
一、什么是朴素贝叶斯
1.定义
贝叶斯分类是统计学中的一类分类算法,这类算法以贝叶斯定理为基础。
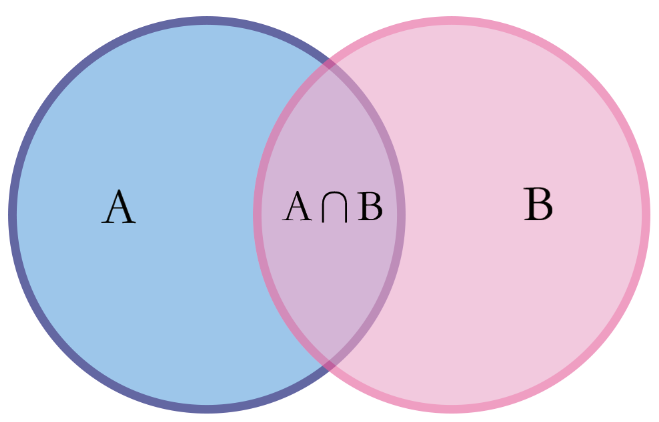
已知两个独立事件A和B,事件B发生的前提下,事件A发生的概率可以表示为P(A|B),即上图中浅紫色部分占粉色部分的比例,即:
![]()
公式中,P(A)也叫做先验概率,P(A|B)叫做后验概率),朴素贝叶斯分类是贝叶斯分类中最简单、最常见的方法。
2.原理
根据特征的先验概率(训练样本分析得到的概率),利用贝叶斯公式计算出其后验概率(要分类对象特征的条件概率),选择概率值最大的类作为该特征所属的类。
使用最大似然估计可以估计朴素贝叶斯分类器的参数并做出预测:
先验概率可以通过下面这个公式求得:
![]()
条件概率可以通过下面这个公式求得:
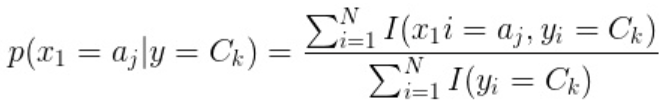
最后就得到了用于估计朴素贝叶斯分类器参数的核心公式:
![]()
3.何为“朴素”
称为朴素贝叶斯分类是因为其朴素的思想基础:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。这就好比讲英语的金发白人我们会天然认为是外国人。
为使模型容易求解,朴素贝叶斯假定各特征是相互独立的,这个假设使得朴素贝叶斯更加简单,但有时会牺牲一定的分类准确率。
该假设可以简化条件概率的求解,即
![]()
则
![]()
其中 x(i) 代表某特征, ck代表某类别,n为特征数。
4.三种模型
①多项式模型
多项式模型在计算先验概率P(yk)和条件概率P(x∣yk)时,会做一些平滑处理。多项式模型中,重复出现的词语在统计和判断时都视为出现了多次。
先验概率:某一类别出现的概率
![]()
Nyk:类别为yk的样本个数
N:样本总数
k:类别数
α:平滑值
条件概率:某一类别下某一特征出现的概率
Nyk:类别为yk的样本个数
n:特征数
α:平滑值
Nyk,xi:类别为yk的类别中,第i维特征,特征值为xi的样本数
当α=1,叫拉普拉斯平滑(Laplace smothing)
当α=0,不做平滑,可能会导致条件概率P(x∣yk)为0。因为P(xi∣yk)可能为0。
当α=1,叫Lidstone 平滑
②高斯模型
特征维连续变量,如特征为人的身高、体重,用多项式模型容易导致P(x∣yk)为0(当α=0时),即使做平滑,此时的条件概率也难以描述真实情况。
