
| 这个作业属于哪个课程 | 软工-2018级计算机2班 |
|---|---|
| 这个作业要求在哪里 | 202103226-1作业要求 |
| 这个作业的目标 | 学会用码云 |
| 学号 | 20188375 |
| 参考文献 | eclipse中使用GIT或者码云(eclipse最新版自带GIT插件) |
| 参考文献 | 正则表达式的使用 |
一、码云仓库地址:
二、PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 45 | 50 |
| • Estimate | • 估计这个任务需要多少时间 | 400 | 360 |
| Development | 开发 | 360 | 420 |
| • Analysis | • 需求分析 (包括学习新技术) | 100 | 75 |
| • Design Spec | • 生成设计文档 | 45 | 50 |
| • Design Review | • 设计复审 | 20 | 35 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 60 | 75 |
| • Design | • 具体设计 | 60 | 60 |
| • Coding | • 具体编码 | 480 | 540 |
| • Code Review | • 代码复审 | 60 | 60 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 100 |
| Reporting | 报告 | 60 | 60 |
| • Test Report | • 测试报告 | 60 | 50 |
| • Size Measurement | • 计算工作量 | 45 | 45 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 45 | 45 |
| 合计 | 1960 | 2025 |
三、解题思路描述:
刚看到题目,我先分析问题,把需求点标出来,上网查找关于一些类方法的功能和调用,进行设计
首先我要解决:读文件、单词统计、筛选单词
第一步:文件读取。利用Buffered,从字符中读取文本,缓冲各个字符,从而实现字符、数组和行的高效读取。
第二步:过滤筛选单词
第三步:统计排序。调用BufferedReader中的readline()方法,对每一行的字符数进行累加,最后再加上行数-1就是文本中总的字符数。用while((readLine = br.readLine()) != null) 来定总行数
第四步:输出结果
四、codestyle.md链接
五、计算模块接口的设计与实现过程:
相关类的设计:
根据程序功能要求,我划分为一个主函数,三个类
WordCount 主函数
Print 输出以及格式
File 对文本进行大小写处理
Test 进行单词的过滤和存放以及实现词频的计算
1 public static int CountWordNum(String line, List<String> lists) 2 { 3 int wordcount = 0; 4 String[] wordsArr1 = line.split("[^a-zA-Z0-9]"); //过滤 \w=[a-zA-Z0-9_] 返回一个下标从零开始的一维数组 5 6 for (String newword : wordsArr1) 7 { 8 if(newword.length()!= 0) 9 { 10 if((newword.length() >= 4) && (Character.isLetter(newword.charAt(0)) 11 && Character.isLetter(newword.charAt(1)) && Character.isLetter(newword.charAt(2)) 12 && Character.isLetter(newword.charAt(3)))) 13 { 14 wordcount++; 15 lists.add(newword); 16 } 17 } 18 } 19 20 return wordcount; 21 }
1 public static void CountEachWordNum(Map<String, Integer> wordsCount,List<String> lists) 2 { 3 for (String li : lists) //for(String s:v) s是遍历后赋值的变量,v是要遍历的list 4 { 5 if(wordsCount.get(li) != null) 6 { 7 wordsCount.put(li,wordsCount.get(li) + 1); 8 } 9 else 10 { 11 wordsCount.put(li,1); 12 } 13 14 } 15 }
利用BufferedReader,读取文本,缓冲各个字符。
因为是统计文件的字符数,又有一个重点是不区分大小写并且是输出单词统一为小写格式,所以我先对文件进行处理,把所有的字母都转换为小写的在进行统计。所以在一开始就先对txt进行处理,处理完之后进行下一步。
之后就是统计总的字符数,调用BufferedReader中的readline()方法,对每一行的字符数进行累加,最后只需要再加上行数-1就是文本中总的字符数,总的行数,利用循环判断。
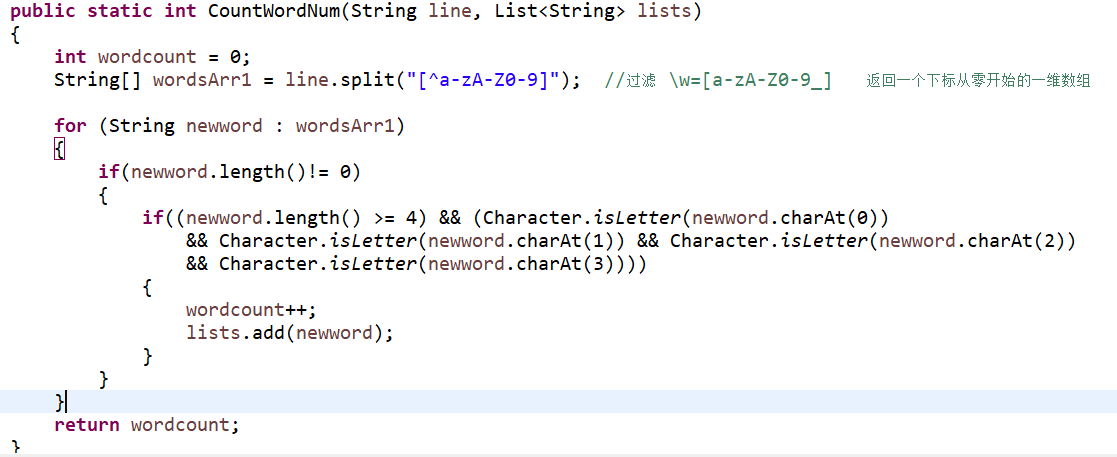
- 统计有效行数和统计字符数的接口:CountWordNum(String line, List<String> lists)

