一.初识机器学习
何为机器学习? A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.理解:通过实验 E,完成某一项任务T,利用评价标准P对实验结果进行迭代优化!机器学习主要包括监督学习( supervised)和无监督学习(unsupervised),其他的还有增强学习,推荐系统(recommender systems)等。监督学习是指实验数据当中有可参考的正确输出,通常包括回归问题和分类问题。 回归问题( regression problem)是指预测的值,也就是实验结果是连续的,有准确的数值。分类问题( classification problem)是指实验结果是离散的,不是一个准确的数值。无监督学习指聚类问题,不同于分类。如鸡尾酒会算法,在鸡尾酒会中分辨出人的声音和会场的音乐。
二.单变量线性回归问题(Linear regression with one variable)
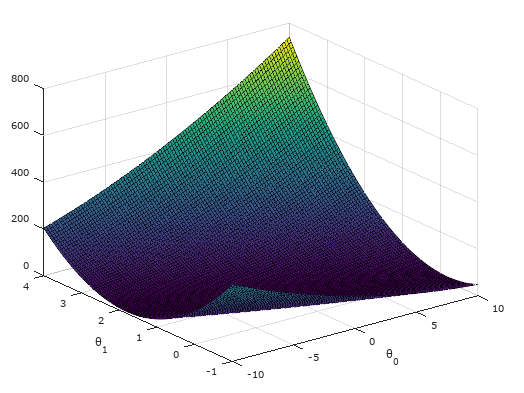
符号标记: m(训练集中样本的数量),X`s(输入变量/特征),Y`s(输出变量/目标变量),(x,y)表示一个训练样本。问题背景:使用房屋面积预测房价!问题描述如下图: 上图从上向下看,表示将训练集带入到学习算法当中,进过训练得到预测函数h ;再从左向右看,将房屋面积带入预测函数,输出预测的房价。 单变量线性回归问题的预测函数可以表示为:hθ (x)=θ0 +θ1 *x(其实就是y=ax+b),其中的θi 为模型参数。所以我们的任务就变成了,使用训练集进行训练,最后得到最佳的θi 值,使得我们得到的预测函数hθ (x)最接近真正的预测函数。完成此任务的方法就叫做学习算法。 代价函数(cost function)也叫平方误差函数:θ (x(i) )和实际房价值y(i) 之间的偏差。因此,我们每次实验的目标就是通过调整参数θi, 使得代价函数的值越来越小,这样我们的模型就越接近真实的预测模型。 根据不同的参数θi, 计算代价函数J (θ0 ,θ1 ),作出图形通常称为contour plot(等高线图),图形特点有局部最优解,也就是局部最低点。如下图所示: 梯度下降(Gradient descent):通过调整参数θi 值,不断的降低代价函数J (θ0 ,θ1 ),最后找到满意的局部最优解的过程。(参数值需初始化) 单变量线性回归问题的梯度下降形式:
三.线性代数知识点回顾
矩阵与向量:ij (i行j列)、向量是一个n*1维的矩阵、向量中的元素:yi 表示第i个元素。m*n 表示m*n维矩阵,矩阵中元素为实数。 A_23=A(2,3)表示取2行3列的值。 矩阵的加减法:只有两个相同维度的矩阵才可以进行加减法。 矩阵乘法不满足交换律A*B!=B*A,但是满足结合律A*B*C=A*(B*C)
矩阵的逆:AA-1 =A-1 A=I,其中A为m*m维的方阵,只有方阵才有逆矩阵。m*n ,B=AT ,Bn*m ,and Bij =Aij
posted on
2018-03-06 21:49
LoganGo
阅读(
1403 )
评论()
收藏
举报


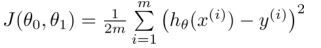
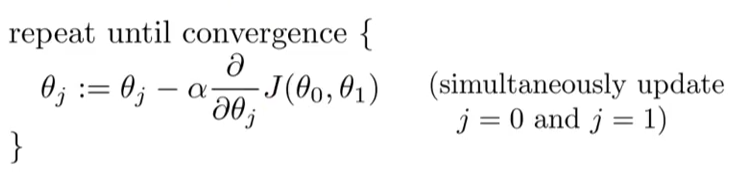

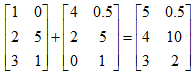
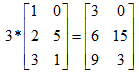
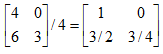
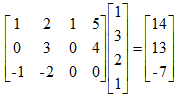
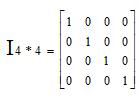

 浙公网安备 33010602011771号
浙公网安备 33010602011771号