此时应使用高斯模型。高斯模型假设每一维特征符合高斯分布,也叫正态分布。高斯模型根据每一维的均值、方差,得到每一维的密度函数,根据密度函数就可以得到当前维度值的密度函数值,以密度值作为条件概率的值。
条件概率:
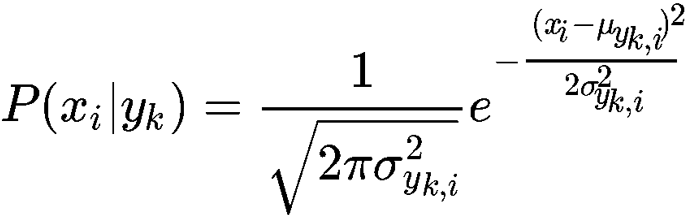
P(xi|yk):类别 yk中,第 i维特征,特征值为xi的概率。
σyk,i:类别yk中,第i维特征的方差。
μyk,i:类别yk中,第i维特征的均值。
③伯努利模型
与多项式模型一样,伯努利模型也适合离散特征。伯努利模型的每个特征的值只能是true和false,或者1和0,即特征有没有在一个文档中出现。伯努利模型中,重复出现的词语在统计和判断时都视为出现了一次。这样处理比较方便,但丢失了词频信息。
条件概率:
当特征值xi=1:
P(xi∣yk)=P(xi=1∣yk)
当特征值 xi=0:
P(xi∣yk)=1−P(xi=1∣yk)
P(xi|yk):类别 yk中,第 i维特征,特征值为xi的概率。
5.朴素贝叶斯分类的优缺点
①优点
(1) 算法逻辑简单,易于实现(算法思路很简单,只要使用贝叶斯公式转化)
(2)分类过程中时空开销小(假设特征相互独立,只会涉及到二维存储)
②缺点
理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
二、利用朴素贝叶斯实现垃圾邮件分类
由于书上所给例子已经实现了英文垃圾邮件分类,故在此尝试中文垃圾邮件分类。
主要思路:垃圾邮件分类是一个分词并记录词频的过程。
1.关于数据集
普通邮件示例:
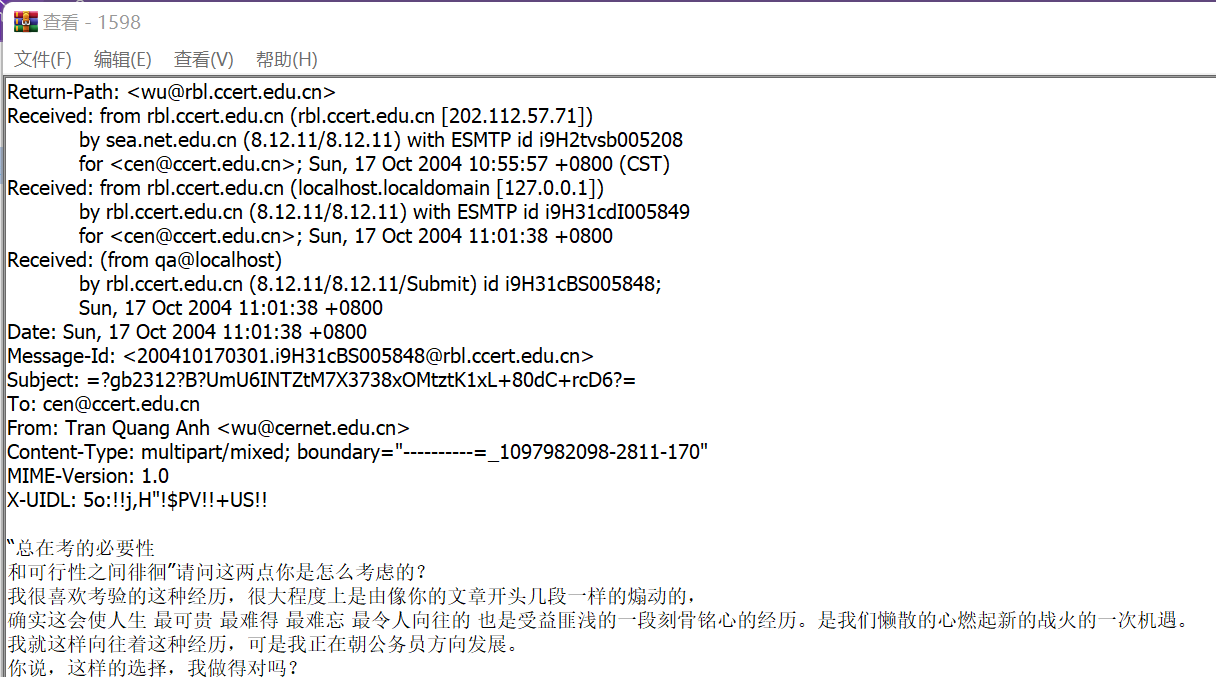
垃圾邮件示例:
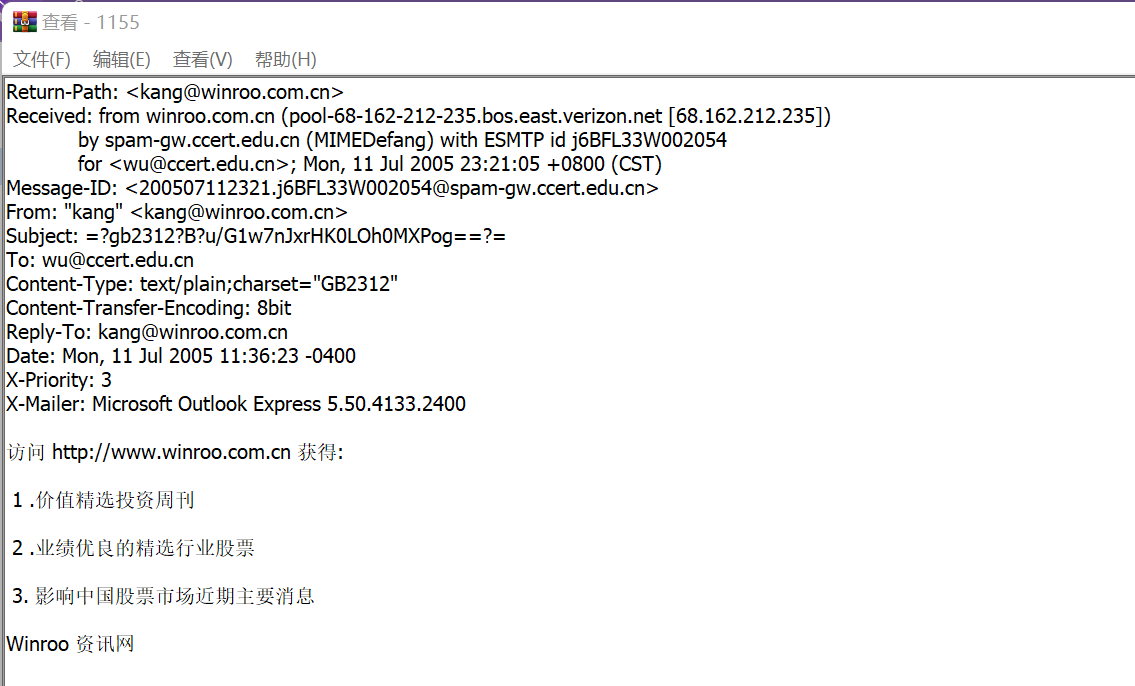
测试集test中包含392个待分类的邮件文本。
2.代码实现
①由于数据是中文的,因此用到了jieba分词模块对训练集分词,并用停用表进行简单过滤,然后使用正则表达式过滤掉邮件中的非中文字符。
import os import jieba import re from tqdm import tqdm spam_files = os.listdir('./data/spam/') stop_words = [] with open('./data/中文停用词表.txt', encoding='GBK') as fp: for line in fp.readlines(): stop_words.append(line.replace('\n', '')) #print(stop_words) def get_word_set(file_name): rule = re.compile(r"[^\u4e00-\u9fa5]") #过滤掉非中文字符 word_set = set() with open(file_name, encoding='GBK') as fp: for line in fp.readlines(): line = rule.sub('', line) #print(line) words = list(jieba.cut(line)) for word in words: if word != None and word not in stop_words and word.strip() != '': word_set.add(word) return word_set
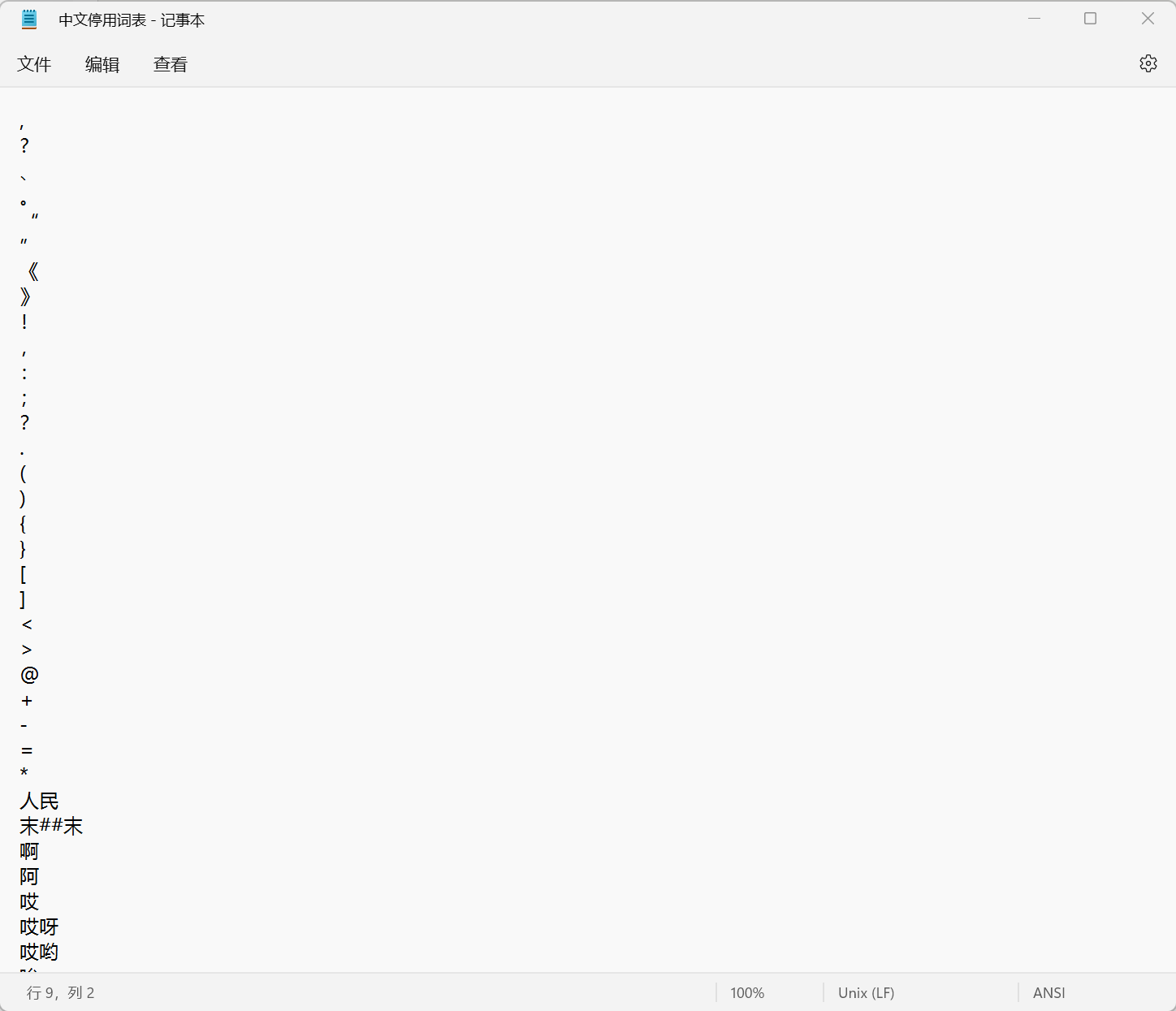
增加“中文停用词表.txt”辅助删除其中的干扰字符和无意义词汇,例如【】*。、,等等,这些词对分类没有影响,去除掉这些词可以减少计算量。
②分别保存正常邮件与垃圾邮件中出现的词有多少邮件出现该词,得到两个词典。
def stat_words(root_dir): ''' 统计邮件中出现各个词的次数 比如:“欢迎”在垃圾邮件中出现了20次,在非垃圾邮件中出现了4次。 如果一个词在一封邮件出现多次,则只按一次计算。 这样就能计算P(词|垃圾)和P(词|非垃圾)了,分别记为pw_s和pw_n ''' files = os.listdir(root_dir) word_cnt = {} for idx, f in enumerate(tqdm(files)): word_set = get_word_set(os.path.join(root_dir, f)) for word in word_set: if word not in word_cnt.keys(): word_cnt[word] = 1 else: word_cnt[word] += 1 #if idx > 200: # break return len(files), word_cnt n_normal_files, normal_word_cnt = stat_words('./data/normal/') n_spam_files, spam_word_cnt = stat_words('./data/spam/')
③求得垃圾邮件概率
公式引入:
我们要做的是计算在已知词向量w=(w1,w2,...,wn)的条件下求包含该词向量邮件是否为垃圾邮件的概率,即求:
其中, s表示分类为垃圾邮件。
根据贝叶斯公式和全概率公式:
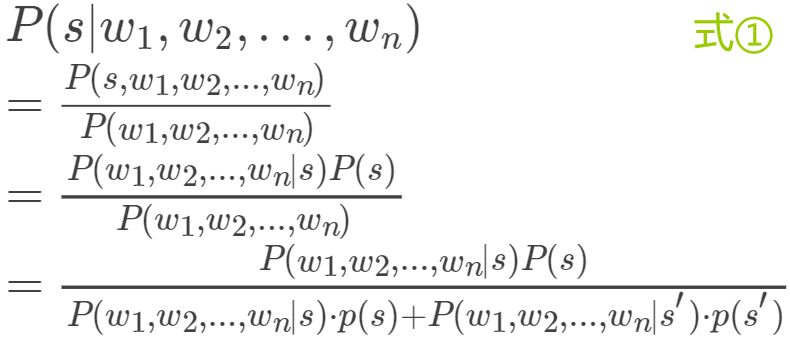
根据朴素贝叶斯的条件独立假设,并设先验概率 P(s)=P(s')=0.5,上式可化为:

再利用贝叶斯公式,将式子化为:
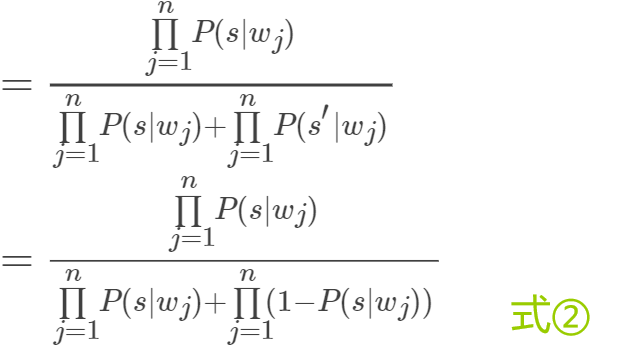
至此,我们接下来会用式②来计算概率P(s|w),因为通过式②可以将关于s′的部分用s表示,方便计算。
对测试集中的每一封邮件做同样的处理,并计算得到P(s|w)最高的15个词,在计算过程中,若该词只出现在垃圾邮件的词典中,则令 P(w|s′)=0.01,反之亦然;若都未出现,则令 P(s|w)=0.4。
(PS:这里做的几个假设基于前人做的一些研究工作得出的)
④判断词汇出现概率与阈值的关系
对得到的每封邮件中重要的15个词利用式②计算概率,若概率>阈值α(一般设为0.9),则判为垃圾邮件,否则判为正常邮件。
f in os.listdir('./data/test/'): word_set = get_word_set(os.path.join('./data/test/', f)) word_prob = {} for word in word_set: if word in spam_word_cnt.keys() and word in normal_word_cnt.keys(): pw_s = spam_word_cnt[word] / n_spam_files pw_n = normal_word_cnt[word] / n_normal_files elif word in spam_word_cnt.keys(): pw_s = spam_word_cnt[word] / n_spam_files pw_n = 0.01 #这个值是前人的经验值 elif word in normal_word_cnt.keys(): pw_s = 0.01 