

一、项目中搭配使用SVN和Git
安装SVN;安装熟悉Git;安装maven,修改setting.xml文件;安装eclipse,配置jdk、maven路径;
建立自己的Git仓库,熟悉常用的Git命令。熟悉基本Linux命令。ssh登录线上环境,查看日志。
// #拷贝并跟踪远程的master分支。跟踪的好处是以后可以直接通过pull和push命令来提交或者获取远程最新的代码,而不需要指定远程分支名字 // git clone //#创建名为branchName的branch //git brach branchName //#切换到branchName的branch //git checkout branchName
二、项目启动(antx、Autoconfig、JVM参数)
antx中部分配置项依赖于本机环境,要做出修改。antx.properties文件的作用存储所有placeholders的值,作为AutoConfig的输入,使配置与代码隔离。当更换环境时只需要更改antx.properties,方便集中式管理所有变量,让一套代码适用多个环境。
在一个项目之中,总会有一些参数在开发环境和生产环境是不同的,或者会根据环境的变化而变化。我们如果通过硬编码的方式,势必要经常性的修改项目代码。那我们可以用一种方式,在项目编译前将可变的参数改为可配置的。如此,灵活性就大大的增加,也减少了经常修改代码可能带来的不稳定风险。Autoconfig就是这样的一个工具,它通过占位符将需要动态配置的内容替换。核心思想是把一些可变的配置定义为一个模板,在autoconfig运行的时候从这些模板中生成具体的配置文件。AutoConfig不需要提取源码,也不需要重新build,即可改变目标文件中所有配置文件中placeholders的值,AutoConfig可以对placeholder及其值进行检查。
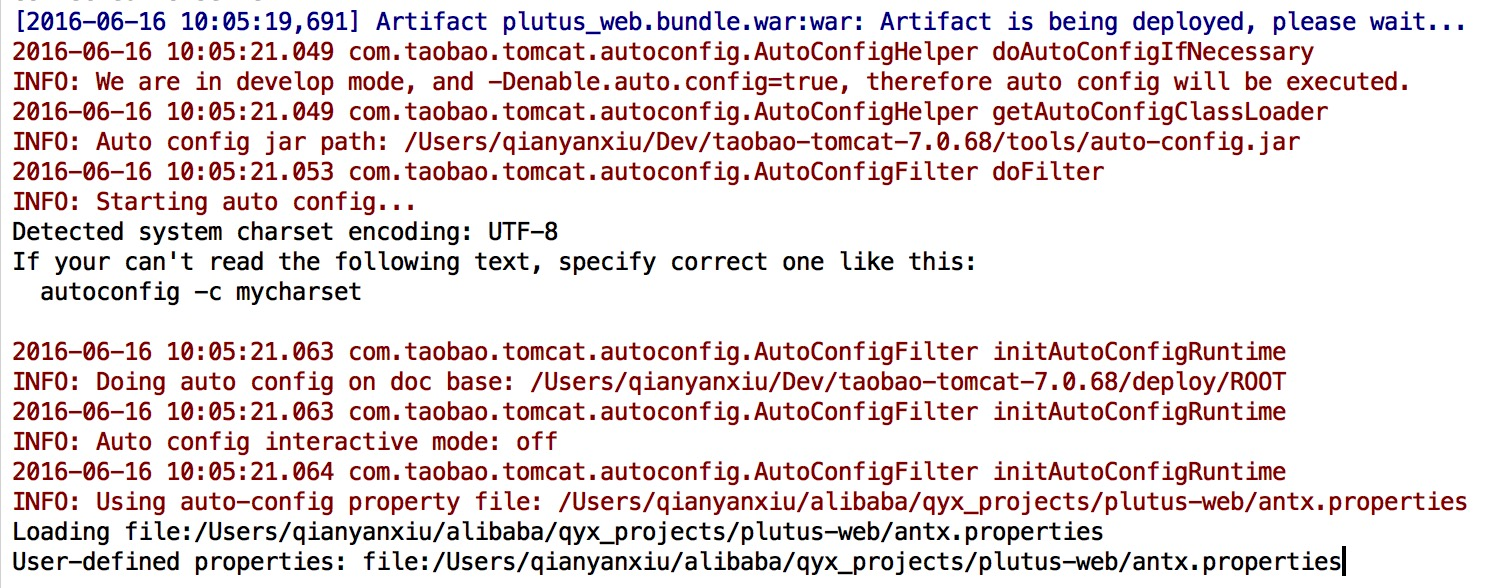
解释下:autoconfig为什么不需要提取源码就可以改变目标文件中的待替换值。观察Ali-Tomcat的启动流程,我们可以发现,Ali-Tomcat在Tomcat基本组件启动完全之后,部署项目之前会再次去寻找项目中的auto-config.xml文件,然后完成对placeholder的再次替换,autoconfig的这种优势是依赖于Ali-Tomcat的,从服务器的启动日志就可以看出。上图为Ali-Tomcat的启动日志。
| 参数名称 | 含义 | 默认值 | |
| -Xms | 初始堆大小 | 物理内存的1/64(<1GB) | 默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制. |
| -Xmx | 最大堆大小 | 物理内存的1/4(<1GB) | 默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制 |
| -Xmn | 年轻代大小(1.4or lator) | 注意:此处的大小是(eden+ 2 survivor space).与jmap -heap中显示的New gen是不同的。 整个堆大小=年轻代大小 + 年老代大小 + 持久代大小. 增大年轻代后,将会减小年老代大小.此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8 |
|
| -XX:NewSize | 设置年轻代大小(for 1.3/1.4) | ||
| -XX:MaxNewSize | 年轻代最大值(for 1.3/1.4) | ||
| -XX:PermSize | 设置持久代(perm gen)初始值 | 物理内存的1/64 | |
| -XX:MaxPermSize | 设置持久代最大值 | 物理内存的1/4 | |
| -Xss | 每个线程的堆栈大小 | JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K.更具应用的线程所需内存大小进行 调整.在相同物理内存下,减小这个值能生成更多的线程.但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右 一般小的应用, 如果栈不是很深, 应该是128k够用的 大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。(校长) 和threadstacksize选项解释很类似,官方文档似乎没有解释,在论坛中有这样一句话:"” -Xss is translated in a VM flag named ThreadStackSize” 一般设置这个值就可以了。 |
|
| -XX:ThreadStackSize | Thread Stack Size | (0 means use default stack size) [Sparc: 512; Solaris x86: 320 (was 256 prior in 5.0 and earlier); Sparc 64 bit: 1024; Linux amd64: 1024 (was 0 in 5.0 and earlier); all others 0.] | |
| -XX:NewRatio | 年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代) | -XX:NewRatio=4表示年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5 Xms=Xmx并且设置了Xmn的情况下,该参数不需要进行设置。 |
|
| -XX:SurvivorRatio | Eden区与Survivor区的大小比值 | 设置为8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10 | |
| -XX:LargePageSizeInBytes | 内存页的大小不可设置过大, 会影响Perm的大小 | =128m | |
| -XX:+UseFastAccessorMethods | 原始类型的快速优化 | ||
| -XX:+DisableExplicitGC | 关闭System.gc() | 这个参数需要严格的测试 | |
