
哈希表概述及其存储过程(存取原理)
哈希表概述及其存储过程(存取原理)
1.哈希表的数据结构
jdk1.8之前 数组+(单)链表
jdk1.8之后 数组+(单)链表+红黑树
加入红黑树的好处,当表够长的时候,查询速度慢,此时,把表转化成红黑树,增加查询速度
2.哈希表如何做到的key值不重复(去重)
- 先获取哈希值并比较,如果哈希值不一样,就直接存
- 如果哈希值一样,比较内容
- 如果内容不一样,直接存
- 如果内容一样,后面的会覆盖前面的
3.存储细节
- 哈希表底层数据初始数组长度为16,是在第一次put的时候长度才是16,就只是new完,长度为0
- 哈希表会自动扩容,每次扩2倍
- 当数组容量达到75%时 扩容2倍
- 0.75称之为加载因子,意思是当存储元素达到当前数组(每扩一次数组容量都会变化)容量的0.75倍后会自动扩容2倍
- 当数组中一个位置上的链表长度超过8并且数组总长度超过64时,链表会转化成红黑树
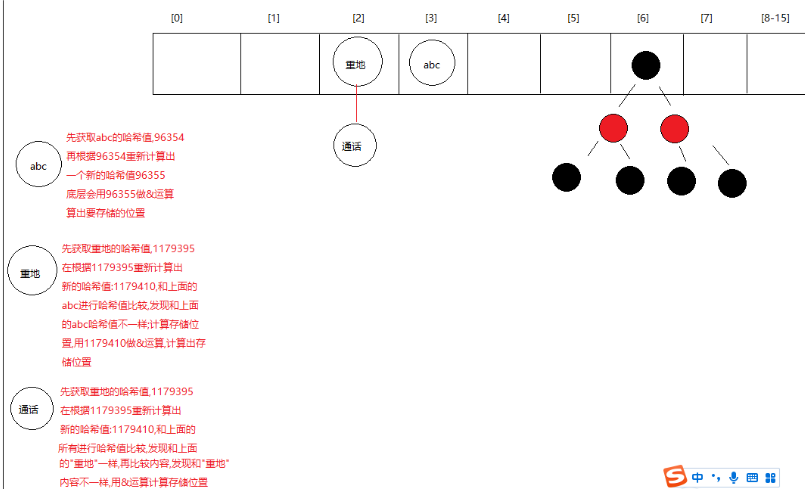
存储过程:(要存储的元素 abc 通话 重地)
-
new,不创建数组
public static void main(String[] args) { HashMap<String,String> hashMap=new HashMap(); } -
存储第一个元素
哈希表的存储过程(存取原理):每存入一个新的元素都要走以下五步
(1)调用对象的hashCode()方法,获得要存储元素的哈希值。
hashMap.put("abc");//-----------------------new String("abc").hashCode()=96354
(2)将哈希值与表的长度(即数组的长度)进行求余运算得到一个整数值,该值就是新元素要存放的位置(即是索引值)。
如果索引值对应的位置上没有存储任何元素,则直接将元素存储到该位置上。
如果索引值对应的位置上已经存储了元素,则执行第3步。
(3)遍历该位置上的所有旧元素,依次比较每个旧元素的哈希值和新元素的哈希值是否相同。
如果有哈希值相同的旧元素,则执行第4步。
如果没有哈希值相同的旧元素,则执行第5步。
(4)新元素调用equals方法与旧元素比较内容是否相同。
如果返回true,用新的元素替换老的元素,停止比较。
如果返回false,则回到第3步继续遍历下一个旧元素。
(5)说明没有重复,则将新元素存放到该位置上并让新元素记住之前该位置的元素。
分类:
java笔记


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY