企业级电商项目
转载:https://blog.csdn.net/a_blackmoon/article/details/83272764
电商项目介绍
2.电商行业技术特点
①技术新:(NoSql推广首在社区网站和电商项目),发展快,需求推动技术的革新。
②技术范围广:除了java,像淘宝前端还使用了PHP,数据库MySQL或者oracle,nosql,服务器端使用Linux,服务器安全、系统安全
③分布式:以前是在一台机器上做运算,现在是分散到很多机器上,最后汇总起来。(集中式向分布式进行考虑)由需求来推动
④高并发、集群、负载均衡、高可用:由并发问题采用集群进行处理,其中,集群会涉及服务器的主从以及分布问题,使用负载均衡。(权重高低)高可用是对用户而言,用户的服务不中断(系统升级,服务不中断,淘宝每周更新2次)。
⑤海量数据:双11,570亿的背后,订单有多少?浏览次数有多少?商品会有多少?活动相关数据?
⑥业务复杂:不要简单的认为是:商品展示出来后,加入购物车后购买就完成了。后台特别复杂,比如优惠(包邮、满减)
⑦系统安全:系统上线必须通过系统安全部门审核通过。前年CSDN数据泄露。快捷酒店数据泄露(通过身份证就可以查看你的开房记录)。近几年,安全意识逐步在提高。
电商行业的一些概念
1、 B2C:商家对客户,京东、当当、发展为B2C平台,天猫(B2C平台 淘宝商城由马云提出,率先发展为平台),1号店也是(在上海)
2、 B2B:商家对商家,阿里巴巴(不零售,只批发,淘宝很多商家都会去阿里巴巴进货);
3、 C2C:个人对个人,淘宝市场,淘宝,QQ商城;
系统功能
本商城系统是一个综合性的B2C平台,类似京东商城、天猫商城。
会员可以在商城浏览商品、下订单,以及参加各种活动。
商家可以在入住淘淘商城,在该平台上开店出售自己的商品,并且得到淘淘商城提供的可靠的服务。
管理员、运营可以在平台后台管理系统中管理商品、订单、会员等。
客服可以在后台管理系统中处理用户的询问以及投诉。
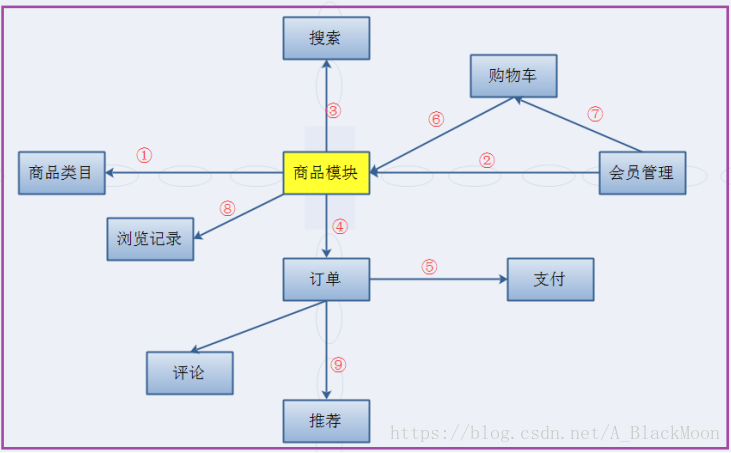
首先我们要有商品,管理员可以在系统中管理商品,用户可以查看商品。
商品多了之后要有类目模块,管理员可以管理类目信息,用户可以根据类目检索商品。
有了商品之后,要有人(会员)去买东西,普通用户注册为会员,会员可以登录到系统管理自己的信息(密码等)
买了之后会生成订单,会员可以购买商品并且可以下单,管理员可以管理订单。
有了订单之后需要支付(在线支付/货到付款)
……
这样,我们就可以把整个电商项目的功能记清楚了!
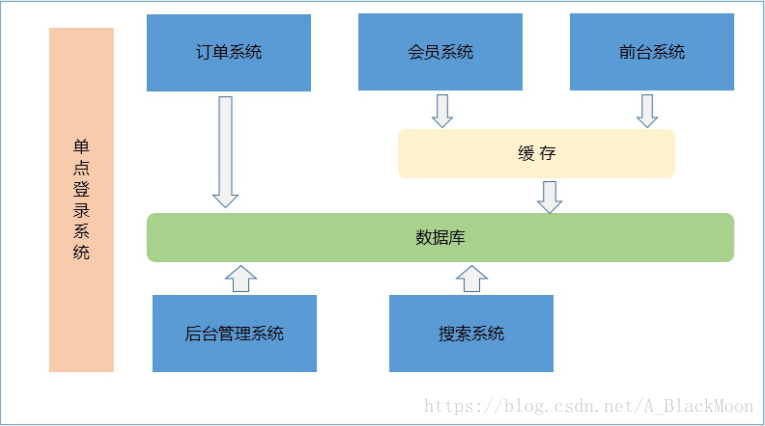
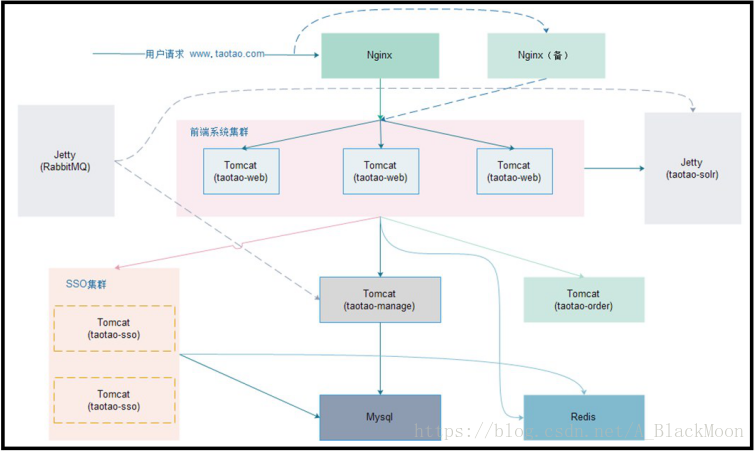
分布式系统架构
左图为分布式系统架构,右图为传统架构!
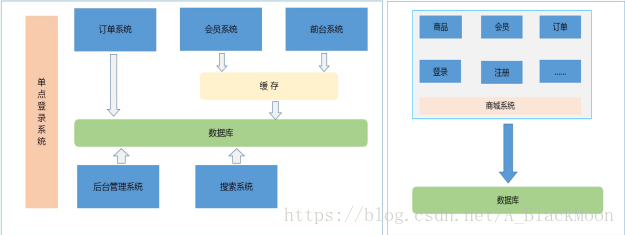
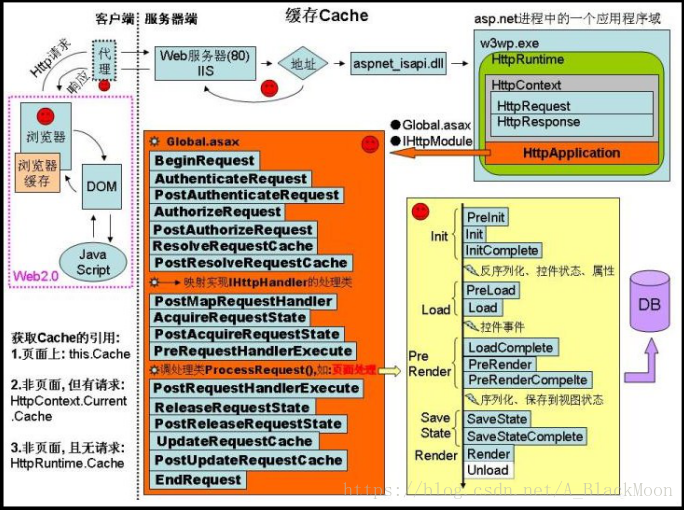
各个系统说明:
后台管理系统:管理商品、订单、类目、商品规格属性、用户管理以及内容发布等功能。
前台系统:用户可以在前台系统中进行注册、登录、浏览商品、首页、下单等操作。
会员系统:用户可以在该系统中查询已下的订单、收藏的商品、我的优惠券、团购等信息。
订单系统:提供下单、查询订单、修改订单状态、定时处理订单。
搜索系统:提供商品的搜索功能。
单点登录系统:为多个系统之间提供用户登录凭证以及查询登录用户的信息。
谈到分布式架构,我们必须对比传统架构才能彰显其优势。
①最为明显的一点,在传统的架构中,如果某个功能需要进行维护,那么我们必须停掉整个服务,这对于公司的运营会造成损失。分布式系统在核心功能模块使用单独服务器,维护部分模块不影响用户的其他操作。
②在海量数据处理方面,传统架构显得比较乏力;分布式系统架构采用服务器集群,使用负载均衡,海量数据处理游刃有余!
