, <auther: 作者5>]>
# < QuerySet[ < publist: 出版社1 >, < publist: 出版社2 >, < publist: 出版社3 >, < publist: 出版社4 >, < publist: 出版社5 >] >
data_list = filter_obj.rel.to.objects.all()
else:
data_list = self.config.model.objects.all()
temp = []
# 这里要加一个全选的a标签,如果点出版社的是全部,则把参数中的出版社的标签全部去掉,如果点的是作者的全部,则把参数中作者的标签全部去掉
all_dict = copy.deepcopy(parms)
if all_dict:
if all_dict.get(filter_str,None):
del all_dict[filter_str]
print(parms,"parms",filter_str)
_url = "?{url}".format(url=all_dict.urlencode())
all_label = "<a href='{url}'>全部</a>".format(url = _url)
temp.append(all_label)
# 处理全部的a标签的的代码
# --------------------------------------------------------------------
for obj in data_list:
parms[filter_str] = obj.id
if parms.get("p",None):
del parms["p"]
# 这里做一个处理,点击过滤,把page的参数干掉
_url = "?{url}".format(url = parms.urlencode())
# print(cid,obj.id,"------------------------------")
# 这里做一下判断,如果当前的id和现在循环的id一样,则需要给这个a标签加一个属性,用以区分
if int(cid) == obj.id:
a_str = "<a class='active' href='{url}'>{obj}</a>".format(obj=str(obj), url=_url)
else:
a_str = "<a href='{url}'>{obj}</a>".format(obj=str(obj),url = _url)
temp.append(a_str)
link_dict[filter_str] = temp
return link_dict
q_filter_obj = self.get_filter(request)
if q_obj and q_filter_obj:
new_data_list = self.model.objects.all().filter(q_obj).filter(q_filter_obj)
elif q_obj and not q_filter_obj:
new_data_list = self.model.objects.all().filter(q_obj)
elif not q_obj and q_filter_obj:
new_data_list = self.model.objects.all().filter(q_filter_obj)
else:
new_data_list = self.model.objects.all()
def get_filter(self,request):
from django.db.models import Q
q_filter_obj = Q()
q_filter_obj.connector = "and"
for k in self.list_filter:
if request.GET.get(k,None):
temp = (k,request.GET.get(k))
q_filter_obj.children.append(temp)
print(q_filter_obj,"q_filter_obj")
return q_filter_obj