| -XX:MaxTenuringThreshold | 垃圾最大年龄 | 如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代. 对于年老代比较多的应用,可以提高效率.如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活 时间,增加在年轻代即被回收的概率 该参数只有在串行GC时才有效. |
|
| -XX:+AggressiveOpts | 加快编译 | ||
| -XX:+UseBiasedLocking | 锁机制的性能改善 | ||
| -Xnoclassgc | 禁用垃圾回收 | ||
| -XX:SoftRefLRUPolicyMSPerMB | 每兆堆空闲空间中SoftReference的存活时间 | 1s | softly reachable objects will remain alive for some amount of time after the last time they were referenced. The default value is one second of lifetime per free megabyte in the heap |
| -XX:PretenureSizeThreshold | 对象超过多大是直接在旧生代分配 | 0 | 单位字节 新生代采用Parallel Scavenge GC时无效 另一种直接在旧生代分配的情况是大的数组对象,且数组中无外部引用对象. |
| -XX:TLABWasteTargetPercent | TLAB占eden区的百分比 | 1% | |
| -XX:+CollectGen0First | FullGC时是否先YGC | false |
JVM性能调优过程,也就是修改上述参数的配置文件,如下图所示,永久代的内存不够,需要增大PermGen的空间,进行 jvm 参数设置:-Xms512m -Xmx1024m -XX:PermSize=128m -XX:MaxPermSize=256M -Dfile.encoding=UTF-8。JVM各参数的含义上图。
三、maven学习
什么是pom,pom作为项目对象模型。通过xml表示maven项目,使用pom.xml来实现。POM包括了所有的项目信息:groupId:项目或者组织的唯一标志,并且配置时生成路径也是由此生成,如org.myproject.mojo生成的相对路径为:/org/myproject/mojo。artifactId:项目的通用名称。version:项目的版本。packaging:打包机制,如pom,jar,maven-plugin,ejb,war,ear,rar,par。
pom继承关系:要继承pom就需要有一个父pom,在Maven中定义了超级pom.xml,任何没有申明自己父pom.xml的pom.xml都将默认继承自这个超级pom.xml。(项目分级)子pom.xml会完全继承父pom.xml中所有的元素,而且对于相同的元素,一般子pom.xml中的会覆盖父pom.xml中的元素,但是有几个特殊的元素它们会进行合并而不是覆盖。这些特殊的元素是:dependencies,developers,contributors,plugin列表,resources。当需要继承指定的一个Maven项目时,我们需要在自己的pom.xml中定义一个parent元素,在这个元素中指明需要继承项目的groupId、artifactId和version。当被继承项目与继承项目的目录结构不是父子关系的时候,这个时候就需要在子项目的pom.xml文件定义中的parent元素下再加上一个relativePath元素的定义,用以描述父项目的pom.xml文件相对于子项目的pom.xml文件的位置。
pom聚合关系:说说我对聚合和被聚合的理解,比如说如果projectA聚合到projectB,那么我们就可以说projectA是projectB的子模块, projectB是被聚合项目,也可以类似于继承那样称为父项目。对于聚合而言,这个主体应该是被聚合的项目。所以,我们需要在被聚合的项目中定义它的子模块,而不是像继承那样在子项目中定义父项目。具体做法是:修改被聚合项目的pom.xml中的packaging元素的值为pom;在被聚合项目的pom.xml中的modules元素下指定它的子模块项目。如果子模块projectB是处在被聚合项目projectA的子目录下,即与被聚合项目的pom.xml处于同一目录。这里使用的module值是子模块projectB对应的目录名projectB,而不是子模块对应的artifactId。这个时候当我们对projectA进行mvn package命令时,实际上Maven也会对projectB进行打包。当被聚合项目与子模块项目在目录结构上不是父子关系的时候,需要在module元素中指定以相对路径的方式指定子模块。以plutus-web根目录下的pom为例:

注意:如果有A,B,C三个子工程,并且install的顺序是A,B,C,这样要是A依赖B的话,执行mvn clean install必然报错,因为install A的时候,B还没有生成,所以我们在写modules的时候一定要注意顺序。如果projectB继承projectA,同时需要把projectB聚合到projectA,projectA的pom.xml中需要定义它的packaging为pom,需要定义它的modules,同时在projectB的pom.xml文件中新增一个parent元素,用以定义它继承的项目信息。
pom依赖关系,项目之间的依赖是通过pom.xml文件里面的dependencies元素下面的dependency元素进行的。一个dependency元素定义一个依赖关系。在dependency元素中我们主要通过依赖项目的groupId、artifactId和version来定义所依赖的项目。
setting.xml一般存在与两个地方:maven的安装目录/conf/,和/.m2/下。他们的区别是在maven安装目录下的setting.xml是所有用户都可以应用的配置,而user.home下的是针对某一用户的配置(推荐是在user.home下)。如果两个都进行了配置,则在应用的时候会将两个配置文件进行中和,而且user.home下的setting.xml优先级大于maven安装目录下的。
