李明特---第一次个人编程作业
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | 数据采集、数据处理、数据分析展示 |
| 作业源代码 | first-personal-work |
| 学号 | 211808553 |
PSP项目计划总结表
| PSP2.1 | Personal Software Process Stages | 预估耗时 | 实际耗时 |
|---|---|---|---|
| Planning | 计划 | 20分钟 | 30分钟 |
| Estimate | 估计这个任务需要多长时间 | 五天 | 三天 |
| Analysis | 需求分析(包括学习新技术) | 一天 | 一天 |
| Coding | 具体编码 | 两天 | 两天 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60分钟 | 60分钟 |
关于git操作
-
最重要的几条git语句
- git config --global user.name 'MingT-L8553'
- git config --global user.email '1071252445@qq.com'
- git clone 远程仓库地址:克隆远程仓库到本地
- git branch:查看当前所有分支,前面有*号表示当前所在分支
- git branch crawl:创建crawl分支(该分支进行数据采集和处理代码的编写)
- git branch chart:创建chart分支(该分支进行数据的展示)
- git checkout crawl:切换当前分支到crawl分支
- git checkout -b chart:创建chart分支并切换至chart分支
- git push origin crawl:将crawl分支推送到远程仓库
- git merge crawl:将crawl分支合并到主分支上
- git branch -d chart:删除chart分支
- git status:查看当前版本库状态
- git add README.md:将修改后的README.md文件添加到暂存区
- git commit -m 'branch commit test':将修改提交给版本库
-
注意
- 合并分支时,比如要将crawl分支合并到main,则当前要在main分支下执行:git merge crawl
-
在当前所处分支上,比如上面当前所处分支为crawl,对本地仓库的任何修改如果没有提交合并到主分支,那么在main分支下查看仓库会发现只有最初的README.md文件是灰色的没有变,另外两个绿色带*号的是在crawl分支上对仓库没有合并的修改,需要在crawl分支下执行以下语句(这里删掉test.py文件)
git add dataDownload.py
git commit -m '21/2/18 Crawling data stage 1'
# 切换分支到main,将crawl分支合并到main分支
git merge crawl -
最后push到远程仓库即可

关于网页内嵌iframe
- iframe,又叫浮动帧标记,是内嵌的网页元素,可以将一个html文件嵌入到另一个html文件中显示
- selenium每次只能在一个页面识别,当网页内嵌了iframe(相当于内嵌了另一个页面),可能查找的标签不在主页面,就会查找不到元素标签
- 当要查找的标签在iframe中时,需要如下操作
-
进入iframe
driver.switch_to.frame("commentIframe") -
在iframe中识别想要查找的标签
clickDiv = driver.find_element_by_class_name("comment-short") -
退出iframe
driver.switch_to.default_content()
-
- 其他操作详见文末参考网址
变更数据爬取方向
- selenium太磨叽了,每集都有上万条评论,主评论下面还有子评论,每次点击查看更多评论只加载出10条新的评论,遂决定更改数据爬取方法。在使用selenium过程中学到了网页内嵌iframe的标签识别,所幸时间没有白费。
- 因为评论是异步加载出来的,想要获取数据包这里有个小技巧
- 我点击四次加载更多评论后,可以发现下图有四次数据传输的,,怎么说?记录?
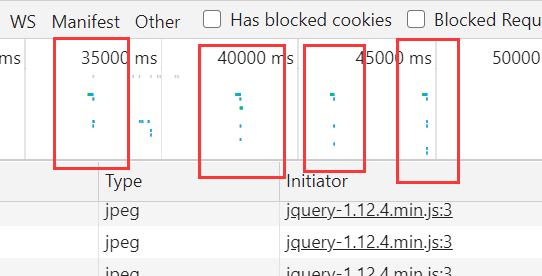
- 把时间定位在某次点击加载更多评论的时间附近,过滤出那个时间段的数据传输
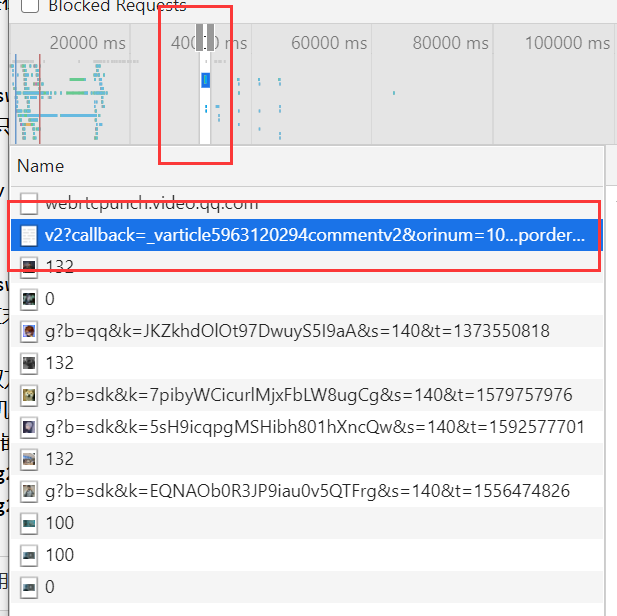
- 很容易就能找到我们想要的包含评论的数据包
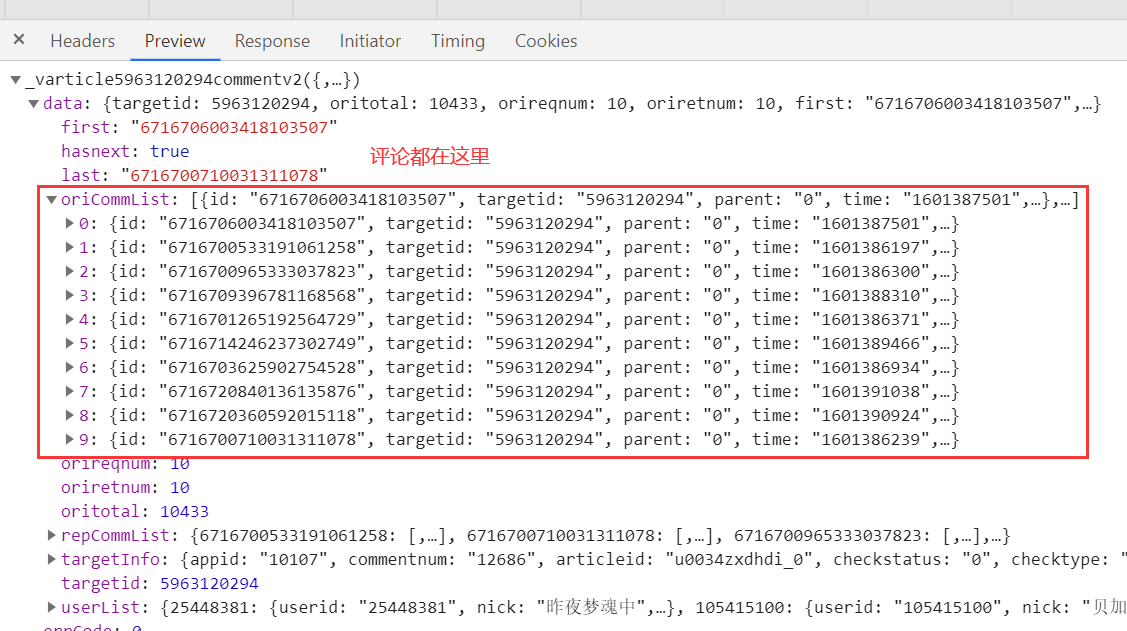
- 至于为什么数据包里的评论顺序和页面上的顺序不一样,是因为数据包里的评论是根据time时间戳来的,到页面上渲染成了点赞量越多就排在前面,然后距离当前时间最近的评论如一小时前两小时前,会排在评论列表的第一位,总之全爬下来即可。
- 每条评论下面显示的子评论只有两条,下图中就是显示出来的子评论,评论就到此为止,不再查看全部评论回复了。
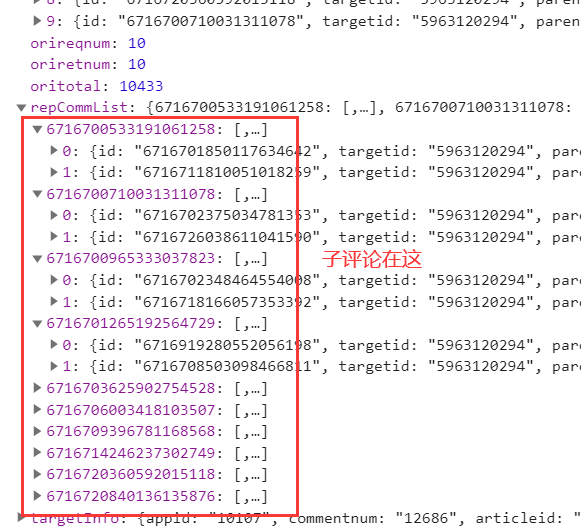
关于请求地址
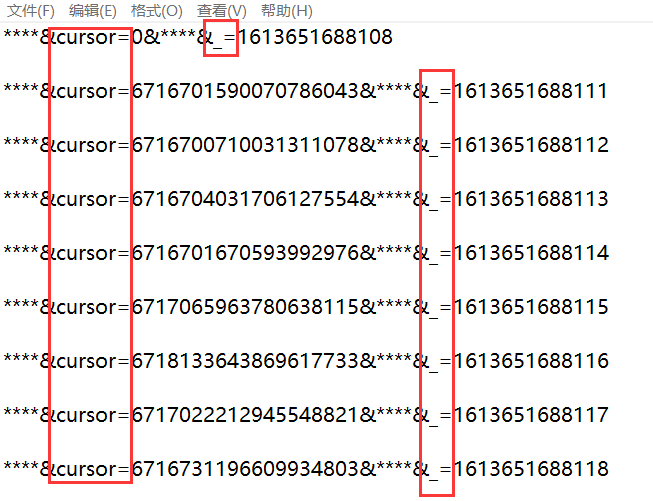
- 摘下几次的Request URL可以发现每次请求地址有三个地方不一样,一个是
targetid,一个是cursor的值,一个是_=的值,如下图,cursor=0是初始请求地址中的参数,targetid每一集都不一样,总共有20集,每一集的首个_=的值也不一样,但是很容易就能发现首个_=的值就是精确到毫秒级的当前时间戳
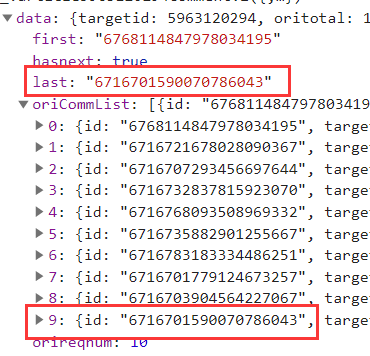
- 下一次的cursor值可以在上一次的数据中获得,如下图,就是上一次加载出的最后一条评论的id值
_=的值可以发现是当前时间戳,初始_=值加3即获得下一次的_=值,之后自增1即可,我刷新了几次也得到了证实👇

-
这个时间戳其实没有必要特意生成,随便给个时间戳作为全局变量应该也是可以的
-
至于要自增多少

oritotal的值就是所有评论的数量,如果抠字眼的话,子评论应该算作评论的回复,不算评论。所以上面的10433应该是所有主评论的个数。- 这样一来,每次加载10条主评论,去掉初始地址返回的10条评论,自增多少应该显而易见了。
-
targetid的值我没有找到更好的方法,现在只能同过selenium进入网页内嵌的iframe中识别标签元素,提取属性值。
爬取数据阶段结束

- 总共爬了35823条评论
- 程序跑了23分钟,,,应该还有优化的余地。
- 主要是selenium花了很长时间,只为了获取网址中的一个参数,文末附了用Beautiful soup的方式进入网页内嵌结构,可惜我没搞出来。
下面是一些主要函数的代码
# 获取每一集的评论的targetid
def getTargetid():
links = getUrllinks()
targetid_list = list()
for link in links:
# 实例化Option对象
chrome_options = Options()
# 把Chrome浏览器设置为静默模式
# chrome_options.add_argument('--headless')
# # 禁止加载图片
prefs = {
'profile.default_content_setting_values': {
'images': 2,
}
}
chrome_options.add_experimental_option('prefs', prefs)
# 设置引擎为Chrome,在后台默默运行
driver = webdriver.Chrome(options=chrome_options)
driver.get(link)
driver.execute_script("scroll(0,50000)")
# 显示等待id为commentIframe的元素加载完成
element = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="commentIframe"]'))
)
driver.switch_to.frame("commentIframe")
iframeDiv = driver.find_element('id','J_CommentTotal').get_attribute('href') # 裂开,一直用bs4的['href']获取属性值,我说怎么搞不出来。。。
targetid = iframeDiv[20:]
targetid_list.append(targetid)
# 退出iframe
driver.switch_to.default_content()
driver.quit()
print("获取每一集的评论的targetid成功!正在return")
return targetid_list # 将会返回20集的评论链接中的targetid
for targetid in targetid_list:
comments_url = 'https://video.coral.qq.com/varticle/' + targetid + '/comment/v2?callback=_varticle' + targetid + 'commentv2&orinum=10&oriorder=o&pageflag=1&cursor=' + str(cursor) + '&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=' + str(last_value)
html = requests.get(comments_url,headers = headers).content.decode()
# 首先获取总评论数,计算需要循环多少次
comTotal = int(re.findall('"oritotal":(.*?),',html,re.S)[0])
ranges = math.ceil((comTotal-10)/10) # 向上取整
last_value = last_value + 3 # 第二页的最后一个值先加三
n = 1
page += 1
for i in range(ranges):
print("正在爬取第{}集,第{}页的评论".format(page,n))
n += 1
# 获取cursor,获取源码用正则表达式识别last
cursor = re.findall('"last":"(.*?)"',html,re.S)[0] # 字符串型
comments_url = 'https://video.coral.qq.com/varticle/' + targetid + '/comment/v2?callback=_varticle' + targetid + 'commentv2&orinum=10&oriorder=o&pageflag=1&cursor=' + str(
cursor) + '&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=' + str(last_value)
last_value += 1 # 第二页之后自增1
html = requests.get(comments_url,headers=headers).content.decode()
comments = re.findall('"content":"(.*?)"',html,re.S) # 这里会返回一个列表,其中有10-30条评论(最初的一页评论每条主评下有两条子评论,之后没有子评论)
for comment in comments:
comments_list.append(comment)
关于分词
- 首先对保存下来的数据进行清洗,去除数字、字母、特殊符号和标点符号等
- 下面是我傻瓜式提取汉字的方法
# 提取所有汉字
def formatTxt():
sentences = list()
with open('comments.txt','r',errors='ignore')as f:
lines = f.readlines()
for sentence in lines:
res = re.findall('[\u4e00-\u9fa5]', sentence)
# 如果有表情字母等非汉字评论,res应该是空的
if len(res) != 0:
result = ''.join(res)
else:
continue
sentences.append(result)
with open('format_comments.txt','w') as f:
for s in sentences:
f.write(s)
关于数据展示(词云图)
1、使用Echarts
- 效果图如下

- 这是所有数据加载出来的样子,有两个问题
- 其一是,有两个很密集的区域,应该是那个区域的关键词次数非常少且很集中
- 其二是,数据量庞大,加载速度缓慢
- 显而易见是关键词太多了,而且很多的关键词的value很少,现在继续对数据进行处理,可以通过降序方法取前100的关键词,代码如下
with open('comments.json','r') as f:
data_dict = json.load(f)
# 对字典进行排序
sort_dict = sorted(data_dict.items(),key=lambda d:d[1],reverse=True)
datas = list()
# 取前100个关键词
for i in range(100):
data = {'name':sort_dict[i][0],'value':sort_dict[i][1]}
datas.append(data)
- 效果好多了

2、使用Pyecharts
- 这个库着实方便,准备好数据就可以直接生成html了
- 虽然很想用,但是没什么技术含量,学不到东西。
将数据渲染到html中
- 这个过程很艰辛,没有一点后端的基础,做起来很崩溃。这方面真的很讨厌,有时候会因为一个非常没有价值的错误卡上很久,浪费很长时间。比如
request.responseText写成了request.requestText还在那捶胸顿足地找哪里出了问题,怎么跑不出来😭等发现问题的时候,直接原地升天😇
问题1、Cross origin requests are only supported for protocol schemes: http, data, chrome, chrome-extension, chrome-untrusted, https.
- 这个应该就是老师说的跨域问题吧?我也不晓得怎么解决,就试着把json数据和html等文件全都放在了云服务器上。因为老师给的两种方法,我一个都没学会😥别说我没认真学,我一把鼻涕一把泪地告诉你是我太菜了😟
