机器学习实战之k-近邻算法
一、工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中的每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中的数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,只选择样本数据集前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
二、一般流程:收集数据→准备数据→分析数据→测试算法→使用算法
三、使用python导入数据
python输出矩阵
from numpy import * group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
group输出为:
[[1. 1.1] [1. 1. ] [0. 0. ] [0. 0.1]]
group,shape[0] 输出为4
三、创建函数createDataSet()
from numpy import * import operator def createDataSet(): group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]]) labels = ['A', 'A', 'B', 'B'] return group, labels
四、k-近邻算法的伪代码:
对未知类别数学的数据集中的每个点依次执行以下操作
(1)计算已知类别数据集中的点与当前点之间的距离
(2)按照距离递增次序排序
(3)选取与当前点距离最小的k个点
(4)确定前k个点所在类别的出现频率
(5)返回前k个点出现频率最高的类别作为当前点的预测分类
五、k-近邻算法的python实现
一些小的知识准备如下:
(1)欧氏距离公式
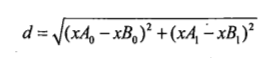
用来计算已知类别数据集中的点与当前点之间的距离
(2)numpy库中的tile()函数
第一个参数为数组,第二个参数可以是一个数字,大多数情况下是一个元组
a = array([0, 1, 2]) b = tile(a, (2, 1)) print(b) //结果为 [[0, 1, 2], [0, 1, 2]]
(3)numpy库中的argsort()函数
import numpy as np a = np.array([[1,3,6],[9,5,6],[2,2,3]]) b = np.sum(a , axis=1) sortindex = np.argsort(b) print("%s+下标[0,1,2]" % b) print(sortindex)
输出为:
[10 20 7]+下标[0 1 2]
[2 0 1]
(4)字典dictionary的get()用法
Python 字典(Dictionary) get() 函数返回指定键的值,如果值不在字典中返回默认值
dict.get(key, default=None)
(5)items()和iteritems()函数的用法
在写到
classCount.iteritems()
运行程序报错
![]()
改为
classCount.items()
运行成功,查询资料后发现Python3中已不再支持iteritems(),将iteritems()改成items()
items()方法是将字典中的每个项分别做为元组,添加到一个列表中,形成了一个新的列表容器
(6)sorted()函数
sorted()函数对所有可迭代的对象进行排序操作。
与sort函数的区别:
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
语法:
sorted(iterable, cmp=None, key=None, reverse=False)
iterable -- 可迭代对象。
cmp -- 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
(7)operator库中的itemgetter()函数
from operator import itemgetter cutting_dim = 1 points = [(6,8), (1,2), (0, 0), (10, -5)] points.sort(key=itemgetter(cutting_dim)) print(points) #[(10, -5), (0, 0), (1, 2), (6, 8)]
最终k-近邻算法的代码实现如下:
from numpy import * import operator def createDataSet(): group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]]) labels = ['A', 'A', 'B', 'B'] return group, labels def classify0(inX, dataSet, labels, k): dataSetSize = dataSet.shape[0] # 训练数据集的个数,本例中dataSetSize值为4 diffMat = tile(inX, (dataSetSize, 1)) - dataSet # 利用tile函数计算出输入的数据集与已知数据集中每个数据的差值 sqDiffMat = diffMat ** 2 # 求平方 sqDistances = sqDiffMat.sum(axis=1) # axis默认值为0,值为1时为将矩阵每一行的向量相加 distance = sqDistances ** 0.5 # 开根号,得出欧氏距离 sortedDistIndicies = distance.argsort() # argsort函数对数组进行排序,并返回下标,默认从小到大 classCount = {} # 创建一个字典 # 统计前k个点所在类别的出现频率 for i in range(k): voteIlabel = labels[sortedDistIndicies[i]] classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) # iteritems()返回一个迭代器,python3后无iteritems,变为items,将字典中的每个项作为元组,添加到一个列表中 # 如{'A':2, 'B':1} 变为 [(A, 2), (B, 1)] return sortedClassCount[0][0] # 返回出现频率最高的类别 group, labels = createDataSet() inX1 = [0, 0] b = classify0(inX1, group, labels, 3) print(b) # 本例输出结果为B
代码来自机器学习实战P19,注释是根据自己的理解来写的,希望能对大家有所帮助。