maven中的snapshot快照仓库,maven中的仓库分为两种,snapshot快照仓库和release发布仓库。snapshot快照仓库用于保存开发过程中的不稳定版本,release正式仓库则是用来保存稳定的发行版本。在使用maven过程中,我们在开发阶段经常性的会有很多公共库处于不稳定状态,随时需要修改并发布,可能一天就要发布一次,遇到bug时,甚至一天要发布N次。maven的依赖管理是基于版本管理的,对于发布状态的artifact,如果版本号相同,即使我们内部的镜像服务器上的组件比本地新,maven也不会主动下载的。如果我们在开发阶段都是基于正式发布版本来做依赖管理,那么遇到这个问题,就需要升级组件的版本号,可这样就明显不符合要求和实际情况了。如果是基于快照版本,那么问题就自热而然的解决了,maven2会根据模块的版本号(pom文件中的version)中是否带有-SNAPSHOT来判断是快照版本还是正式版本。如果是快照版本,那么在mvn deploy时会自动发布到快照版本库中,而使用快照版本的模块,在不更改版本号的情况下,直接编译打包时,maven会自动从镜像服务器上下载最新的快照版本。如果是正式发布版本,那么在mvn deploy时会自动发布到正式版本库中,而使用正式版本的模块,在不更改版本号的情况下,编译打包时如果本地已经存在该版本的模块则不会主动去镜像服务器上下载。所以,我们在开发阶段,可以将公用库的版本设置为快照版本,而被依赖组件则引用快照版本进行开发,在公用库的快照版本更新后,我们也不需要修改pom文件提示版本号来下载新的版本,直接mvn执行相关编译、打包命令即可重新下载最新的快照库了,从而也方便了我们进行开发。
maven的仲裁机制。maven自己的仲裁机制是先看路径长度,路径长度一样再看声明顺序。
四、Socket
socket,通常也称作"套接字",用于描述IP地址和端口,是网络上运行的两个程序间双向通讯的一端,它既可以接受请求,也可以发送请求,利用它可以较为方便的编写网络上的数据的传递。Socket通讯过程:服务端监听某个端口是否有连接请求,客户端向服务端发送连接请求,服务端收到连接请求向客户端发出接收消息,这样一个连接就建立起来了。客户端和服务端都可以相互发送消息与对方进行通讯。
Socket编程中的重要方法,Accept方法用于产生”阻塞”,直到接受到一个连接,并且返回一个客户端的Socket对象实例。getInputStream方法获得网络连接输入,即一个输入流,同时返回一个IutputStream对象实例,客户端的Socket对象上的 getInputStream方法得到的输入流其实就是从服务器端发回的数据流;服务器端的输入流就是接受客户端发来的数据流。getOutputStream方法实现一个输出流,同时返回一个OutputStream对象实例。客户端的输出流就是将要发送到服务器端的数据流,服务器端的输出流就是发给客户端的数据流。注意:getInputStream和getOutputStream方法均会产生一个IOException,它必须被捕获;getInputStream和getOutputStream方法返回的是流对象,通常都会被另一个流对象使用。所以还要对这两种方法获取的数据进行封装,以便更方便的使用。
单线程代码有一个问题,就是Server只能接受一个Client请求,当第一个Client连接后就占据了这个位置,后续Client不能再继续连接。所以需要做些改动,当Server每接受到一个Client连接请求之后,都把处理流程放到一个独立的线程里去运行,然后等待下一个Client连接请求,这样就不会阻塞Server端接收请求了。每个独立运行的程序在使用完Socket对象之后要将其关闭。改进后的代码同样在上面的git地址。
五、并发编程学习(线程之间的互斥和同步)
synchronized锁重入,关键字synchronized拥有锁重入的功能。也就是在使用synchronized时,当一个线程得到一个对象锁后,再次请求此对象锁时,是可以再次得到该对象的锁的。所以在一个synchronized方法/块的内部调用本类的其他synchronized方法/块时,是永远可以得到锁的。可重入锁就是自己可以再次获取自己的内部锁,当存在父子类继承关系时,子类是完全可以通过“可重入锁”调用父类的同步方法的。
synchronized同步语句块,对其他synchronized同步方法或者synchronized(this)同步代码块调用呈阻塞状态。同一时间只有一个线程可以执行synchronized同步方法中的代码。
synchronized(非this对象x),当多个线程同时执行synchronized(x){}同步代码块时呈同步效果;当其他线程执行x对象中synchronized同步方法时呈同步效果;当其他线程执行x对象方法里面的synchronized(this)代码块时也呈现同步效果;但是如果其他线程调用不加synchronized关键字的方法时,还是异步调用。
synchronized与volatile比较,volatile性能比synchronized要好,并且volatile只能修饰于变量,而synchronized可以修饰方法,以及代码块。多线程访问volatite不会发生阻塞,而synchronized会出现阻塞。volatite能保证数据的可见性,但不能保证原子性;而synchronized可以保证原子性,也可以间接保证可见性,因为它会将私有内存和公共内存中的数据做同步。volatite解决的是变量在多个线程之间的可见性;而synchronized关键字解决的是多个线程之间访问资源的同步性。volatite提示线程每次从共享内存中读取变量,而不是从私有内存中读取,这样就保证了同步数据的可见性。
Lock接口最大的优势是为读和写分别提供了锁,读写锁ReadWriteLock拥有更加强大的功能,它可细分为读锁和写锁。读锁可以允许多个进行读操作的线程同时进入,但不允许写进程进入;写锁只允许一个写进程进入,在这期间任何进程都不能再进入。
