
案列代码如下
//优秀学生案例
const obj = {name:'小红',age:18,message:'该学生成绩优异'}
//有些学生列表,但无学生评语,即message
const objList = [{name:'小红',age:17},{name:'小明',age:17},{name:'小绿',age:18},{name:'小蓝',age:17}]
//现在想让这个列表里的所有元素都具有message属性
const changeAge = ()=>{
const arr = [{}]
objList.map((item,index)=>{
obj.age=item.age
obj.name=item.name
arr.push(obj)
})
return arr
}
console.log(changeAge())
结果如下
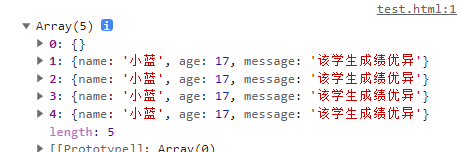
可以看出,结果代码期望的差距还是比较大的,明明我每次更改都push了,但是为啥都是最终值?中间那些小红和小明去哪儿了?
原因:
对象obj是引用数据类型,它们在栈中是以地址的形式存在的.只有在使用的时候才会去堆里面找结果.
我们对上述流程进行解析,其过程大致如下
1.申明一个变量obj,在堆中存一个对象数据{name:"小红",age:18,message:"该学生成绩优异"},然后把这个堆内存的地址,比如值是"1233jjA",给obj,所以obj在整个栈中都是以"1233jjA"的形式参与计算的.
2.当变量修改obj的值的时候,实际上堆里的值也被修改了,而且也是按顺序改了,但是push的时候push的是地址,即"1233jjA"
这一步,会读取堆里的值,并进行修改
obj.age=item.age
obj.name=item.name
但是这一步,是push的地址
arr.push(obj)
所以,最终的函数执行结果其实是["1233jjA","1233jjA","1233jjA","1233jjA","1233jjA"],而此时去读取该地址下的堆拿到的值就是最终态的值.
结论就是,引用数据类型确实没有中间态,因为一个地址只能有一个堆,其值在你拿的时候肯定是只有一个的.
解决方案:
用不同的内存去保持过程值.
简单来说就是每次循环都声明一个对象,比如
//优秀学生案例
const obj = {name:'小红',age:18,message:'该学生成绩优异'}
//有些学生列表,但无学生评语,即message
const objList = [{name:'小红',age:17},{name:'小明',age:17},{name:'小绿',age:18},{name:'小蓝',age:17}]
const changeAge = ()=>{
const arr = [{}]
objList.map((item,index)=>{
let newObj = {...item,message:obj.message}
arr.push(newObj)
})
return arr
}
console.log(changeAge())
此处newObj就是每次循环单独声明的,虽然代码看上去每次循环都一样,但实际上每次的地址都是不一样的.
又比如:
//优秀学生案例
const stendents = {name:'小红',age:18,message:'该学生成绩优异'}
function Obj(obj){
this.name=obj.name
this.age=obj.age
this.message= stendents.message
}
//有些学生列表,但无学生评语,即message
const objList = [{name:'小红',age:17},{name:'小明',age:17},{name:'小绿',age:18},{name:'小蓝',age:17}]
const changeAge = ()=>{
const arr = []
objList.map((item,index)=>{
let newObj = new Obj(item)
arr.push(newObj)
})
return arr
}
console.log(changeAge())
都是一样的效果,都是在循环时每次循环生成不同对象,然后将不同的地址push到arr里,最终打印的时候能拿到所有的值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号