
前言
在日常的运维过程中,对系统日志和业务日志的处理比较重要,对于以后的数据分析、排查异常问题有很重的作用。今天就分享一个自己基于kafka+ELK+filebeat的日志记录分析平台。
组件介绍
- Elasticsearch
Elasticsearch(ES)是一个基于Lucene构件的开源、分布式、RESTful接口全文搜索引擎。ES还是一个分布式文档数据库,其中每个字段均是被索引的数据且可被搜索,它能够扩展至数以百计的服务器存储以及处理PB级别的数据。它可以在很短的时间内在存储、搜索和分析大量的数据。它通常作为具有复杂所搜场景情况下的核心发动机。 - kibana
Kibana 是一种开源数据可视化和挖掘工具,可以用于日志和时间序列分析、应用程序监控和运营智能使用案例。它提供了强大且易用的功能,例如直方图、线形图、饼图、热图和内置的地理空间支持。可以为Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面。 - Logstash
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。 - kafka
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等。 - filebeat
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
原理图
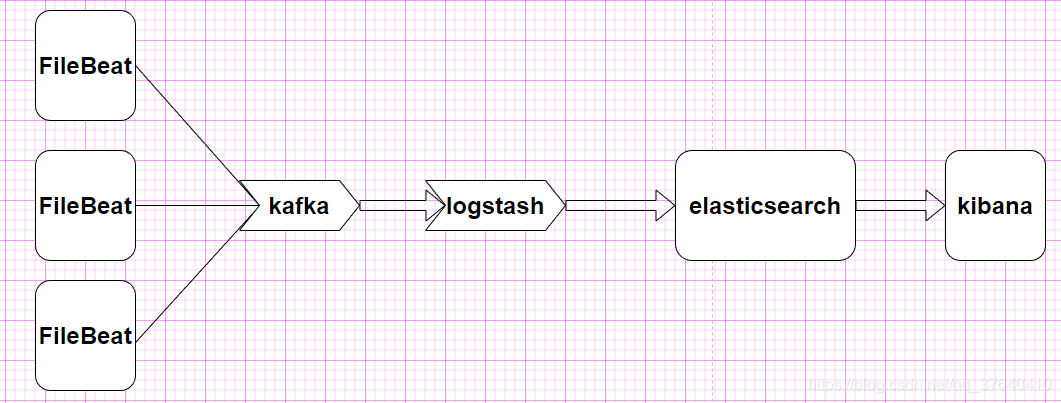
FileBeat收集日志到kafka;logstash读取kafka缓冲区数据,经过过滤,输出到es中,最终将日志通过kibana进行展示。
环境介绍
- 操作系统:CentOS Linux release 7.8.2003
- zookeeper:3.4.6
- kafka:2.4.1
- elasticsearch:6.4.3
- kibana:6.4.3
- logstash:6.4.3
- Filebeat:6.4.3
安装
-
elasticsearch和kibana安装
请移步到 跳转链接 -
安装kafka
请移步到 跳转链接 -
logstash安装
3.1 下载安装包 下载链接 ,选择合适的版本进行下载。
![在这里插入图片描述]()
3.2 上传服务器,并解压,目录结构如下:
![在这里插入图片描述]()
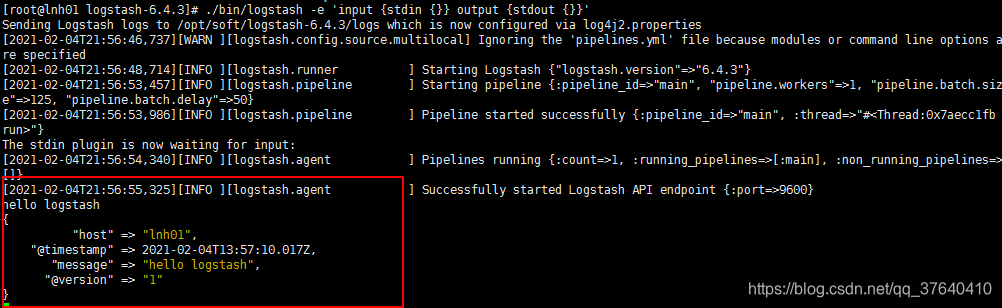
3.3 测试logstash是否可以正常运行
命令如下:./bin/logstash -e 'input {stdin {}} output {stdout {}}'
![在这里插入图片描述]()
-
FileBeat安装
4.1 下载安装包 跳转链接
4.2 启动方式
1.) nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 & 将所有标准输出及标准错误输出到/dev/null空设备,即没有任何输出
2.) nohup ./filebeat -e -c filebeat.yml > filebeat.log & 输出到filebeat.log文件中,方便排查
日志收集与展示
-
收集/opt/soft/logs/*.log下的日志信息,输出到Kafka中,配置如下:
#=========================== Filebeat inputs ============================= filebeat.inputs: - type: log # 如果为true标识启用此输入配置 enabled: true # 需要监听的文件路径,监听/opt/soft/logs下所有以.log结尾的文件,可以配置多个路径 paths: - /opt/soft/logs/*.log # 排除行。要批次的政策表达式列表。它会从列表中删除与任何正则表达式匹配的行。 # 会排除以 DBG 开头的日志,默认不会删除任何行日志 #exclude_lines: ['^DBG'] # 包括行。要匹配的正则表达式列表。它从列表中导出与任何正则表达式匹配的行。 ## 会包含以ERR、WARN的行日志信息 #include_lines: ['^ERR', '^WARN'] # 排除文件。要匹配的正则表达式列表。Filebeat从列表中删除与任何正则表达式匹配的文件。 # 默认情况下,不会删除任何文件。如果与include_lines同时出现,会限制性前者。与顺序无关。 #exclude_files: ['.gz$'] #============================= Filebeat modules =============================== filebeat.config.modules: # 配置加载的Glob模式 path: ${path.config}/modules.d/*.yml # 如果为true以启动配置重新加载 reload.enabled: false # #reload.period: 10s output.kafka: # kafka集群地址,以逗号隔开 hosts:[lnh01:9092,lnh02:9092,lnh03:9092] # topic,如果没有,会自动创建 topic: testTopic # 应答模式,默认为1 等待所有副本提交之后,安全等级最高 required_acks: 1 # 如果为true标识启用此输入配置 enabled: 1 -
启动filebeat(先启动kafka集群)
2.1 命令:./filebeat -e -c filebeat.yml
2.2 查看kafka所有topic
命令:bin/kafka-topics.sh --zookeeper lnh01:2181 --list
![在这里插入图片描述]()
注:如果是首次,则没有testTopic信息,当有日志进行收集的时候,判断是否有该topic,如果没有,会进行自动创建。
2.3 模拟向/opt/soft/logs中追加信息
echo '1111111111' > /opt/soft/logs/a.log
2.4 启动kafka消费者,查看是否消费成功
./kafka-console-consumer.sh --bootstrap-server lnh01:9092 --topic testTopic --from-beginning
![在这里插入图片描述]()
注: --from-beginning 表示从头开始消费
2.5 消费的具体内容如下:{ "@timestamp":"2021-02-04T15:05:33.773Z", "@metadata":{ "beat":"filebeat", "type":"doc", "version":"6.4.3", "topic":"testTopic" }, "beat":{ "name":"lnh01", "hostname":"lnh01", "version":"6.4.3" }, "host":{ "name":"lnh01" }, "source":"/opt/soft/logs/a.log", "offset":0, "message":"1111111111", "prospector":{ "type":"log" }, "input":{ "type":"log" } } -
配置logstash
3.1 从kafka中消费消息,过滤,输入到elasticsearch中,配置如下:# Sample Logstash configuration for creating a simple # Beats -> Logstash -> Elasticsearch pipeline. input { kafka{ #broker 5.x版本以前为 zookeeper的地址 ,5.x版本以后为kafka的地址 bootstrap_servers => ["lnh01:9092"] # 客户端id client_id => "clientTestId" # 消费者组id group_id => "groupTestId" #偏移量,从最新的开始消费 auto_offset_reset => "latest" #消费线程数,不大于分区个数 consumer_threads => 1 #此属性会将当前topic、offset、group、partition等信息也带到message中 decorate_events => "true" #消费主题 topics => ["testTopic"] #类型,区分输出不同索引 type => "kafka-to-es" #es格式为json,如果不加,整条数据变成一个字符串存储到message字段里面 codec => "json" } } filter{ if [@metadata][kafka][topic] == "testTopic" { mutate { #索引名称必须小写,否则报出异常信息:Invalid index name add_field => {"[@metadata][index]" => "kafka-testtopic01-%{+YYYY.MM.dd}"} } } #移除多余的字段 mutate { remove_field => ["kafka"] } } output { if [type] == "kafka-to-es" { elasticsearch { # es集群地址 hosts => ["lnh02:9200"] #输出到该索引 index => "%{[@metadata][index]}" timeout => 500 } } }如果使用了decorate_events =true ,从logstash控制台打印信息如下:
"kafka":{"consumer_group":"groupTestId","partition":0,"offset":10580514,"topic":"testTopic","key":null}3.2 执行logstash
命令:./bin/logstash -f /opt/soft/logstash-6.4.3/config/kafka-to-es.conf -
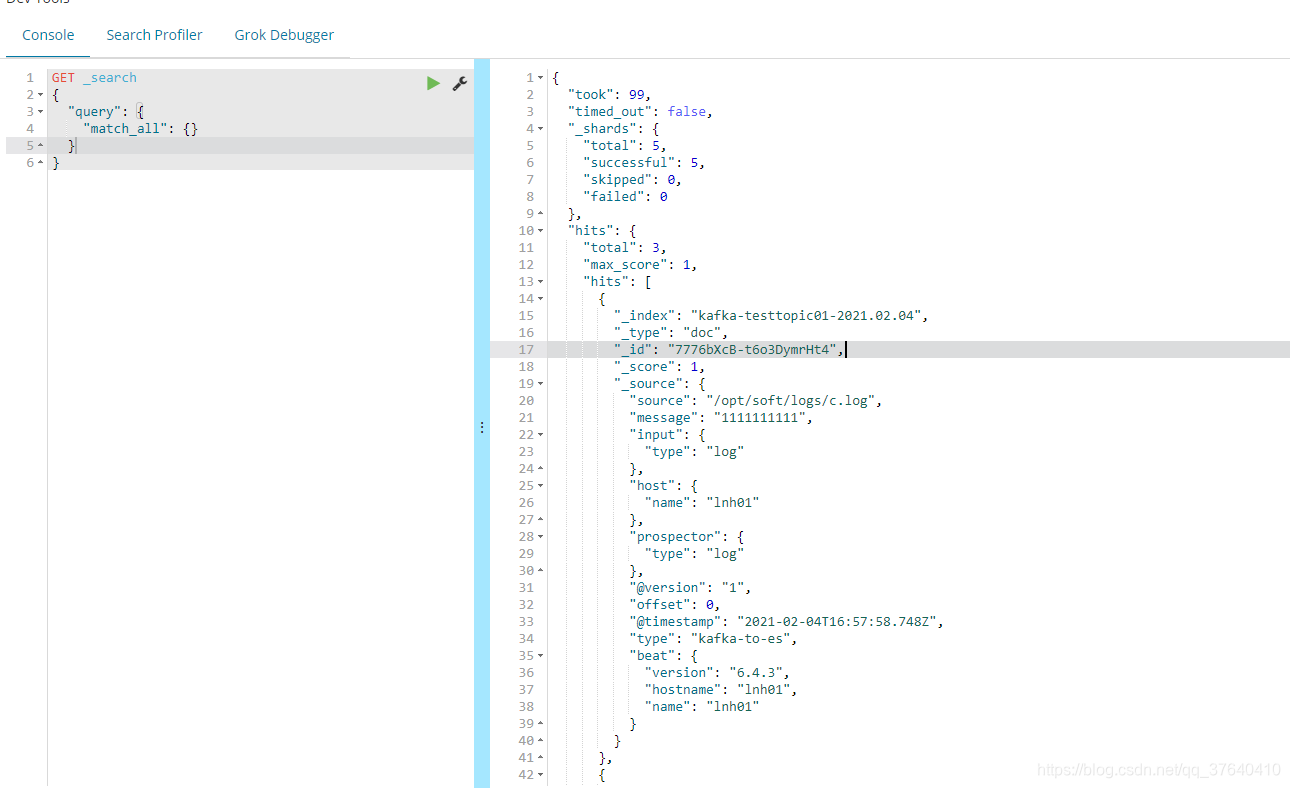
就可以从kibana中查看到es中的信息。
![在这里插入图片描述]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号