ReentrantLock是一个可重入的互斥锁 Lock,它具有与使用 synchronized 方法和语句所访问的隐式监视器锁相同的一些基本行为和语义,但功能更强大。ReentrantLock 将由最近成功获得锁,并且还没有释放该锁的线程所拥有。当锁没有被另一个线程所拥有时,调用lock的线程将成功获取该锁并返回。如果当前线程已经拥有该锁,此方法将立即返回。可以使用isHeldByCurrentThread()和getHoldCount()方法来检查此情况是否发生。
Condition 将Object监视器方法(wait、notify 和 notifyAll)分解成截然不同的对象,以便通过将这些对象与任意 Lock 实现组合使用,为每个对象提供多个等待集合。其中,Lock 替代了 synchronized 方法和语句的使用,Condition 替代了 Object 监视器方法的使用。Condition实例实质上被绑定到一个锁上。要为特定Lock实例获得Condition实例,请使用其newCondition()方法。
ReentrantReadWriteLock,可重入读写锁。它实现ReadWriteLock接口,此锁允许 reader 和 writer 按照 ReentrantLock 的样式重新获取读取锁或写入锁。在写入线程保持的所有写入锁都已经释放后,才允许重入 reader 使用它们。锁降级:重入还允许从写入锁降级为读取锁,其实现方式是:先获取写入锁,然后获取读取锁,最后释放写入锁。但是,从读取锁升级到写入锁是不可能的。它对Condition的支持。写入锁提供了一个 Condition 实现,对于写入锁来说,该实现的行为与 ReentrantLock.newCondition() 提供的 Condition 实现对 ReentrantLock 所做的行为相同。当然,此 Condition 只能用于写入锁。读取锁不支持 Condition,readLock().newCondition() 会抛出 UnsupportedOperationException。
六、线程间的通信
wait()方法,wait()的作用是使当前执行代码的线程进行等待,当前线程释放锁。调用之前线程必须获得该对象的对象锁。
notify()方法,不会使当前线程马上释放对象锁,呈wait()状态的的线程也不能马上获取该对象的对象锁,要等到执行notify()方法的线程将程序执行完,退出synchronized代码块后才会释放锁。
notifyALL()方法,可以使所有正在等待队列中等待同意共享资源的全部线程从等待状态退出,进入可运行状态。
wait和sleep方法的不同,这两个方法来自不同的类分别是,sleep来自Thread类静态方法,和wait来自Object类成员方法。(sleep是Thread的静态类方法,谁调用的谁去睡觉,即使在a线程里调用了b的sleep方法,实际上还是a去睡觉,要让b线程睡觉要在b的代码中调用sleep。)最主要是sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。(sleep不出让系统资源;wait是进入线程等待池等待,出让系统资源,其他线程可以占用CPU。一般wait不会加时间限制,因为如果wait线程的运行资源不够,再出来也没用,要等待其他线程调用notify/notifyAll唤醒等待池中的所有线程,才会进入就绪队列等待OS分配系统资源。sleep(milliseconds)可以用时间指定使它自动唤醒过来,如果时间不到只能调用interrupt()强行打断。)Thread.Sleep(0)的作用是“触发操作系统立刻重新进行一次CPU竞争”。使用范围:wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用。sleep必须捕获异常(InterruptedException),而wait,notify和notifyAll不需要捕获异常。总结:最大的不同是在等待时wait会释放锁,而sleep一直持有锁。Wait通常被用于线程间交互,sleep通常被用于暂停执行。
join()的作用是使所属的线程对象x正常执行run()方法中的任务,而使当前线程z进行无限期的阻塞,等待线程x销毁后再继续执行线程z后面的代码。方法join具有使线程排队运行的作用类似于同步的运行效果。join与synchronized的区别是:join在内部使用wait()方法进行等待(所以具有释放锁的特点),而synchronized关键字使用的是“对象监视器”原理作为同步。
生产者消费者,操作栈List实现,List最大容量是1,解决wait条件改变与假死,多生产者多消费者实现。
七、线程池
为什么使用线程池?线程启动一个新线程的成本是比较高的,因为它涉及与操作系统交互,在这种情形下,使用线程池可以很好的提高性能,尤其是当程序中需要创建大量生存期很短暂的线程时,更应该考虑使用线程池。线程池在系统启动时即创建大量空闲的线程,程序将一个Runnable对象传给线程池,线程池就会启动一条线程来执行该对象的run()方法,当run()方法执行结束后,该线程并不会死亡,而是再次返回线程池中成为空闲状态,等待执行下一个Runnable对象的run方法。使用线程池可以有效地控制系统中并发线程的数量,当系统中包含大量并发线程时,会导致系统性能剧烈下降,甚至导致JVM崩溃,而线程池的最大线程数参数可以控制系统中并发线程数目不超过此数目。
ThreadPoolExecutor重要参数,corePoolSize:核心池的大小,这个参数跟后面讲述的线程池的实现原理有非常大的关系。在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务,除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法,从这2个方法的名字就可以看出,是预创建线程的意思,即在没有任务到来之前就创建corePoolSize个线程或者一个线程。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中。maximumPoolSize:线程池最大线程数,这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程。keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会终止,直到线程池中的线程数不超过corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0。