③在性能(检索)以及维护方面,分布式系统架构也有较为明显的优势。
6.本系统人员配置情况
l 产品经理:3人,确定需求以及给出产品原型图。
l 项目经理:1人,项目管理。
l 前端团队:3人,根据产品经理给出的原型制作静态页面。
l 后端团队:20人,实现产品功能。
l 测试团队:3人,测试所有的功能。
l 运维团队:2人,项目的发布以及维护。
7.开发流程
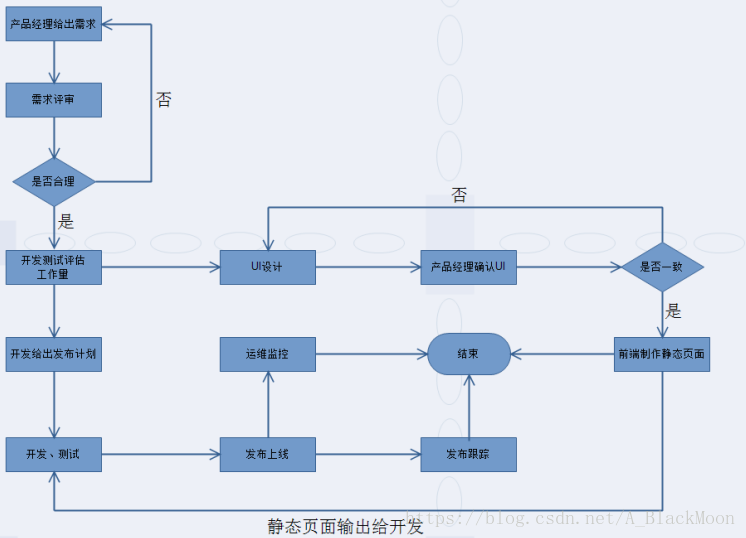
此图不做详细解释(就业指导课已进行详细说明,注意整个流程中容易被问到的问题)
8.后台开发环境
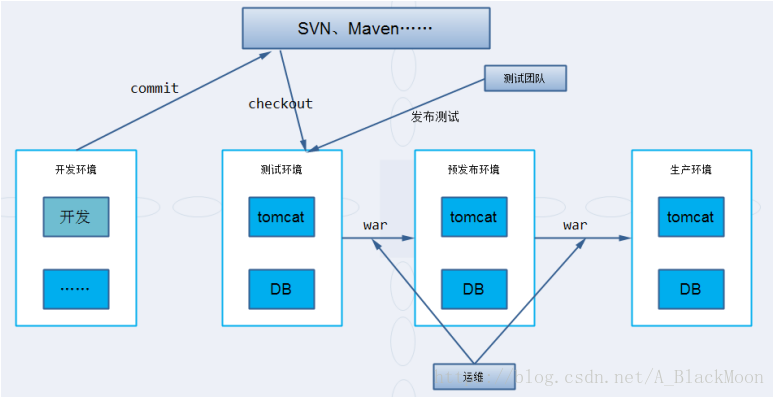
需要注意,在几个环境中,预发布环境和生产环境几乎一样,开发环境和测试环境是独立存在的,每一个阶段的活是由对应的工作人员来负责的。
此外,我们还需要熟悉 SVN主干、分支、标签开发过程流程:
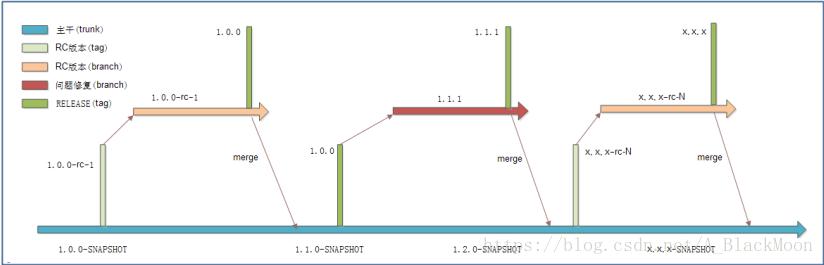
整个开发沿着主线进行,在一个版本定型后,前一个版本出现bug,那么此时会对bug进行修复,投入使用的依旧是之前定型的那个版本,待前一个版本的bug修复好了之后,会定义一个新的版本,主线不会改变,如果改动不大,那么只需修订问题,继续沿用此版本(1.0.x),只有出现较大改动时,才会升级一个新的版本号(1.1.x)。所有动作,交替进行,沿主线向前推进!
9.涉及技术
l Spring、SpringMVC、Mybatis
l JSP、JSTL、jQuery、jQuery plugin、EasyUI、KindEditor(富文本编辑器)、CSS+DIV
l Redis(缓存服务器)
l Lucene、Solr(搜索)
l httpclient(调用系统服务)
l Mysql
l Nginx(web服务器)
l Quartz(定时任务)
l RabbitMQ(消息队列)
技术详解见其它章节,未接触技术点(标背景色技术点)将在本项目后续内容中进行介绍。
10.开发工具和环境
l Eclipse 4.4.1
l Maven 3.2.3
l Tomcat 7.0.47(Maven Tomcat Plugin)
l JDK 1.7
l Mysql 5.6
l Nginx 1.5.1
l Redis 2.8.9
l Win7 操作系统
l SVN(版本管理)
此章节,需要注意所有开发工具的版本号要对应(一致),否则会出现冲突问题,面试大忌!(常识:电商项目火起来的时间不是很久,在开发的时候,很多开发工具和环境不像之前那些传统系统那么老旧,这点一定要引起注意!)
电商项目面试问题
项目介绍
①属于B2C平台----商家对客户
②系统的用途,主要是提供B2C的平台,其中自营商品也有商家入住,类似天猫。
③系统架构,采用分布式的系统架构,其中前台系统和单点登录系统采用了集群的方式部署,在后台管理系统中采用了Maven的多模块化的管理,其中采用了水平切分的方式,将pojo、dao、service、web分层开发,这样做的好处就是可以重用性更高。
系统内部接口调用采用Httpclient,并且使用Httpclient的连接池技术,接口提供端采用RESTful方式的接口定义;
系统之间的通知机制采用MQ的方式,使用RabbitMQ的实现,使用了RabbitMQ的消息订阅模式的消息机制;
系统的接口还对JS的跨域做了支持,采用了jsonp的解决方法,在后台接口中扩展了spirng提供的jackson数据转化器实现;
④部署方面,采用了Nginx+tomcat的模式,其中nginx的作用一方面是做反向代理、负载均衡、另一方面是做图片等静态资源的服务器。
项目介绍应该从这个项目的模式、功能、架构、解决了什么问题、部署以及投入使用情况来说。
2.整个项目的架构如何?
一般情况这个问题要从两个方面去回答,从技术架构和功能架构去谈。
技术架构:本项目使用主流框架spring+springmvc+mybatis进行开发,采用分布式的系统架构,前台系统和单点登录系统采用了集群的方式部署,后台管理系统中采用了Maven的多模块化的管理,其中采用了水平切分的方式,将pojo、dao、service、web分层开发,这样做的好处就是可以重用性更高。系统内部接口调用采用Httpclient,并且使用Httpclient的连接池技术,接口提供端采用RESTful方式的接口定义;系统之间的通知机制采用MQ的方式,使用RabbitMQ的实现,使用了RabbitMQ的消息订阅模式的消息机制;系统的接口还对JS的跨域做了支持,采用了jsonp的解决方法,在后台接口中扩展了spirng提供的jackson数据转化器实现;搜索系统使用了solr实现,在保证系统高性能的前提下,尽可能为公司节约成本,我们使用MySQL数据库进行集群(oracle收费)。在部署方面,采用了Nginx+tomcat的模式,其中nginx的作用一方面是做反向代理、负载均衡、另一方面是做图片等静态资源的服务器。
功能架构:分布式系统架构
各个系统说明:
后台管理系统:管理商品、订单、类目、商品规格属性、用户管理以及内容发布等功能。
前台系统:用户可以在前台系统中进行注册、登录、浏览商品、首页、下单等操作。
会员系统:用户可以在该系统中查询已下的订单、收藏的商品、我的优惠券、团购等信息。
订单系统:提供下单、查询订单、修改订单状态、定时处理订单。
搜索系统:提供商品的搜索功能。
单点登录系统:为多个系统之间提供用户登录凭证以及查询登录用户的信息。
谈到分布式架构,我们必须对比传统架构才能彰显其优势。
①最为明显的一点,在传统的架构中,如果某个功能需要进行维护,那么我们必须停掉整个服务,这对于公司的运营会造成损失。分布式系统在核心功能模块使用单独服务器,维护部分模块不影响用户的其他操作。
②在海量数据处理方面,传统架构显得比较乏力;分布式系统架构采用服务器集群,使用负载均衡,海量数据处理游刃有余!