问题2、就是那个编码问题,虽然是些很简单的问题,但是比较细节,记录一下加深印象,下次说不定还会碰上。
- json数据规定key和value需要用双引号括起来,不能用单引号。
- 关于json.dumps()、dump()、loads()、loads()
- 编码问题,dump后打开文件里面的汉字都变成了ascii 字符码,看着不是很爽,需要添加一个参数
ensure_ascii = False
with open('resultData.json','w',encoding='utf-8') as f:
# 添加参数,ensure_ascii = False ,它默认是True
json.dump(datas,f,ensure_ascii=False)
- 网上有Ajax什么的渲染数据的模板,我copy下来改来改去也搞不出来,没有一点语法基础,当个cv战士都没资格
- 实在没办法了就用仅有的一点js知识勉强实现了吧😥比较low
window.onload = function(){
var url = 'resultData.json';
var request = new XMLHttpRequest();
request.open("get",url);
request.send(null);
request.onload = function(){
// echarts中的data实际上是一个jsonnarray对象,所以返回一个json数组即可实现动态加载
var jsonObj = new Array();
if (request.status == 200) {
// console.log(request);
// console.log(request.responseText)
//将获取的json数据赋值给data_json
var data_json = request.responseText;
//转换成json对象
var obj = eval("("+data_json+")");
// console.log(obj[0])
for (var i = 0; i < obj.length; i++) {
jsonObj.push({
"name":obj[i].name,
"value":Number(obj[i].value)
});
}
// console.log(jsonObj);
chart.setOption({
series:[{
type:'wordCloud',
data:jsonObj
}]
});
}
}
}
最后贴上词云
过程中遇到的问题
- 最大的问题就是使用git管理项目仓库了
- 因为之前从没使用过,对其中的规则和流程不是太清楚,没有三个分支分工协作的概念,没有给chart和crawl分支创建独立文件夹,所有文件大杂烩地放在一起,有时候在某个分支下对另一个分支下的文件进行了操作,导致分支合并冲突,真的是要崩溃了。
- 也尝试过整理一下,但是剪不断,理还乱。最后所幸是摸清了一点,下次作业保证不会像这次一样了。
参考网址
网页内嵌iframe元素定位selenium
网上还有网页内嵌iframe元素定位BeautifulSoup方法,但是我没有实现
中文停用词表
jQuery+Ajax+js实现请求json数据并渲染到html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号