对参数的个人理解:如果当前线程池中的线程数目小于corePoolSize,则每来一个任务,就会创建一个线程去执行这个任务。当前线程池中的线程数目>=corePoolSize,则每来一个任务,会尝试将其添加到任务缓存队列当中,若添加成功,则该任务会等待空闲线程将其取出去执行;若添加失败(一般来说是任务缓存队列已满),则会尝试创建新的线程去执行这个任务。如果当前线程池中的线程数目达到maximumPoolSize,则会采取任务拒绝策略进行处理。如果线程池中的线程数量大于 corePoolSize时,如果某线程空闲时间超过keepAliveTime,线程将被终止,直至线程池中的线程数目不大于corePoolSize;如果允许为核心池中的线程设置存活时间,那么核心池中的线程空闲时间超过keepAliveTime,线程也会被终止。
ThreadPoolExecutor的重要方法,execute()方法实际上是Executor中声明的方法,在ThreadPoolExecutor进行了具体的实现,这个方法是ThreadPoolExecutor的核心方法,通过这个方法可以向线程池提交一个任务,交由线程池去执行。submit()方法是在ExecutorService中声明的方法,在AbstractExecutorService就已经有了具体的实现,在ThreadPoolExecutor中并没有对其进行重写,这个方法也是用来向线程池提交任务的,但是它和execute()方法不同,它能够返回任务执行的结果,去看submit()方法的实现,会发现它实际上还是调用的execute()方法,只不过它利用了Future来获取任务执行结果。shutdown()和shutdownNow()是用来关闭线程池的。
// #shutdown()和shutdownNow()区别: // shutdown():不会立即终止线程池,而是要等所有任务缓存队列中的任务都执行完后才终止,但再也不会接受新的任务 // shutdownNow():立即终止线程池,并尝试打断正在执行的任务,并且清空任务缓存队列,返回尚未执行的任务
BlockingQueue,阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。 阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。用wait和notify实现阻塞队列;用ReentrantLock实现阻塞队列。
静态方法上synchronzied和非静态方法上synchronized关键字的区别是什么?在使用synchronized块来同步方法时,非静态方法可以通过this来同步,而静态方法必须使用class对象来同步,非静态方法也可以通过使用class来同步静态方法。但是静态方法中不能使用this来同步非静态方法。这点在使用synchronized块需要注意。synchronized是对类的当前实例进行加锁,防止其他线程同时访问该类的该实例的所有synchronized块,注意这里是“类的当前实例”, 类的两个不同实例就没有这种约束了。static synchronized是要控制类的所有实例的访问了,static synchronized是限制线程同时访问jvm中该类的所有实例同时访问对应的代码块。在类中某方法或某代码块中有 synchronized,那么在生成一个该类实例后,该类也就有一个监视块,放置线程并发访问该实例synchronized保护块,而static synchronized则是所有该类的实例公用一个监视块了,也也就是两个的区别了,也就是synchronized相当于 this.synchronized,而static synchronized相当于Something.synchronized。
八、spring
九、MyBatis
MyBatis要达到目的就是把用户关心的和容易变化的数据放到配置文件中配置,方便用户管理。而把流程性的、固定不变的交给ibatis来实现。这样是用户操作数据库简单、方便。以前用jdbc有很多操作是与业务和数据无关的,但我们只需要一个运行sql语句的功能,还有取回结果的功能,但是jdbc要求你处理连接、会话、statement,尤其是还要你注意关闭资源,还要写try catch处理异常。ibatis 就是帮你把这些乱七八糟的东西都做了。ibatis通过 SQL Map将Java对象映射成SQL语句和将结果集再转化成Java对象,与其他ORM框架相比,既解决了Java对象与输入参数和结果集的映射,又能够让用户方便的手写使用 SQL语句。
//#总结起来有一下几个优点: //ibatis把sql语句从Java源程序中独立出来,放在单独的XML文件中编写,给程序的维护带来了很大便利。 //ibatis封装了底层JDBC API的调用细节,并能自动将结果集转换成Java Bean对象,大大简化了Java数据库编程的重复工作。 //因为ibatis需要我们自己去编写sql语句,程序员可以结合数据库自身的特点灵活控制sql语句,因此能够实现比hibernate等全自动orm框架更高的查询效率,能够完成复杂查询。相对简单易于学习,易于使用, 非常实用。
Mybatis原理,该框架的一个重要组成部分就是其 SqlMap 配置文件,SqlMap 配置文件的核心是 Statement 语句包括 CIUD。 MyBatis通过解析 SqlMap 配置文件得到所有的 Statement 执行语句,同时会形成 ParameterMap、ResultMap 两个对象用于处理参数和经过解析后交给数据库处理的 Sql 对象。这样除去数据库的连接,一条 SQL 的执行条件已经具备了。数据的映射大体的过程是这样的:根据 Statement 中定义的 SQL 语句,解析出其中的参数,按照其出现的顺序保存在 Map 集合中,并按照 Statement 中定义的 ParameterMap 对象类型解析出参数的 Java 数据类型。并根据其数据类型构建 TypeHandler 对象,参数值的复制是通过 DataExchange 对象完成的。