③在性能(检索)以及维护方面,分布式系统架构也有较为明显的优势。
传统架构:
3.这个项目为用户提供了哪些服务?包括哪些功能?
u 商品管理模块:其中包括品牌管理,属性管理商品录入/上下架管理,商品添加审核,静态页面发布
u 订单模块:其中包括使用activiti工作流订单的查询和订单的流转,定时作废
u 商品前台首页:其中主要负责首页商品列表筛选,首页上动态展示筛选条件,点击每一个筛选条件下面的商品列表要做联动
u 单品页面:采用freemarker来实现页面静态化,展示商品详情信息和商品购买,该页面采用静态化以减轻系统压力,使用了cxf框架发布服务
u 提交订单页面:提交用户的订单信息, 处理并发问题。
u 个人中心,包括用户的登录,个人信息的管理,收货地址的管理,用户所下的订单的管理
u 购物车:把购物车的信息存在cookie里面管理
4.你承担这个项目的哪些核心模块?
在项目中主要负责相关系统的开发,主要有:
1) 后台管理系统,主要实现商品管理、商品规格参数管理、订单管理、会员管理等、CMS(内容管理系统)等,并且提供了跨域支持;
2) 前台系统,主要是面向用户访问,使用Httpclient和后台系统接口做交互,并且该系统在部署上采用集群的方式;
3) 单点登录系统,主要是提供集中用户登录凭证的集中解决方案,提供和用户信息相关的接口,比如说用户注册、查询等接口。
4) 订单系统,主要是提供和订单相关的业务接口,在订单系统了做了严格的数据校验以及高并发写的支持(这里可以说使用队列实现),并且使用了Quartz定时任务实现对订单的定时扫描,比如说关闭超时未付款的订单;
5) 搜索系统,主要是提供商品的搜索,采用开源企业级系统Solr实现,采用了MQ机制保证了商品数据可以及时同步到solr中;
6) 会员系统,主要是维护用户的信息,已购买订单、优惠券、系统消息、修改密码、绑定手机等功能;
7) 缓存,主要是用Redis实现,并且对Redis做了集群来保证Redis服务的高可用。8) 支付系统,主要是负责订单的支付、对账等功能,主要是对接了支付宝的接口;
5.这些模块的实现思路说一下?
①商品管理模块
品牌管理:
主要掌握的核心是品牌的添加
l 图片服务器的搭建,
l 上传图片到图片服务器
l 表单的验证,离开焦点的验证,点击完成时的验证,后台服务器的ajax验证,表单规范
l 防止表单的二次提交
l 编辑时不需要修改品牌名,区别readOnly和disabled
l 删除时的二次确认
注意:
自定义属性必须掌握:html中自定义的属性可以帮助索引元素
图片服务器的搭建
1. 创建一个maven的web工程,在工程中创建一个存放资源的目录
2. 把tomcat的web.xml中DefaultServlet的只读属性改成false
3. 编写上传到图片服务器的代码
由于应用服务器与图片服务器出于不同的两台机器之中,所以可以提高系统的性能,能起到负载均衡的作用。上传图片时使用Jersey客户端API调用REST风格的Web服务,Jersey1是一个开源的、可以用于生产环境的JAX-RS(RESTful Web Services 的Java API 规范,JSR-311)实现。通Jersey 可以很方便的使用Java来创建一个RESTful Web Services。
byte[] fileByte = commFile.getBytes();
//创建客服端,基于webservice
Client client = Client.create();
//指定资源路径
WebResource webResource = client.resource(Constants.picPath+fileName);
//使用put的请求方式把资源文件放到资源服务器上
webResource.put(String.class, fileByte);
前台使用ajax提交表单,需要使用jquery的jquery.form.js插件
|
$("#form").ajaxSubmit({ 表单验证 1. 提交时做验证 <p> <label><samp>*</samp>品牌名称:</label> <input type="text" id="brandName" name="brandName" class="text state" reg2="^[a-zA-Z0-9\u4e00-\u9fa5]{1,20}$" tip="必须是中英文或数字字符,长度1-20"/> <span></span> </p> 2. 在表单提交时做验证使用$(“form”).submit(function(){ return false });,必填字段和非必填的字段需要区别对待 $("#form111").submit(function(){ var isSubmit = true; $(this).find("[reg2]").each(function(){ var regStr = $(this).attr("reg2"); //剪掉值中的两侧的字符串 var value = $.trim($(this).val()); var tip = $(this).attr("tip"); //创建正则表达式的对象 var reg = new RegExp(regStr); if(!reg.test(value)){ $(this).next("span").html(tip); isSubmit = false; //跳出循环,在jquery的each语句之中跳出循环使用return false; 如果在原生js里面可使用break;, return;:代表终止执行程序 return false; } }); $(this).find("[reg1]").each(function(){ var regStr = $(this).attr("reg1"); var value = $.trim($(this).val()); var tip = $(this).attr("tip"); var reg = new RegExp(regStr); if(value != null && value != ""){ if(!reg.test(value)){ $(this).next("span").html(tip); isSubmit = false; return false; } } }); return isSubmit; });
3. 使用离焦事件做友好的提示 $("input[reg2]").blur(function(){ var regStr = $(this).attr("reg2"); var value = $.trim($(this).val()); var tip = $(this).attr("tip"); var reg = new RegExp(regStr); if(!reg.test(value)){ $(this).next("span").html(tip); }else{ $(this).next("span").html(""); } }); 4. 表单的二次提交处理 l 锁屏 ②商品的查询 商品查询需要组合条件加分页查询 <select id="queryItemByCondtion" resultMap="BaseResultMap" parameterType="map"> select * from (select a.*, rownum rm from ( select * from eb_item ei <where> <if test="brandId != null"> ei.brand_id = #{brandId} </if> <if test="auditStatus != null"> and ei.audit_status = #{auditStatus} </if> <if test="showStatus != null"> and ei.show_status = #{showStatus} </if> <if test="itemName != null"> and ei.item_name like '%${itemName}%' </if> </where> order by ei.item_id desc) a <![CDATA[ where rownum < #{endNum}) b where b.rm > #{startNum} ]]> </select> --查询大于当前页首行号,主要解决oracle的rownum不支持大于号的问题 select * from ( --查询小于当前最大行号的数据 select rownum rm,a.* from ( --第一个select查询所有的业务数据 select * from eb_item ) a where rownum < 21) b where b.rm > 10
l 分页查询 select * from (select a.*, rownum rm from ( ... 内部sql ... ) a where rownum < #{endNum}) b where b.rm > #{startNum} 2. 使用内部sql查询结果集的总条数 3. 使用分页工具类,创建page对象更换每次的数据总条数和当前页数和每页的条数,查询出结果集后把结果集注入到page对象之中 public class Page { int totalCount = 0; int pageSize = 10; int currentPageNo = 1; int startNum = 0; int endNum = 11; public Page(int totalCount, int pageSize, int currentPageNo) { super(); this.totalCount = totalCount; this.pageSize = pageSize; this.currentPageNo = currentPageNo; } public int getStartNum(){ return (currentPageNo - 1) * pageSize; }
public int getEndNum(){ return currentPageNo * pageSize + 1; } public int getTotalPage(){ int totalPage = totalCount/pageSize; if(totalPage == 0 || totalCount%pageSize != 0){ totalPage ++; } return totalPage; } public int getNextPage(){ if(currentPageNo >= getTotalPage()){ return currentPageNo; }else{ return currentPageNo + 1; } } public int getPrePage(){ if(currentPageNo <= 1){ return currentPageNo; }else{ return currentPageNo - 1; } } List<?> list;
public List<?> getList() { return list; }
public void setList(List<?> list) { this.list = list; }
public int getTotalCount() { return totalCount; }
public void setTotalCount(int totalCount) { this.totalCount = totalCount; }
public int getPageSize() { return pageSize; }
public void setPageSize(int pageSize) { this.pageSize = pageSize; }
public int getCurrentPageNo() { return currentPageNo; }
public void setCurrentPageNo(int currentPageNo) { this.currentPageNo = currentPageNo; }
public void setStartNum(int startNum) { this.startNum = startNum; }
public void setEndNum(int endNum) { this.endNum = endNum; } } 4. 制作前端样式 var currentPageNo = parseInt($("#currentPageNo").val()); var totalCount = parseInt($("#totalCount").val()); var totalPage = parseInt($("#totalPage").val()); $("#pagePiece").html(totalCount); $("#pageTotal").html(currentPageNo+"/"+totalPage); if(currentPageNo <= 1){ $("#previous").hide(); }else{ $("#previous").show(); } if(currentPageNo >= totalPage){ $("#next").hide(); }else{ $("#next").show(); } $("#next").click(function(){ $("#pageNo").val(parseInt(currentPageNo)+1); $("#form1").submit(); }); $("#previous").click(function(){ $("#pageNo").val(parseInt(currentPageNo)-1); $("#form1").submit(); });
Oracle 分页sql的描述: ③商品发布 Console和portal是分开部署在两台服务器上,发布需要在console端去控制,但是生成的静态化的文件要发布到portal的工程之中,所以发布的服务要在portal上,但是要在console中来调用,异构之间的调用要使用webservice。 <servlet> <servlet-name>cxfServlet</servlet-name> <servlet-class>org.apache.cxf.transport.servlet.CXFServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>cxfServlet</servlet-name> <url-pattern>/services/*</url-pattern> </servlet-mapping> 3. 创建服务的接口和接口的实现类,注意接口上加上@WebService注解 4. 创建cxf的核心配置文件cxf-servlet.xml,配置带有接口的webservice服务使用<jaxws:server>标签 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:jaxws="http://cxf.apache.org/jaxws" xmlns:jaxrs="http://cxf.apache.org/jaxrs" xmlns:cxf="http://cxf.apache.org/core" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://cxf.apache.org/jaxrs http://cxf.apache.org/schemas/jaxrs.xsd http://cxf.apache.org/jaxws http://cxf.apache.org/schemas/jaxws.xsd http://cxf.apache.org/core http://cxf.apache.org/schemas/core.xsd"> <!-- 引入CXF Bean定义如下,早期的版本中使用 --> <import resource="classpath:META-INF/cxf/cxf.xml" /> <import resource="classpath:META-INF/cxf/cxf-extension-soap.xml" /> <import resource="classpath:META-INF/cxf/cxf-servlet.xml" />
<jaxws:server id="publish" address="/publish" serviceClass="cn.itcast.ecps.ws.service.EbItemWSService"> <jaxws:serviceBean> <bean class="cn.itcast.ecps.ws.service.impl.EbItemWSServiceImpl"></bean> </jaxws:serviceBean> <!-- 输入输出的拦截器 -->
<jaxws:inInterceptors> <bean class="org.apache.cxf.interceptor.LoggingInInterceptor"></bean> </jaxws:inInterceptors>
<jaxws:outInterceptors> <bean class="org.apache.cxf.interceptor.LoggingOutInterceptor"></bean> </jaxws:outInterceptors> </jaxws:server> </beans> 5. 修改cxf-servlet.xml的位置,在spring的listener中加载 <listener> <listener-class> org.springframework.web.context.ContextLoaderListener </listener-class> </listener> <context-param> <param-name>contextConfigLocation</param-name> <param-value> classpath*:beans.xml,classpath*:cxf-servlet.xml </param-value> </context-param> 6. 启动服务器发布webservice的服务,使用wsdl2java生成客户端的代码 Wsdl2java –d . –p cn.itcast.ecps.ws.stub http://.........wsdl? ④订单管理模块 1) 流程设计
2) 订单整合activiti工作流 1.activiti流程和spring整合 <beans xmlns="http://www.springframework.org/schema/beans" xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-2.5.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-3.0.xsd">
<bean id="processEngineConfiguration" class="org.activiti.spring.SpringProcessEngineConfiguration"> <!-- 数据源 --> <property name="dataSource" ref="dataSource" /> <!-- 配置事务管理器,统一事务 --> <property name="transactionManager" ref="txManager" /> <!-- 设置建表策略 --> <property name="databaseSchemaUpdate" value="true" /> </bean>
<bean id="processEngine" class="org.activiti.spring.ProcessEngineFactoryBean"> <property name="processEngineConfiguration" ref="processEngineConfiguration" /> </bean> <bean id="repositoryService" factory-bean="processEngine" factory-method="getRepositoryService" /> <bean id="runtimeService" factory-bean="processEngine" factory-method="getRuntimeService" /> <bean id="taskService" factory-bean="processEngine" factory-method="getTaskService" /> <bean id="historyService" factory-bean="processEngine" factory-method="getHistoryService" /> </beans>
1. 画流程图 package cn.itcast.service.impl; import java.io.File; import org.activiti.engine.RepositoryService; import org.activiti.engine.repository.DeploymentBuilder; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import cn.itcast.service.IWorkFlowService;
//@Service public class WorkflowServiceImpl implements IWorkFlowService {
@Autowired RepositoryService repositoryService;
/*public RepositoryService getRepositoryService() { return repositoryService; }
public void setRepositoryService(RepositoryService repositoryService) { this.repositoryService = repositoryService; }*/
