建立模型
当使用机器学习的方法来解决问题时,比如垃圾邮件分类等,一般的步骤是这样的:
1)从一个简单的算法入手这样可以很快的实现这个算法,并且可以在交叉验证集上进行测试;
2)画学习曲线以决定是否更多的数据,更多的特征或者其他方式会有所帮助;
3)人工检查那些算法预测错误的例子(在交叉验证集上),看看能否找到一些产生错误的原因。
评估模型
首先,引入一个概念,非对称性分类。考虑癌症预测问题,y=1 代表癌症,y=0 代表没有癌症,对于一个数据集,我们建立logistic 回归模型,经过以上建模的步骤,得到一个优化的模型,错误率仅为1%,这貌似是一个很好的结果,但考虑数据集若仅有0.05%的正例(y=1),那么我们直接预测所有y=0,我们得到的模型的错误率仅为0.5%,这便是非对称分类的问题,这样的问题仅考虑错误率是有风险的。
下面引入一种标准的衡量方法:Precision/Recall(精确度和召回率),这种度量最早出现在信息检索问题中的,如下:
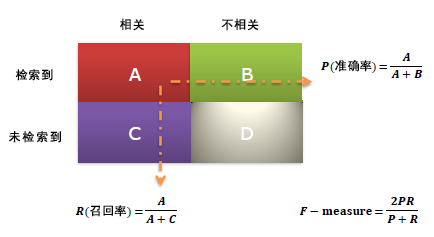
在机器学习的模型中,也可以用这种评估方法,具体如下:

其中:
True Positive (真正例, TP)被模型预测为正的正样本;可以称作判断为真的正确率
True Negative(真负例 , TN)被模型预测为负的负样本 ;可以称作判断为假的正确率
False Positive (假正例, FP)被模型预测为正的负样本;可以称作误报率
False Negative(假负例 , FN)被模型预测为负的正样本;可以称作漏报率
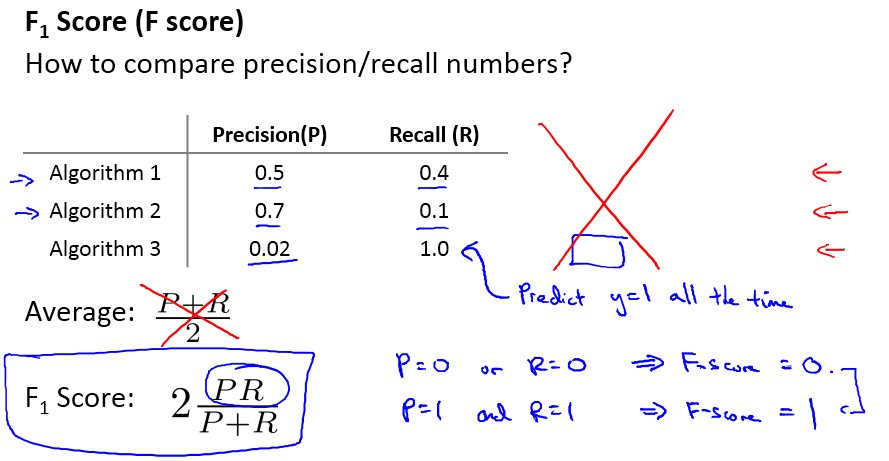
现在需要考虑权衡Precision/Recall:
以logistic 回归为例:
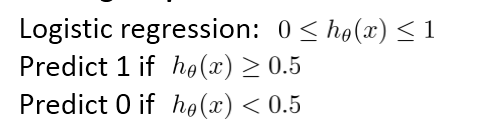
假设我们非常有把握时才预测病人得癌症(y=1), 这个时候,我们常常将阈值设置的很高,FP变小,FN增大,这会导致高精确度,低召回率(Higher precision, lower recall);
假设我们不希望将太多的癌症例子错分(避免假负例,本身得了癌症,确被分类为没有得癌症), 这个时候,阈值就可以设置的低一些,FP变大,FN变小,这又会导致高召回率,低精确度(Higher recall, lower precision);

以上的描述可以用如下的PR曲线来描述,一般准确率提高,召回率会下降:
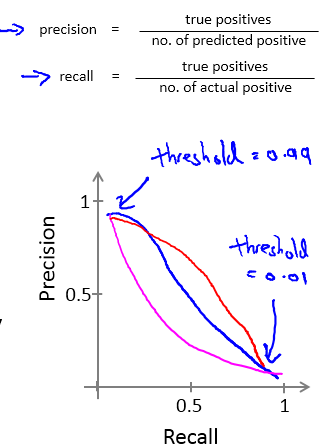
关于如何权衡准确率与召回率:
如果是做搜索,那就是保证召回的情况下提升准确率;如果做疾病监测、反垃圾,则是保准确率的条件下,提升召回。在两者都要求高的情况下,可以用F1来衡量。