public class Test { public static void main(String[] args) { Class.forName("oracle.jdbc.driver.OracleDriver"); Connection conn = DriverManager.getConnection(url, user, password); java.sql.PreparedStatement st = conn.prepareStatement(sql); st.setInt(0, 1); st.execute(); java.sql.ResultSet rs = st.getResultSet(); while (rs.next()) { String result = rs.getString(colname); } } }
上述代码展现了原始的java操作数据库的代码,Mybatis就是将上面这几行代码分解包装。但是最终执行的仍然是这几行代码。前两行是对数据库的数据源的管理包括事务管理,3、4 两行ibatis通过配置文件来管理 SQL 以及输入参数的映射,6、7、8 行是 iBATIS 获取返回结果到 Java 对象的映射,他也是通过配置文件管理。
spring和Mybatis的事务机制,MyBatis的SqlMapSession 对象的创建和释放根据不同情况会有不同,因为 SqlMapSession 负责创建数据库的连接,包括对事务的管理,iBATIS 对管理事务既可以自己管理也可以由外部管理,iBATIS 自己管理是通过共享 SqlMapSession 对象实现的,多个 Statement 的执行时共享一个 SqlMapSession 实例,而且都是线程安全的。如果是外部程序管理就要自己控制 SqlMapSession 对象的生命周期。
spring对事务的解决办法其实分为2种:编程式实现事务,AOP配置声明式解决方案。spring提供了许多内置事务管理器实现,对于ibatis是DataSourceTransactionManager:位于org.springframework.jdbc.datasource包中,数据源事务管理器,提供对单个javax.sql.DataSource事务管理,用于Spring JDBC抽象框架、iBATIS框架的事务管理。注解形式@Transactional实现事务管理,只能被应用到public方法上,对于其它非public的方法,如果标记了@Transactional也不会报错,但方法没有事务功能。在public方法上面使用了@Transactional注解,当有线程调用此方法时,Spring会首先扫描到@Transactional注解,进入DataSourceTransactionManager继承自AbstractPlatformTransactionManager的getTransaction()方法,在getTransaction()方法内部,会调用doGetTransaction()方法,@Transactional的注解中,存在一个事务传播行为的概念,即propagation参数,默认等于PROPAGATION_REQUIRED,表示如果当前没有事务,就新建一个事务,如果存在一个事务,方法块将使用这个事务。
//#Spring的transactionAttributes的配置 //PROPAGATION_REQUIRED--支持当前事务,如果当前没有事务,就新建一个事务。这是最常见的选择。 //PROPAGATION_SUPPORTS--支持当前事务,如果当前没有事务,就以非事务方式执行。 //PROPAGATION_MANDATORY--支持当前事务,如果当前没有事务,就抛出异常。 //PROPAGATION_REQUIRES_NEW--新建事务,如果当前存在事务,把当前事务挂起。 //PROPAGATION_NOT_SUPPORTED--以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。 //PROPAGATION_NEVER--以非事务方式执行,如果当前存在事务,则抛出异常。 //PROPAGATION_NESTED--如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则进行与PROPAGATION_REQUIRED类似的操作
十、webx学习(三剑客:listener、filter、servlet)
<!-- 初始化日志系统 --> <listener> <listener-class>com.alibaba.citrus.logconfig.LogConfiguratorListener</listener-class> </listener> <!-- 装载/WEB-INF/webx.xml, /WEB-INF/webx-*.xml --> <listener> <listener-class>com.alibaba.citrus.webx.context.WebxContextLoaderListener</listener-class> </listener>
这里是整个Webx应用的起点,声明了一个listener。顾名思义,listener就是监听者,它竖起耳朵监听了容器的事件,当容器发生一些事情时,它将会做出预先定义的动作。Webx利用LogConfiguratorListener来初始化日志系统。LogConfiguratorListener会根据你当前应用所依赖的日志系统(通常配置在maven project中),来自动选择合适的日志配置文件。假设你的应用依赖了logback的jar包,那么listener就会查找/WEB-INF/logback.xml,并用它来初始化logback;如果你的应用依赖了log4j的jar包,那么listener也会很聪明地查找/WEB-INF/log4j.xml配置文件。假如以上配置文件不存在,listener会使用默认的配置,把日志打印在控制台上。Listener支持对配置文件中的placeholders进行替换。Listener支持同时初始化多种日志系统。看WebxContextLoaderListener这个类名:Webx环境加载器监听者。我们可以知道,这个监听器是负责在启动的时候加载Webx环境的。