public void deployFlow() { //创建发布流程配置对象 DeploymentBuilder builder = repositoryService.createDeployment(); //指定流程资源路径 builder.addClasspathResource("activit-orderflow.bpmn").addClasspathResource("activit-orderflow.png"); builder.deploy(); } } 1. 部署流程 2. 查询业务任务 6.项目中哪些功能模块涉及了大数据量访问?你是如何解决的?系统前台是互联网上的用户访问的,会有大量用户来访问。 Update eb_sku t sett.stock = t.stock – 1 where t.sku_id = #{skuId} and t.stock > 0 Update eb_sku t set t.sale = t.sale +1 where t.sku_id = #{skuId} 首先我们容易想到和并发相关的几个方案 : 锁同步 同步更多指的是应用程序的层面,多个线程进来,只能一个一个的访问,java中指的是syncrinized关键字。锁也有2个层面,一个是java中谈到的对象锁,用于线程同步;另外一个层面是数据库的锁;如果是分布式的系统,显然只能利用数据库端的锁来实现。 假定我们采用了同步机制或者数据库物理锁机制,如何保证1w个人还能同时看到有商品,显然会牺牲性能,在高并发网站中是不可取的。使用hibernate后我们提出了另外一个概念:乐观锁(一定要用)、悲观锁(即传统的物理锁);采用乐观锁即可解决此问题。乐观锁意思是不锁定表的情况下,利用业务的控制来解决并发问题,这样即保证数据的并发可读性又保证保存数据的排他性,保证性能的同时解决了并发带来的脏数据问题。 前提:在现有表当中增加一个冗余字段,version版本号, long类型 原理: 1)只有当前版本号》=数据库表版本号,才能提交 2)提交成功后,版本号version ++ 实现很简单:在ormapping增加一属性-lock="version"即可,以下是样例片段optimistic <hibernate-mapping> <class name="com.insigma.stock.ABC" optimistic-lock="version" table="T_Stock" schema="STOCK"> </hibernate-mapping> 更新的时候给版本号字段加上 1,然后 UPDATE 会返回一个更新结果的行数,通过这个行数去判断。
UPDATE 必须这样写: Sale = 100 UPDATE EB_SKU u SET u.SALES = #SALES#, u.version = u.version + 1 WHERE u.SKU_ID = #SKUID# AND u.version = #version# Update user t set t.address = #{address} where t.user_id = #{userId} 如果更新执行返回的数量是 0 表示产生并发修改了,需要重新获得最新的数据后再进行更新操作。 Hibernate、JPA 等 ORM 框架或者实现,是使用版本号,再判断 UPDATE 后返回的数值,如果这个值小于 1 时则抛出乐观锁并发修改异常。
解决大量用户访问量问题方案是集群部署,防止宕机,负载均衡 1.我们采用4台portal服务器来集群,使用2台nginx代理服务器, 1)反向代理,把4台portal的服务(host)集中起来,访问动态链接代理地址(代理IP:192.168.1.100)时候会把请求转发到4太portal上,如果访问静态页面直接访问nginx上的资源文件就可以了,静态html中有ajax的请求由nginx的反向代理功能来转发。 2)部署静态资源(html和图片) 2.Rsync用作资源同步 当console上传的图片,由于rsync的部署,会指定一个具体的同步目录(上传图片的目录),一旦发现目录中有文件就立刻同步到nginx上 3.Redis负责管理session和缓存搜索的数据 管理session的原因:用于多台服务器之间需要有相同的session,同享策略耗费资源,所以采用redis来存储session。缓存频繁被搜索的数据。 7.在做这个项目的时候你碰到了哪些问题?你是怎么解决的?①.开发webservice接口出现客户端和服务端不同步,导致接口无法测试,产生的原因沟通不畅。 ②.订单提交时由于本地bug或者意外故障导致用户钱支付了但是订单不成功,采用对账方式来解决。 ③.上线的时候一定要把支付的假接口换成真接口。 ④.项目中用到了曾经没有用过的技术,解决方式:用自己的私人时间主动学习 ⑤.在开发过程中与测试人员产生一些问题,本地环境ok但是测试环境有问题,环境的问题产生的,浏览器环境差异,服务器之间的差异 ⑥.系统运行环境问题,有些问题是在开发环境下OK,但是到了测试环境就问题,比如说系统文件路径问题、导出报表中的中文问题(报表采用highcharts),需要在系统jdk中添加相应的中文字体才能解决; 8.你做完这个项目后有什么收获?首先,在数据库方面,我现在是真正地体会到数据库的设计真的是一个程序或软件设计的重要和根基。因为数据库怎么设计,直接影响到一个程序或软件的功能的实现方法、性能和维护。由于我做的模块是要对数据库的数据进行计算和操作的,所以我对数据库的设计对程序的影响是深有体会,就是因为我们的数据库设计得不好,搞得我在对数据库中的数据进行获取和计算利润、总金时,非常困难,而且运行效率低,时间和空间的复杂也高,而且维护起来很困难,过了不久,即使自己有注释,但是也要认真地看自己的代码才能明白自己当初的想法和做法。加上师兄的解说,让我对数据库的重要的认识更深一层,数据库的设计真的是重中之重。
其次,就是分工的问题。虽然这次的项目我们没有在四人选出一个组长,但是,由于我跟其他人都比较熟,也有他们的号码,然后我就像一个小组长一样,也是我对他们进行了分工。俗话也说,分工合作,分好了工,才能合作。但是这次项目,我们的分工却非常糟糕,我们在分工之前分好了模块,每个模块实现什么功能,每个人负责哪些模块。本以为我们的分工是明确的,后来才发现,我们的分工是那么的一踏糊涂,一些功能上紧密相连的模块分给了两个人来完成,使两个人都感到迷惘,不知道自己要做什么,因为两个人做的东西差不多。我做的,他也在做,那我是否要继续做下去?总是有这样的疑问。从而导致了重复工作,浪费时间和精力,并打击了队员的激情,因为自己辛辛苦苦写的代码,最后可能没有派上用场。我也知道,没有一点经验的我犯这样的错是在所难免,我也不过多地怪责自己,吸取这次的教训就好。分工也是一门学问。
再者,就是命名规范的问题。可能我们以前都是自己一个人在写代码,写的代码都是给自己看的,所以我们都没有注意到这个问题。就像师兄说的那样,我们的代码看上去很上难看很不舒服,也不知道我们的变量是什么类型的,也不知道是要来做什么的。但是我觉得我们这一组人的代码都写得比较好看,每个人的代码都有注释和分隔,就是没有一个统一的规范,每个人都人自己的一个命名规则和习惯,也不能见名知义。还有就是没有定义好一些公共的部分,使每个人都有一个自己的“公共部分”,从而在拼起来时,第一件事,就是改名字。而这些都应该是在项目一开始,还没开始写代码时应该做的。
然后,我自己在计算时,竟然太大意算错了利润,这不能只一句我不小心就敷衍过去,也是我的责任,而且这也是我们的项目的核心部分,以后在做完一个模块后,一定要测试多次,不能过于随便地用一个数据测试一下,能成功就算了,要用可能出现的所有情况去测试程序,让所有的代码都有运行过一次,确认无误。
最后,也是我比较喜欢的东西,就是大家一起为了一个问题去讨论和去交流。因为我觉得,无论是谁,他能想的东西都是有限的,别人总会想到一些自己想不到的地方。跟他人讨论和交流能知道别人的想法、了解别人是怎样想一个问题的,对于同样的问题自己又是怎样想的,是别人的想法好,还是自己的想法好,好在什么地方。因为我发现问题的能力比较欠缺,所以我也总是喜欢别人问我问题,也喜欢跟别人去讨论一个问题,因为他们帮我发现了我自己没有发现的问题。在这次项目中,我跟植荣的讨论就最多了,很多时候都是不可开交的那种,不过我觉得他总是能够想到很多我想不到的东西,他想的东西也比我深入很多,虽然很多时候我们好像闹得很僵,但是我们还是很要好的! 嘻嘻!而且在以后的学习和做项目的过程中,我们遇到的问题可能会多很多,复杂很多,我们一个人也不能解决,或者是没有想法,但是懂得与他人讨论与交流就不怕这个问题,总有人的想法会给我们带来一片新天地。相信我能做得更好。
还有就是做项目时要抓准客户的要求,不要自以为是,自己觉得这样好,那样好就把客户的需求改变,项目就是项目,就要根据客户的要求来完成。 9.你这个项目中使用什么构建的?多模块开发是如何划分的呢?为什么要这么做?我们这个项目使用Maven进行构建,并使用了水平划分,这样划分层次清晰,代码重用性高,易于独立维护。 ①垂直划分
②水平划分
优缺点: 垂直:功能模块明确,层次不够清晰,代码重用性差。 水平:层次清晰,代码重用性高,独立维护。
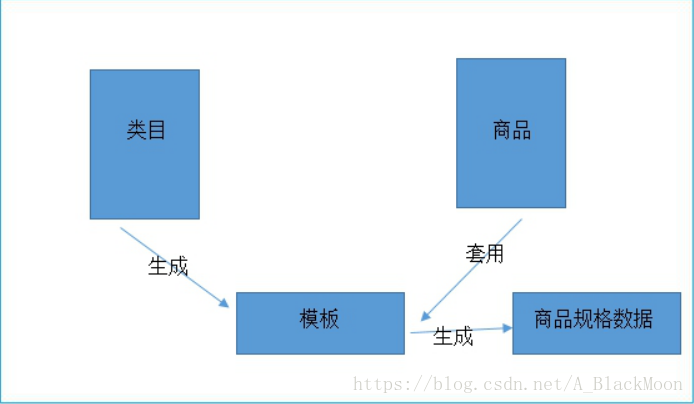
淘淘商城后台管理系统采取水平划分。 10.你觉得在文件上传功能上面需要注意什么?对上传的文件做校验! 11.在你这个项目中,是如何设计商品规格的?实现思路很重要! 12.在这个项目中你是如何实现跨系统调用的?
有两种调用方式: a) 效率 b) 带宽 document.domain="taotao.com" 2、 后台转发请求,走后台,通过httpclient来调。 a) 可以加逻辑(加缓存只能这条路走) b) 安全,接口不在公网公开 重点学习httpclient中的示例 我们这个项目2种方式都使用到了。 13.你这个项目中CMS系统是如何设计的,简单的说一下其设计思想?隐藏在内容管理系统(CMS)之后的基本思想是分离内容的管理和设计。页面设计存储在模板里,而内容存储在数据库或独立的文件中。 当一个用户请求页面时,各部分联合生成一个标准的HTML(标准通用标记语言下的一个应用)页面。 内容管理系统被分离成以下几个层面:各个层面优先考虑的需求不同 1,后台业务子系统管理(管理优先:内容管理):新闻录入系统,BBS论坛子系统,全文检索子系统等,针对不同系统的方便管理者的内容录入:所见即所得的编辑管理界面等,清晰的业务逻辑:各种子系统的权限控制机制等; 2,Portal系统(表现优先:模板管理):大部分最终的输出页面:网站首页,子频道/专题页,新闻详情页一般就是各种后台子系统模块的各种组合,这种发布组合逻辑是非常丰富的,Portal系统就是负责以上这些后台子系统的组合表现管理; 3,前台发布(效率优先:发布管理):面向最终用户的缓存发布,和搜索引擎spider的URL设计等…… 内容管理和表现的分离:很多成套的CMS系统没有把后台各种子系统和Portal分离开设计,以至于在Portal层的模板表现管理和新闻子系统的内容管理逻辑混合在一起,甚至和BBS等子系统的管理都耦合的非常高,整个系统会显得非常庞杂。而且这样的系统各个子系统捆绑的比较死,如果后台的模块很难改变。但是如果把后台各种子系统内容管理逻辑和前台的表现/发布分离后,Portal和后台各个子系统之间只是数据传递的关系:Portal只决定后台各个子系统数据的取舍和表现,而后台的各个子系统也都非常容易插拔。 内容管理和数据分发的分离:需要要Portal系统设计的时候注意可缓存性(Cache Friendly)性设计:CMS后台管理和发布机制,本身不要过多考虑"效率"问题,只要最终页面输出设计的比较Cacheable,效率问题可通过更前端专门的缓存服务器解决。 此外,就是除了面向最终浏览器用户外,还要注意面向搜索引擎友好(Search engine Friendly)的URL设计:通过 URL REWRITE转向或基于PATH_INFO的参数解析使得动态网页在链接(URI)形式上更像静态的目录结构,方便网站内容被搜索引擎收录; 14.在这个项目中,你们主要使用什么样的数据格式来进行数据的传输的?你对JSON了解么?能说说JSON对象如何转换成Java对象的?
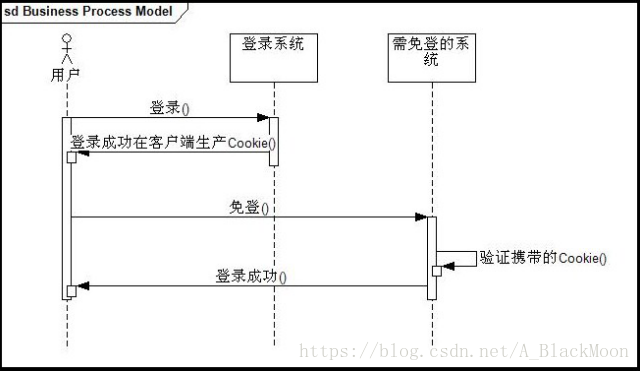
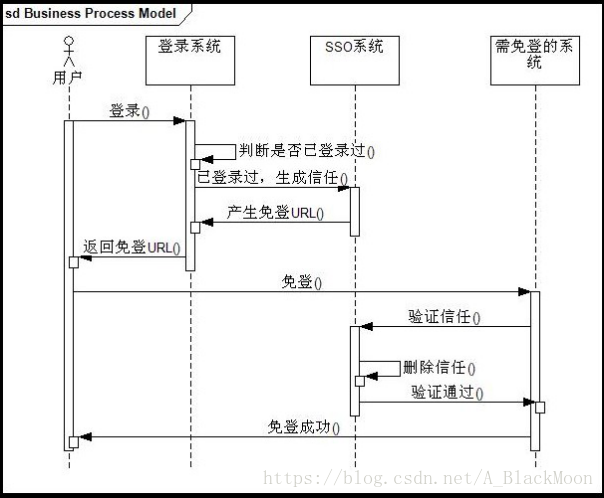
15.单点系统的设计思想你了解吗?他在系统架构中的作用是什么?位置如何?单点登录SSO(Single Sign On)说得简单点就是在一个多系统共存的环境下,用户在一处登录后,就不用在其他系统中登录,也就是用户的一次登录能得到其他所有系统的信任。单点登录在大型网站里使用得非常频繁,例如像阿里巴巴这样的网站,在网站的背后是成百上千的子系统,用户一次操作或交易可能涉及到几十个子系统的协作,如果每个子系统都需要用户认证,不仅用户会疯掉,各子系统也会为这种重复认证授权的逻辑搞疯掉。实现单点登录说到底就是要解决如何产生和存储那个信任,再就是其他系统如何验证这个信任的有效性,因此要点也就以下几个: 存储信任 验证信任 只要解决了以上的问题,达到了开头讲得效果就可以说是SSO。最简单实现SSO的方法就是用Cookie,实现流程如下所示: 不难发现以上的方案是把信任存储在客户端的Cookie里,这种方法虽然实现方便但立马会让人质疑两个问题: Cookie不安全 不能跨域免登 对于第一个问题一般都是通过加密Cookie来处理,第二个问题是硬伤,其实这种方案的思路的就是要把这个信任关系存储在客户端,要实现这个也不一定只能用Cookie,用flash也能解决,flash的Shared Object API就提供了存储能力。 一般说来,大型系统会采取在服务端存储信任关系的做法,实现流程如下所示: 以上方案就是要把信任关系存储在单独的SSO系统(暂且这么称呼它)里,说起来只是简单地从客户端移到了服务端,但其中几个问题需要重点解决: 如何高效存储大量临时性的信任数据 如何防止信息传递过程被篡改 如何让SSO系统信任登录系统和免登系统 对于第一个问题,一般可以采用类似与memcached的分布式缓存的方案,既能提供可扩展数据量的机制,也能提供高效访问。对于第二个问题,一般采取数字签名的方法,要么通过数字证书签名,要么通过像md5的方式,这就需要SSO系统返回免登URL的时候对需验证的参数进行md5加密,并带上token一起返回,最后需免登的系统进行验证信任关系的时候,需把这个token传给SSO系统,SSO系统通过对token的验证就可以辨别信息是否被改过。对于最后一个问题,可以通过白名单来处理,说简单点只有在白名单上的系统才能请求生产信任关系,同理只有在白名单上的系统才能被免登录。 16.你们这个项目中订单ID是怎么生成的?我们公司最近打算做一个电商项目,如果让你设计这块,你会考虑哪些问题?生成订单ID的目的是为了使订单不重复,本系统订单ID生成规则: 用户ID+当前系统的时间戳 String orderId = order.getUserId() + "" + System.currentTimeMillis(); 设计的时候我会考虑: 订单ID不能重复 订单ID尽可能的短(占用存储空间少,实际使用方便,客服相关) 订单ID要求是全数字(客服) 17.各个服务器的时间不统一怎么办?在各个服务器上做时间的统一;(运维) 18.在问题17的基础上,可能存在毫秒级的偏差情况,怎么办?修改订单生成规则: 19.你们线上部署时什么样的,能画一下吗?20.多台tomcat之间的session是怎么同步的?不用session,我们使用单点登陆,使用redis,存在redis,生成,A同步到B,B同步到C。 21.如何解决并发问题的?集群,负载均衡,nginx(主备,一般主在工作,备闲置;资源浪费),lvs(在2个Nginx前做一个拦截,接收后进行分工)。有问题,如果nginx挂掉,整个系统就挂了。可以主备解决,可以前面搭一个lvs。这块不是你做的,但是你知道怎么解决(非常复杂,但是必须了解。针对具体的情况去具体对待,CPU,内存,不要一刀切。) 22.你们生产环境的服务器有多少台?面试前要数好,一般是十几到二十台。(用在哪里?这是重点) Nginx至少2台 Tomcat至少3台以上 数据库至少2台 Redis至少一台 可参考17问图 23.数据备份是怎么做的?有没有做读写分离?主从(一主多从,主要是备份主),每天备份,备份的文件不要放到数据库服务器上,可以FTP。要检查有效否。读写分离自己查一下,分库分表做过。 24.你们服务器不止一台吧,那么你们的session是怎么同步的?此问题与18相同,如果购物车使用session做的话,此问题极易被问到。 Session放到redis里面,使用单点登录系统。购物车设计思路:未登录(先写到cookie中,登录后写到数据库表中);已登录(直接写到数据库,而不会写到cookie)实际项目是不使用session的,使用redis集中处理处理数据,取代session的作用,应用在单点登录、购物车等。 25.你们使用什么做支付的?如果使用易宝做支付,请求超时了怎么处理?①重试,一般三次,每次重试都要停顿一会,比如,以第一次停顿1秒,第二次停顿2秒,第三次停顿3秒; ③写个定时任务,定时处理异常状态的订单。 26.你刚才不是说付款成功后易宝会有数据返回吗?如果付款后易宝没有返回,或者返回超时了,但是钱又已经扣了,你怎么办?①我们请求了易宝,但是没有接受到响应,我们就认为该订单没有支付成功,并且将订单标识为异常状态; ③做一个对账的任务,实时处理异常状态的订单。 27.你们怎么做退款功能的,要多长时间才能把钱退回给用户?用户申请退款后,经过客服审核通过会将退款请求提交到易宝,具体到账时间要看易宝的处理。 28.你前台portal采用4台服务器集群部署 那你数据库有几台服务器?如果前台高并发访问性能提上去了,那数据库会不会造成一个瓶颈,这一块你是怎么处理的?
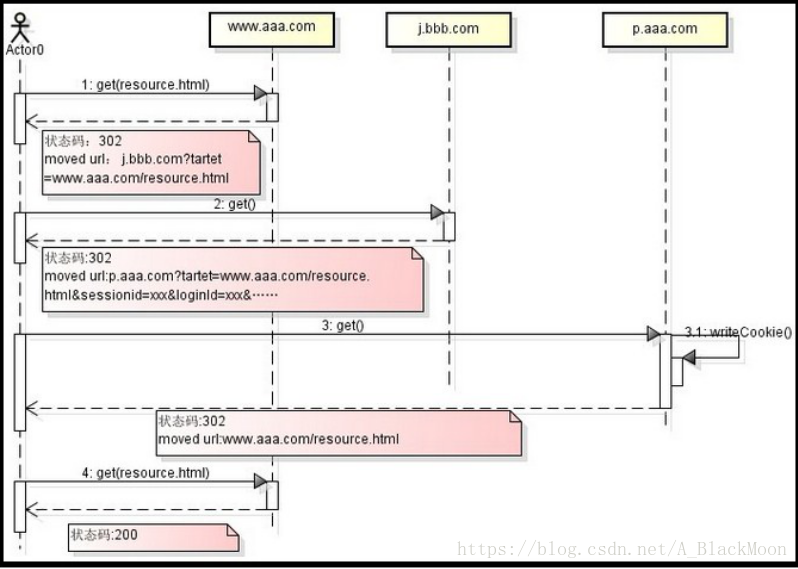
29.你购物车存cookie里边可以实现不登录就可以使用购物车,那么我现在没有登录把商品存购物车了,然后登录了, 然后我换台电脑并且登录了还能不能看见我购物车的信息?如果看不到怎么做到cookie同步,就是在另外一台电脑上可以看到购物车信息更换电脑,必须登录才能看到之前购物车的商品。 跨域cookie同步方案: 场景:有时一个公司可能有多个不同域名的网站,比如sina.com和weibo.cn,比如taobao.com和tmall.com。 这些网站背后很多是同一套会员体系。由于http协议规定cookie是跟着域名走的,这时就需要在不同的域名下同步登陆状态,避免出现用户体验上出现需要二次登陆验证的情况。 假设下面这样一个场景: 用户在 bbb.com上已经登陆,现在要去aaa.com上玩,在aaa.com域名下暂未登录。需要访问的aaa.com/resource.html资源需 要登录才能访问。两个网站是同一套会员体系,同一个公司的。这是要让用户体验上做到用户在aaa.com上玩也能识别出登录状态。 以上面场景为例,下面画了个实现跨域同步简单流程图: 解释如下: 第一步 :用户向aaa.com发起get请求,获取resource.html资源,aaa.com发现用户未登录,返回302状态和外部重定向url: Java代码 收藏代码 j.bbb.com?target=www.aaa.com/resource.html 注意j.bbb.com子域名上部署的应用可以认为是专门用了跨域同步。
第二步 :用户根据重定向url,访问j.bbb.com?target=www.aaa.com/resource.html,由于在bbb.com上已经登 录,所以bbb.com上能拿到从client端传递过来cookie信息。子域j.bbb.com上的应用负责将cookie读取出来,并作为参数再次 重定向到 Java代码 收藏代码 p.aaa.com?tartet=www.aaa.com/resource.html&sessionid=xxx&loginId=xxx&…… 第三步 :用户根据第二步重定向url,访问p.aaa.com。p.aaa.com子域名上的应用专门负责根据请求参数里的参数对,往aaa.com域写入cookie,并重定向到用户第一步请求的url。 第四步 :经过前三步,已经完成了再aaa.com域名下同步bbb.com的登录状态,用户再次请求aaa.com/resource.html,这是就能成功访问了。 30.点一个链接访问到一个页面,这个页面上既有静态数据,又有动态数据(需要查数据库的),打开这个页面的时候就是很慢但是也能打开。怎么解决这个问题,怎么优化?如果要静态页面的话 那就得用freemarker或者通过ajax异步,通过js操作异步刷新表单,通过js对返回结果组装成html。 缓存、动态页面静态化: 所谓缓存, 是指将那些经常重复的操作结果暂时存放起来, 在以后的执行过程中, 只要使用前面的暂存结果即可. 那么在我们开发Web网站的过程中, 到底有多少工作可以采用用缓存呢? 或者说, 我们可以在哪些地方使用缓存呢? 见下图: 下图是客户端浏览器和Web服务器之间的一次完整的通信过程, 红色圆圈标示了可以采用缓存的地方. 首先, 最好的情况是客户端不发送任何请求直接就能获得数据, 这种情况下, 用于缓存的数据保存在客户端浏览器的缓存中. 其次, 在具有代理服务器的网络环境中, 代理服务器可以针对那些经常访问的网页制作缓存, 当局域网中第一台主机请求了某个网页并返回结果后, 局域网中的第二台主机再请求同一个网页, 这时代理服务器会直接返回上一次缓存的结果, 并不会向网络中的IIS服务器发送请求, 例如: 现在的连接电信和网通线路的加速器等. 但是代理服务器通常有自己专门的管理软件和管理系统, 作为网站开发人员对代理服务器的控制能力有限. 再次, 前面也说过, 当用户将请求地址发送到IIS服务器时, IIS服务器会根据请求地址选择不同的行为, 如: 对于*.aspx页面会走应用程序管道, 而对*.html、*.jpg等资源会直接返回资源, 那么我们可以把那些频繁访问的页面做成*.html文件, 这样用户请求*.html, 将不用再走应用程序管道, 因此会提升效率. 例如: 网站首页、或某些突发新闻或突发事件等, 可以考虑做成静态网页. 就拿”天气预报的发布页面”打比方: 天气预报的发布页面的访问用户非常多, 我们可以考虑将发布页做成静态的*.html网页, 之后在整个网站程序启动时, 在Gboabl.asax的Application_Start事件处理器中, 创建子线程以实现每3个小时重新获取数据生成新的天气发布页面内容. 之后的asp.net的处理流程, 作为程序员我们是无法干涉的. 直到启动HttpApplication管道后, 我们才可以通过Global.asax或IHttpModule来控制请求处理过程, 在应用程序管道中适合做整页或用户控件的缓存. 如: 缓存热门页面, 我们可以自动缓存整个网站中访问量超过一定数值(阀值)的页面, 其中为了减小IO操作, 将缓存的页面放在内容中. 31.如果用户一直向购物车添加商品怎么办?并且他添加一次你查询一次数据库?互联网上用户那么多,这样会对数据库造成很大压力你怎么办?在回答这个问题前,请想好自己的项目是否真的需要使用购物车?(SKU数少,商品结构单一等就不需要使用购物车了) 购物车的设计方案: 购物车的实现不存在哪种方式更好,完全是根据公司和项目架构相关的,类似苏宁使用的是数据库存储,但是国美使用的就是Session,不同的软件架构和不同的业务需求对应的购物车存储也是不一样的 用数据库存你得给数据库造成多大的负担啊, 而且对于购物车, 这种需要实时操作的东西, 数据库的访问量一大了, 就容易出现并发错误, 或者直接崩溃. 用Session确实效率很高, 而且会话是针对各个连接的, 所以便于管理, 但是用Session也不是完美的, 因为Session是有有效期的, 根据服务器的设置不同而不一样长, 如果你在购物的过程中Session超时了, 那么购物车中的东西就会全没了.不知道你看过当当网的购物车没有, 当你下线之后, 再次上线, 购物车中的东西还是存在的, 这对于用户来说非常方便.所以如果你的服务器够强的话, 你完全可以用一个静态变量来保存所有用户的购物车, 比如用一个静态的Map, 以IP作为Key,区分不同用户的购物车, 这样就可以使用户在下线的情况下也可以保存购物车中的内容.这种方法实现过, 只是没有用大量的并发访问测试其稳定性, 但是一定是可行的。 采用存储过程将购物车存储于数据库相应表的方式,优点:数据稳定,不易丢失。缺点:效率低,增加数据库服务器负担。变量 + Datatable保存于客户端,优点:效率高,减轻数据库服务器负担。缺点:Session保存的变量容易丢失,但是一般情况下不会造成影响。变量 + 购物车对象保存于客户端,这种方式以面向对象为指导思想,逻辑上具有一定的复杂性。优点:效率高,减轻数据库服务器负担,使用便捷。缺点:Session保存的变量容易丢失,但是一般情况下不会造成影响 购物车的核心功能 购物车数据存数据库好处有很多,可以分析购买行为,可以为客户保存购买信息(不会因为浏览器关闭而丢失)等,我的这个项目的购物车使用的就是将购物车数据存数据库中,未登录时可以加20个商品,登录后可以加50个。 32.做促销时,商品详情页面的静态页面如何处理价格问题。京东商品详情页虽然仅是单个页面,但是其数据聚合源是非常多的,除了一些实时性要求比较高的如价格、库存、服务支持等通过AJAX异步加载加载之外,其他的数据都是在后端做数据聚合然后拼装网页模板的。整个京东有数亿商品,如果每次动态获取如上内容进行模板拼装,数据来源之多足以造成性能无法满足要求;最初的解决方案是生成静态页,但是静态页的最大的问题: 1、无法迅速响应页面需求变更; 2、很难做多版本线上对比测试。如上两个因素足以制约商品页的多样化发展,因此静态化技术不是很好的方案。