pw_n = normal_word_cnt[word] / n_normal_files else: pw_s = 2 pw_n = 3 #另ps_w=0.4,这个值也是前人的经验值 ps_w = pw_s / (pw_s + pw_n) ''' p(s|w) = p(w|s) * p(s) / p(w) = p(w|s) * p(s) / (p(w|s) * p(s) + p(w|n) * p(n)) 这里p(s)和p(n)相等,都是0.5,因为两种邮件数量基本一致,所以消去了 = p(w|s) / (p(w|s) + p(w|n)) ''' word_prob[word] = ps_w sorted(word_prob.items(), key=lambda x : x[1], reverse=True)[0:15] #print(word_prob.items()) ps_w_ = 1.0 ps_n_ = 1.0 for word, ps_w in word_prob.items(): ps_w_ *= ps_w ps_n_ *= (1 - ps_w) final_ps_w = ps_w_ / (ps_w_ + ps_n_) #阈值α(一般设为0.9) if (int(f) > 1000 and final_ps_w > 0.9) or (int(f) < 1000 and final_ps_w <= 0.9): correct += 1 else: wrong += 1 print(int(f), final_ps_w) print('correct:', correct, 'wrong:', wrong, '精确度:', correct / (correct + wrong))
实现结果:

测试集中近四百个邮件分类结果准确率为95.15%,可见在仅统计词频计算概率的情况下,朴素贝叶斯分类结果还是相当不错的。
===============================================
附源码:
链接:https://pan.baidu.com/s/1nhGFNwQjPIVe6aBrq5bhdA
提取码:cxr6
数据集:
链接:https://pan.baidu.com/s/1MmD63trdQvM79gZBRb6Vjw
提取码:6cxr

 浙公网安备 33010602011771号
浙公网安备 33010602011771号