public class WebxContextLoaderListener extends ContextLoaderListener { ... } public class ContextLoaderListener implements ServletContextListener { ... } public interface ServletContextListener extends EventListener { public void contextInitialized ( ServletContextEvent sce ); public void contextDestroyed ( ServletContextEvent sce ); }
可见,WebxContextLoaderListener继承了ContextLoaderListener,而ContextLoaderListener实现了EventListener接口。接口是干嘛用的呢?容器初始化完成后做的事情;容器销毁后做的事情;这就是EventListener接口。只要你的listener实现了这个接口,容器初始化和销毁的时候就要调用这两个接口方法。所以,这个过程总结起来就是,容器根据web.xml里的这段描述实例化WebxContextLoaderListener,然后在初始化完成的时候调用该实例的contextInitialized方法,从而实现了一种通知机制。下面是WebxContextLoaderListener的全部源代码。
public class WebxContextLoaderListener extends ContextLoaderListener { @Override protected final ContextLoader createContextLoader() { return new WebxComponentsLoader() { @Override protected Class<? extends WebxComponentsContext> getDefaultContextClass() { Class<? extends WebxComponentsContext> defaultContextClass = WebxContextLoaderListener.this .getDefaultContextClass(); if (defaultContextClass == null) { defaultContextClass = super.getDefaultContextClass(); } return defaultContextClass; } }; } protected Class<? extends WebxComponentsContext> getDefaultContextClass() { return null; } }
createContextLoader返回的是一个ContextLoader类的实例;方法里new出来一个WebxComponentsLoader的实例作为返回值,因此,这个返回值实际上是WebxComponentsLoader类的实例;方法把这个实例new出来的时候,顺便覆盖了一下WebxComponentsLoader类的getDefaultContextClass方法,因此,返回的实例实际上是一个WebxComponentsLoader类的匿名子类的实例,且这个子类覆盖了getDefaultContextClass方法。
实现了EventListener接口,就可以在容器初始化完成的时候得到通知,因此,我们看看WebxContextLoaderListener这个类对contextInitialized方法的实现。容易发现,它通过继承ContextLoaderListener方法实现了这个方法,因此这个方法会在容器初始化的时候被容器调用:
public class ContextLoaderListener implements ServletContextListener { private ContextLoader contextLoader; /** * Initialize the root web application context. */ public void contextInitialized(ServletContextEvent event) { this.contextLoader = createContextLoader(); this.contextLoader.initWebApplicationContext(event.getServletContext()); } ... }
这个方法做了两件事情:用createContextLoader方法新建一个contextLoader成员并且调用其initWebApplicationContext方法。显然,ContextLoader就是环境加载器,主要作用就是加载并启动下文会讲到的WebApplicationContext。除此之外,由于WebxContextLoaderListener覆盖了createContextLoader方法,因此在我们的启动过程中,实际上调用的是上上个代码中的createContextLoader方法。所以,这个新建的过程返回的是WebxComponentsLoader类的匿名子类的实例,从而,调用的initWebApplicationContext方法也是WebxComponentsLoader类的initWebApplicationContext方法。
