知识图谱
1.是什么
语义网络,基于图的数据结构【类似于:堆栈】
由节点和边组成【图谱由很多三元组组成】
节点:实体
边:实体之间的关系
2.为什么
3.怎么用
知识图谱中的实体识别
1.多重嵌套实体怎么识别,网络怎么修改
方法一:
通过动态的堆叠flat NER layer[普通的BiLSTM+CRF组合],来生成不同层次的标签;过程是如果识别出了任何实体,则引入新的flat NER层,并且合并当前flat NER层的每个检测到的实体的embedding以组成该实体新的表示,然后将该表示传递给新的flat NER层作为输入。否则,模型终止堆叠,从而完成实体识别。
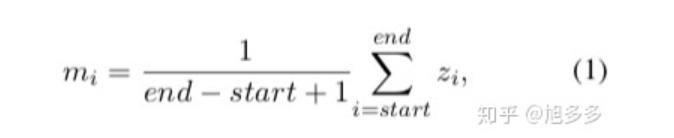
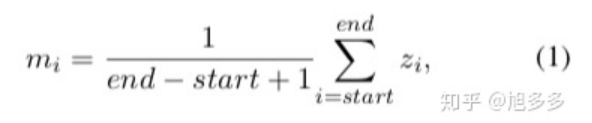
Zi是对应实体的embedding,mi是合并后的新的表示。这样可以充分利用实体的内部信息来加强外部实体的识别;
第一层的输入与其他层的有所不同,输入是字符级别的embedding与预训练好的词级别的emdedding相及联;这里利用字符级别的embedding是为了模型能够学习到类似于前缀后缀这样的信息,来解决OOV的问题。
方法二:
给定一个文本序列X,它的长度为n,我们要抽取出其中的每个实体,其中实体都有各自的实体类型。
假设该数据集的所有实体标签集合为Y,那么对其中的每个实体标签y,比如地点LOC,都有一个关于它的问题q(y)。
这个问题可以是一个词,也可以是一句话等等。现在,我们给模型输入X和q(y),就可以期望模型输出所有具有标签y的所有实体。
<1>训练数据如何构建呢?
首先来构造问题q(y)。
用“标注说明”作为每个标签的问题。
“标注说明”,是在构造某个数据集的时候提供给标注者的简短的标注说明。
在有了问题q(y)之后(现在假设问题的长度为m),我们就有了一个训练实例三元组(Question, Answer, Context)==>(q(y), Answer, X),这里Answer就是对应的所有实体。
我们用x(start:end)表示其中的实体。其中start是实体的开始位置,end是实体
<2>模型细节
用BERT作为主体模型,输入到BERT的就是{[CLS],q(1),……, q(m),[SEP],x(1),…… ,x(n)},x和q对应上面的context文本和问题
其中[CLS]和[SEP]是特殊符号,然后得到原文的表示矩阵E,它的形状为n*d,这里n是原文X的长度,d是BERT最后一层的向量维度。
传统的MRC模型抽取答案的方法是预测它的开始位置和它的结束位置,这相当于2个n分类[对整体句子而言:开始/结束分别是n个字符中的哪个,假如针对每个字符分类是否是开始/结尾,可能会违反约束],分别去在n个字符中预测开始位置和结束位置。
在NER中,原文里可以有很多实体,甚至还可能嵌套,所以这种方法就不适用,基于此,我们采用2个2分类[对n个字符分别而言]:对每个字符,它有两个预测结果,即是不是“可能”成为开始位置,是不是“可能”成为结束位置。
两个参数T(s)和T(e),分别去和BERT出来的表示做点积[PS1]并得到概率分布:P(s) =softmax(E·T(s)), P(e) =softmax (E·T(e))。
现在,对P(s),P(e)的每一行,构成了一个是或不是(第一个位置为“不是的概率”,第二个位置为“是的概率”)开始或结束位置的概率分布。
eg:P(e)的第一行是[0.6,0.4],那么我就可以认为第一个token不是开始位置;
P(e)的第三行是[0.1,0.9],那么第三个token就可能是实体的结束位置。
对P(s),P(e)每行做argmax,就得到了两个长度为n的0-1序列I(s)和I(e),如果第k个位置是1,那么说明第k个token就可能是开始或结束位置。
现在对I(s)中每个为1的位置i,和I(e)中每个为1的位置j且满足i<=j的连续字符序列x(i:j),计算x(i:j)为实体的概率 p(i:j)=sigmoid(m· [E(i); E(j)])即可。得到的这个概率就是x(i:j)是实体类型为y的实体的概率。
<3>损失函数
三个损失,分别是开始位置损失、结束位置损失和实体损失,分别定义如下:

分别把预测的和真实的结果做交叉熵。然后加起来就是最后的损失。
在推理的时候,先得到I(s)和I(e),然后根据p(i,j)的得分去预测即可。如果p(i:j)>0.5,我们就认为x(i:j)是实体,否则就不是。
PS1:点积是什么? LSTM中的运算是什么?
<1>两个向量a = [a1, a2,…, an]和b = [b1, b2,…, bn]的点积定义为: a·b=a1b1+a2b2+……+anbn
<2>哈达玛积 规格相同的矩阵对应位置元素相乘
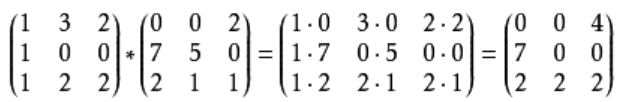
2.实体中通用实体类有什么作用
3.在知识图谱中,实体的边界怎么确定
4.单分类怎么变成多分类 比如给一个音乐打好几个标签
5.有时候会问到,y是什么
NER中Y一般指实体标签集合为Y
超长文本LSTM怎么处理 区分句子和段落级别
从A到B怎么走
同一个类别有多个类 BIO标注不行
多分类 输出几个sequence y类别怎么定义 输入的label长什么样
引用&感谢:
https://zhuanlan.zhihu.com/p/61162609