- map排序时的比较算法,比较方法是先判断value值,相同value值,判断它们的字典优先级
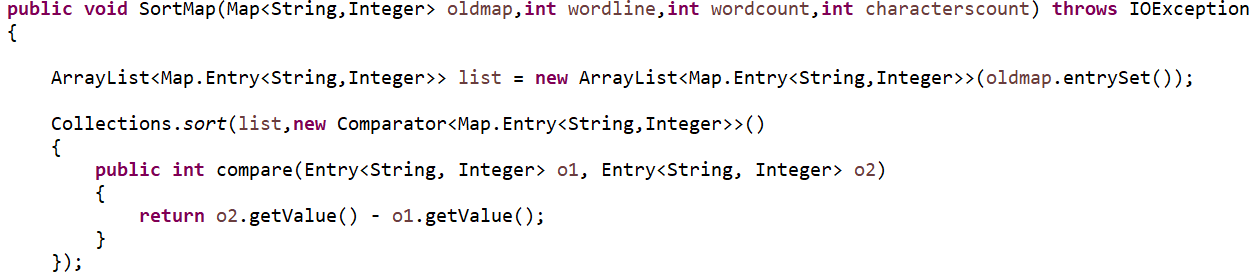
- 统计单词总数的接口:CountWordNum(String line, List<String> lists)
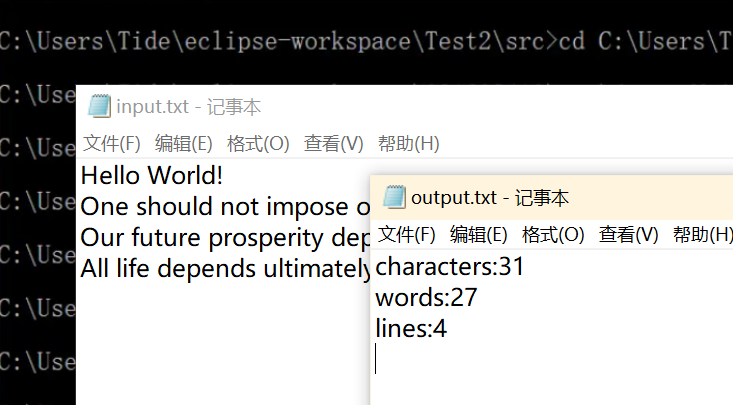
运行结果:
六、计算模块部分单元测试展示:
覆盖率截图:

七、计算模块部分异常处理说明:
- 命令行参数错误:

- 找不到输入文件:

- 其他错误:

八、心路历程与收获:
本次的作业让我受益匪浅,我学会了使用码云,复习了java相关知识和编写异常处理代码。另外,psp表格的计划和实际偏差还比较大,需要再继续努力。希望下一次的作业还可以有更多的收获。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号