<filter> <filter-name>mdc</filter-name> <filter-class>com.alibaba.citrus.webx.servlet.SetLoggingContextFilter</filter-class> </filter> <filter> <filter-name>webx</filter-name> <filter-class>com.alibaba.citrus.webx.servlet.WebxFrameworkFilter</filter-class> <init-param> <param-name>excludes</param-name> <param-value><!-- 需要被“排除”的URL路径,以逗号分隔,前缀!表示“包含”。例如/static, *.jpg, !/uploads/*.jpg --></param-value> </init-param> <init-param> <param-name>passthru</param-name> <param-value><!-- 需要被“略过”的URL路径,以逗号分隔,前缀!表示“不要略过”。例如/myservlet, *.jsp --></param-value> </init-param> </filter> <filter-mapping> <filter-name>mdc</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> <filter-mapping> <filter-name>webx</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>
SettLoggingContextFilter在经过这个filter的时候,加一些特殊的日志上下文,比如说请求的url。WebxFrameworkFilter是webx控制器的filter,用来接收所有的请求:可选的参数:“排除”指定名称的path,以逗号分隔,例如:/static, .jpg。如果路径以!开始,表示“不排除”特殊目录。例如:.jpg, !/uploads/*.jpg表示排除所有JPG图像文件,但不排除/uploads目录下的JPG图像文件;可选的参数:“略过”指定名称的path,以逗号分隔,例如:/myservlet, *.jsp。和excludes参数一样,也支持!前缀,表示“不要略过”特殊目录;匹配所有的path。WebxFrameworkFilter处理一个WEB请求的过程如下:

如图所示,WebxFrameworkFilter接到请求以后,就会调用WebxRootController。从这里开始,进入Spring的世界,此后所有的对象:WebxRootController、WebxController、RequestContext、Pipeline等,全部是通过SpringExt配置在Spring Context中的。WebxRootController对象存在于root context中,它被所有子应用所共享。它会创建RequestContext实例 ------ 从而增强request、response、session的功能。接下来,WebxController对象会被调用。WebxController对象是由每个子应用独享的,子应用app1和app2可以有不同的WebxController实现。默认的实现,会调用pipeline。Pipeline也是由各子应用自己来配置的。假如pipeline碰到无法处理的请求,如静态页面、图片等,pipeline应当执行<exit/> valve强制退出。然后WebxRootController就会“放弃控制”,这意味着request将被返还给/WEB-INF/web.xml中定义的servlet、filter或者返还给servlet engine本身来处理。
MVC理解,MVC 是一种使用 MVC(Model View Controller 模型-视图-控制器)设计创建 Web 应用程序的模式:Model(模型)是应用程序中用于处理应用程序数据逻辑的部分。通常模型对象负责在数据库中存取数据。View(视图)是应用程序中处理数据显示的部分。通常视图是依据模型数据创建的。Controller(控制器)是应用程序中处理用户交互的部分。通常控制器负责从视图读取数据,控制用户输入,并向模型发送数据。MVC 分层有助于管理复杂的应用程序,可以在一个时间内专门关注一个方面。例如,您可以在不依赖业务逻辑的情况下专注于视图设计。同时也让应用程序的测试更加容易。MVC 分层同时也简化了分组开发。不同的开发人员可同时开发视图、控制器逻辑和业务逻辑。
十一、webx3的启动过程和webx3的一次请求流程:地址
十二、HSF学习
HSF作为阿里的基础中间件组件,旨在为集团应用提供一个分布式的服务框架,HSF 从分布式应用层面以及统一的发布/调用方式层面为大家提供支持,从而可以很容易的开发分布式的应用以及提供及使用公用功能模块,而不用考虑分布式领域中的各种细节技术,例如进程通讯、性能损耗、调用的透明化、同步/异步调用方式的实现等等问题。HSF是一个 RPC 框架,远程调用对端的地址就是由 ConfigServer 来推送的,这样用户只需要配置自己的服务端或者消费端,不需要对自己的地址进行管理。我们调用远程服务的方式有很多,比如发一个http请求过去,返回一个json数据,直接用jasonRpc的协议,或者webservice等。但是都有一个共同的问题,对开发人员不友好,它需要侵入业务流程,不得不让上层应用在代码中为rpc调用写一些复杂丑陋的代码。而HSF是基于接口编程的。如果我要调用某个服务,那我只要拿到这个服务的接口,直接调用就可以了。只要把接口注册成一个远程调用的接口,对应用来说就不需要做任何事情。
注册中心configServer,我想调用一个服务,首先我需要知道这个服务的机器的地址,端口号是多少。在hsf中这个信息就保存在注册中心上也就是ConfigServer。我理解的它的作用就是管理整个分布式集群里所有的服务对应服务提供者ip的对应关系,方便扩容缩容,服务地址ip的变化。通过注册中心远程调用服务的过程可以用下图来描述。

ConfigServer是个推送模型,当服务初始化消费者去订阅的时候就会推送地址,每当服务提供者发生变动(扩容,缩容)时,也会像消费者进行推送。那推送模型会有什么好处,会存在什么问题?TODO。

HSF架构图:
Proxy层:主要处理一些HSF和应用交互的一些逻辑,比如说做接口的代理,比如说去执行业务的方法。
Remoting层:主要处理一些网络层中的应用层数据,和传统的应用层的数据有区别的是,他是一种网络协议,但他是处于TCP之上的,也就是网络协议中最高成的应用层。其实主要是处理RPC协议。
十三、

 浙公网安备 33010602011771号
浙公网安备 33010602011771号