

上一次学习了supervision库的Detections类,按照官方文档,接下来学习的是各种Annotator标注器类,我主要学习几个我感兴趣的、有意思的Annotator类型
一、Annotator
所有的XxxAnnotator类都是继承自BaseAnnotator类,并重写了其中的annotator方法
(注:由于几乎大部分的XxxAnnotator类的构造函数__init__都含有参数color,thickness和color_look_up,分别代表边框颜色、边框粗细和颜色映射关系,且都有相应的默认值,一般来说使用默认即可,故后文就不再将这几个参数再写一遍,只会将不同标注器的独有参数标注出来,详细信息可见https://supervision.roboflow.com/0.24.0/detection/annotators官方信息)
-
BoxAnnotator
-
作用:
- 使用一个矩形框标注检测对象
-
代码:
import cv2 import supervision as sv from ultralytics import YOLO model=YOLO('yolo11n.pt') image=cv2.imread('images/cars.png') result=model(image)[0] detections=sv.Detections.from_ultralytics(result) annotator=sv.BoxAnnotator() #创建BoxAnnotator实例 annotator.annotate(scene=image,detections=detections) #调用annotator方法 image=cv2.resize(image,dsize=None,fx=0.5,fy=0.5) #缩放图片大小,使得图片截图小一点 cv2.imshow('img1',image) cv2.waitKey(0)-
结果:

-
-
BoxCornerAnnotator
-
作用:
- 用四角框标注检测对象
-
构造函数参数:
- corner_length:角标的长度,默认为15
-
代码:
# 导库、打开图像、导入模型等操作省略了 annotator=sv.BoxCornerAnnotator(corner_length=40) annotator.annotate(scene=image,detections=detections) image=cv2.resize(image,dsize=None,fx=0.5,fy=0.5) cv2.imshow('img1',image) cv2.waitKey(0) -
结果:

-
-
EllipseAnnotator
-
作用:
- 用椭圆框标注检测目标
-
构造函数参数:
- start_angle:椭圆的起始角度,默认为-45,顺时针为正方向
- end_angle:椭圆的结束角度,默认为235,顺时针为正方向
-
代码
#省略 #代码中若设置了粗细度,只为能明显一些,没有其他含义 annotator=sv.EllipseAnnotator(start_angle=-35,end_angle=220,thickness=10) annotator.annotate(scene=image,detections=detections) image=cv2.resize(image,dsize=None,fx=0.5,fy=0.5) cv2.imshow('img1',image) cv2.waitKey(0) -
结果:

-
-
HaloAnnotator
-
作用:
- 用光环效果标记检测目标,该标注器需要用到Detections类中的mask属性,因此如果使用yolo的话,需要用图像分割的模型例如yolo11n-seg.pt来产生mask
-
构造函数参数:
- opacity:mask的不透明度,默认为0.8
- kernel_size:用于创建光环的平均池化内核大小,默认为40
- 注意:该类因为使用mask而非线条绘制边框,因此没有thickness属性
-
代码:
import cv2 import supervision as sv from ultralytics import YOLO model=YOLO('yolo11n-seg.pt') image=cv2.imread('images/cars.png') result=model(image)[0] detections=sv.Detections.from_ultralytics(result) annotator=sv.HaloAnnotator(opacity=1.0,kernel_size=80) annotator.annotate(scene=image,detections=detections) image=cv2.resize(image,dsize=None,fx=0.5,fy=0.5) cv2.imshow('img1',image) cv2.waitKey(0) -
结果(有点离谱,用seg模型,后面几个路障被识别成人了):

-
-
PercentageBarAnnotator
-
作用:
- 用百分比框来标注检测图像
-
构造函数参数:
- height:百分比框的高,默认为16
- width:百分比框的宽,默认为88
- border_color:百分比框的边框线条颜色,默认为BLACK
- position:百分比条的锚点位置,默认为TOP_CENTER
- border_thickness:边框粗细,默认为None
-
annotate方法:
- custom_values:百分比条的值,如果为None则表示使用该物体的检测置信度来作为值,如果要自定义,应传入一个ndarray数组,长度与检测数目相等,且取值为[0,1],用以表示百分比
-
代码:
#省略 annotator=sv.PercentageBarAnnotator(height=30,width=300) #使用默认的置信度来表示百分比的值 annotator.annotate(scene=image,detections=detections) image=cv2.resize(image,dsize=None,fx=0.5,fy=0.5) cv2.imshow('img1',image) cv2.waitKey(0) -
结果:
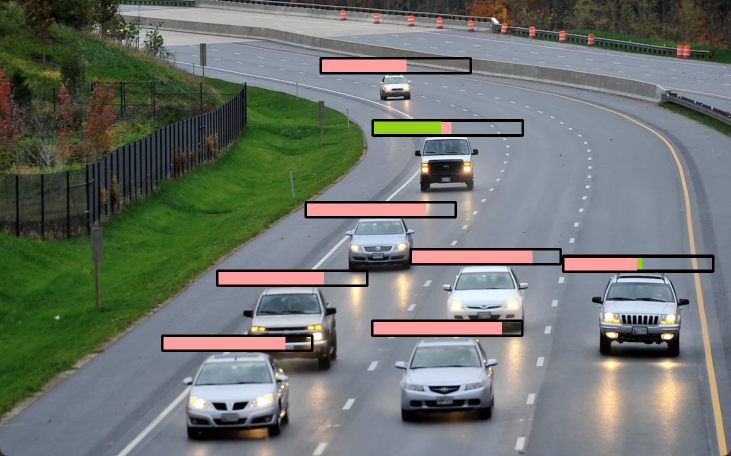
-
-
PixelateAnnotator
-
作用:
- 对检测区域进行像素化,注意,这个类不需要mask,他是直接对矩形框的范围内像素化
-
构造函数参数(仅有一参数):
- pixel_size:像素块的大小,默认为20
-
代码:
#省略 annotator=sv.PixelateAnnotator(pixel_size=30) annotator.annotate(scene=image,detections=detections) image=cv2.resize(image,dsize=None,fx=0.5,fy=0.5) cv2.imshow('img1',image) cv2.waitKey(0) -
结果:

-
-
LabelAnnotator
- 该类的使用和自定义在之前的文章中已经叙述过,就不再赘述了