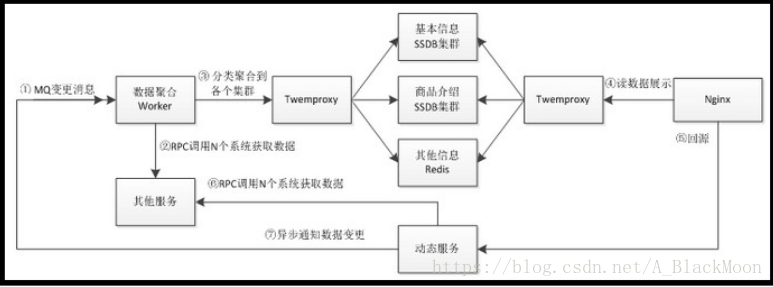
数据主要分为四种:商品页基本信息、商品介绍(异步加载)、其他信息(分类、品牌、店铺等)、其他需要实时展示的数据(价格、库存等)。而其他信息如分类、品牌、店铺是非常少的,完全可以放到一个占用内存很小的Redis中存储;而商品基本信息我们可以借鉴静态化技术将数据做聚合存储,这样的好处是数据是原子的,而模板是随时可变的,吸收了静态页聚合的优点,弥补了静态页的多版本缺点;另外一个非常严重的问题就是严重依赖这些相关系统,如果它们挂了或响应慢则商品页就挂了或响应慢;商品介绍我们也通过AJAX技术惰性加载(因为是第二屏,只有当用户滚动鼠标到该屏时才显示);而实时展示数据通过AJAX技术做异步加载
1、接收商品变更消息,做商品基本信息的聚合,即从多个数据源获取商品相关信息如图片列表、颜色尺码、规格参数、扩展属性等等,聚合为一个大的JSON数据做成数据闭环,以key-value存储;因为是闭环,即使依赖的系统挂了我们商品页还是能继续服务的,对商品页不会造成任何影响; 2、接收商品介绍变更消息,存储商品介绍信息; 3、介绍其他信息变更消息,存储其他信息 技术选型 MQ可以使用如Apache ActiveMQ; Worker/动态服务可以通过如Java技术实现; RPC可以选择如alibaba Dubbo; KV持久化存储可以选择SSDB(如果使用SSD盘则可以选择SSDB+RocksDB引擎)或者ARDB(LMDB引擎版); 缓存使用Redis; SSDB/Redis分片使用如Twemproxy,这样不管使用Java还是Nginx+Lua,它们都不关心分片逻辑; 前端模板拼装使用Nginx+Lua; 数据集群数据存储的机器可以采用RAID技术或者主从模式防止单点故障; 因为数据变更不频繁,可以考虑SSD替代机械硬盘。
核心流程 1、首先我们监听商品数据变更消息; 2、接收到消息后,数据聚合Worker通过RPC调用相关系统获取所有要展示的数据,此处获取数据的来源可能非常多而且响应速度完全受制于这些系统,可能耗时几百毫秒甚至上秒的时间; 3、将数据聚合为JSON串存储到相关数据集群; 4、前端Nginx通过Lua获取相关集群的数据进行展示;商品页需要获取基本信息+其他信息进行模板拼装,即拼装模板仅需要两次调用(另外因为其他信息数据量少且对一致性要求不高,因此我们完全可以缓存到Nginx本地全局内存,这样可以减少远程调用提高性能);当页面滚动到商品介绍页面时异步调用商品介绍服务获取数据; 5、如果从聚合的SSDB集群/Redis中获取不到相关数据;则回源到动态服务通过RPC调用相关系统获取所有要展示的数据返回(此处可以做限流处理,因为如果大量请求过来的话可能导致服务雪崩,需要采取保护措施),此处的逻辑和数据聚合Worker完全一样;然后发送MQ通知数据变更,这样下次访问时就可以从聚合的SSDB集群/Redis中获取数据了。
基本流程如上所述,主要分为Worker、动态服务、数据存储和前端展示;因为系统非常复杂,只介绍动态服务和前端展示、数据存储架构;Worker部分不做实现。 33.商品搜索框的搜索联想如何实现?比如输入“羽绒” ,然后输入框下会列出很多关于羽绒服的搜索条件 “羽绒服男正品折扣 ”等等。
34.一个电商项目,在tomcat里面部署要打几个war包?
35.你说你用了redis缓存,你redis存的是什么格式的数据,是怎么存的?
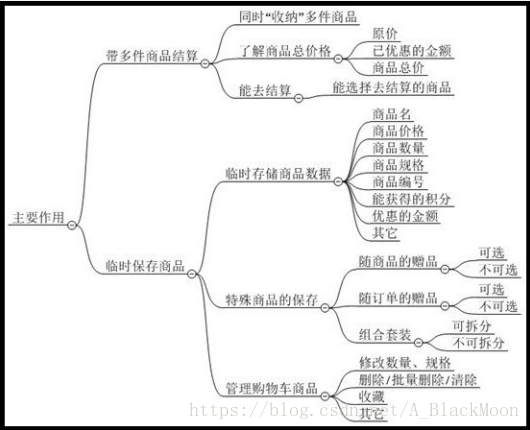
36.购物车知识补充(在设计购物车时需要注意哪些细节)为什么购物车的设计很重要? ①购物车是消费的最后一环 购物车在用户整体消费过程中一般是在最后一环,用户完整的消费体验应该是:打开APP或网站->浏览商品->加入购物车->确认订单并支付,在这个过程中,购物车和支付环节可以合并成一环,基本上用户点开购物车并开始填写地址的时候,就有很大的几率要完成购买,做好商品展现以及推送的环节,如果在最后的购物一环没有好的用户体验,岂不呜呼哀哉。 ②购物车隐含的对比收藏功能 与现实购物车不同的是,网络消费者也比较喜欢把看中但不计划买的商品先放入购物车,或者把商品统一放到购物车直接进行比较,以备日后购买,因此从购物车保存的信息,就能够知道用户的大致偏好。 ③购物车的重交易属性 用户在浏览商品涉及的只是前端展示,但购物车这一环涉及到最终的交易,对于用户来说,需要了解本次交易的基本物品信息、价格信息;而对于商户来说,确认收款、订单生成、物流环节都需要在这里获取到信息,才能完成本次的交易。 购物车设计需要展示的基本信息 购物车主要作用就是告诉用户买了什么,价格多少,不同类型的物品可能会有不同展示方式,但最基本的包括商品名称、价格、数量(若是服务,可能是次数)、其他附属信息。 哪些细节要让用户买得舒服? 亲,记得前面说的用户是如何看待购物车的功能吗?还记得你的用户会多次使用购物车,如果你只是完整做好信息展示不做好其他事情真的好吗? ①登录环节不要放在加入购物车前 请让用户先加入购物车,并在进行结算的时候在提醒用户需要登录。为什么?过早提醒用户需要登录才能购买,会打断用户浏览的流程(用户可能还要购买其他物品好吗?)这样的设置会让部分用户避而远之。 这里涉及到的一个点是在APP端需要记忆用户加入购物车的信息,与登录后的购物车信息合并(如果一开始没有这样考虑好,技术那可能会有难度) ②自动勾选用户本次挑选的商品 用户使用购物车有一个大的作用就是收藏,所以你要知道很多用户在购物车中积累了很多物品,当每次挑选加入购物车的商品,用户每次来到购物车要重新把本次的购买商品选上是很不好的体验。 所以这里一般是自动勾选本次挑选的商品,同样这里也要储存用户的勾选信息。 ③陈列展示,注意沉底商品 让用户看见当前想买的商品就好了,把一些时间久远的,已经卖完的沉底显示。这样做的好处是能让用户看见之前的选择但没购买的商品,提醒一下说不定就又勾上买了哦! ④归类展示,可能增加购买 考虑如何进行归类展示,C2C可以按照商家分类,B2C可以按照品牌分类。 ⑤价格和优惠的提醒 消费用户会关系自己每一次的消费价格,为避免商品列表过长隐藏价格信息,APP端一般会把总价固定底部提示。同时在合计信息中,展示优惠价格,能够促进消费者购买。
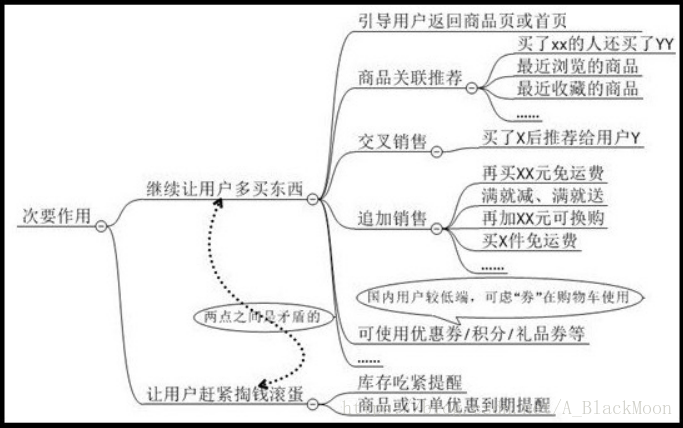
哪些细节要推动用户继续购买? ①还差一点就可以有优惠啦! 凑单,常用的手段包括运费见面或是满减促销,一般在网站底部会展示一些适合凑单的商品;在APP端可以给链接(不过需要权衡用户跳转会不会再跳回来哦!) ②提醒用户有些商品你真的可以买了 有关调查显示,加入购物车而没有购买的,在4小时以内提醒用户,会有27%的唤醒率哦! 所以需要提醒的几个点有: 生成订单但是还没支付的 商品有优惠信息 商品库存不足的 这些信息可以促进消费者购买,注意提醒的时间段,早上9点至晚上8点为宜,其他时间段就可能打扰用户咯(当然也要视产品类型而定啦,只不过大半夜提醒用户买东西确实不好,不是?) 另外安利一个学习教程:1.Java大牛 带你从0到上线开发企业级电商项目(视频+源码) |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号