

PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) | |||||||||
| · Planning | · 计划 | 120 | 130 | |||||||||
| · Estimate | · 估计这个任务需要多少时间 | 1750 | 2010 | |||||||||
| · Development | · 开发 | 60 | 60 | |||||||||
| · Analysis | · 需求分析 (包括学习新技术) | 300 | 320 | |||||||||
| · Design Spec | · 生成设计文档 | 120 | 150 | |||||||||
| · Design Review | · 设计复审 | 90 | 100 | |||||||||
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 80 | |||||||||
| Design | · 具体设计 | 100 | 120 | |||||||||
| · Coding | · 具体编码 | 360 | 500 | |||||||||
| · Code Review | · 代码复审 | 60 | 90 | |||||||||
| · Test | · 测试(自我测试,修改代码,提交修改) | 180 | 200 | |||||||||
| · Reporting Standard | · 报告 | 120 | 100 | |||||||||
| · Test Repor | · 测试报告 | 60 | 70 | |||||||||
| · Size Measurement | · 计算工作量 | 60 | 50 | |||||||||
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 40 | |||||||||
| · | · 合计 | 1750 | 2010 |
一、解题思路:
拿到题目后,由于没有学过java和python,想借助C++解决这个问题。但由于C++处理中文字符较难且网上C++关于地址划分这部分的资料较少,于是决定放弃用C++进行编码。
在和同学的讨论中得知使用python会比较容易解决这个问题,就初步学习了python。
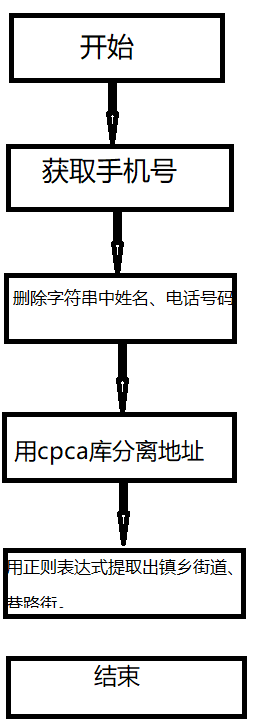
首先,要切去手机号和姓名。在网上搜到了一个自定义获取文本手机号的函数,成功获得手机号。
切去姓名是采用for循环,以‘,’为分割点,用content[:n]获取。
然后要删除字符串中的姓名和电话号码,用re库中,re.sub()切去多余内容,剩下地址部分。
在网上看到一篇关于分离省市区的博客。下载了cpca库,分离地址。
最后用正则表达式匹配,将街道/镇/乡与详细地址分开
二、设计实现过程:
1.文件使用了四个库
import re
import fileinput
import cpca
import numpy as np
re中包含了删除特定字符,找到特定字符等十分简便的用法。该文件中主要用于找电话号码,以及删除特定字符。
比较不同的是,用了cpca库,里面有很多直接分离省市区的方法,而且也提供了优化的方式。
最后一个库用于将DataFrame转换成ndarray再转成list
2.一个获取电话号码的函数
# 自定义获取文本手机号函数
def get_findAll_mobiles(text):
"""
:param text: 文本
:return: 返回手机号列表
"""
mobiles = re.findall(r"1\d{10}", text)
return mobiles
算法的关键就在于用到cpca库。
def main():
content = input()#content是一整行,moblies【0】是电话号码
moblies=get_findAll_mobiles(text=content)#
单元测试:
要注意到一些含特殊字眼的地点名,比如“上街镇”,省份中的一些自治区等,以及省略了“省”、“市”、“区”字眼的情况。
三、改进思路
在性能改进上花费的时间并不多。因为编写代码已经花费了大部分的时间。
在分离省市区的过程中,
jieba分词并不能百分之百保证分词的正确性,在分词错误的情况下会造成奇怪的结果,比如下面:
location_str = ["浙江省杭州市下城区青云街40号3楼"]
import cpca
df = cpca.transform(location_str)
df
输出结果为
省 市 区 地址
0 浙江省 杭州市 城区 下城区青云街40号3楼
于是改为全文模式,不进行分词,直接全文匹配,不过全文匹配模式会造成匹配效率低下。如果地址库中都是些小的省市区名的话,可以选择将lookahead设置得小一点。
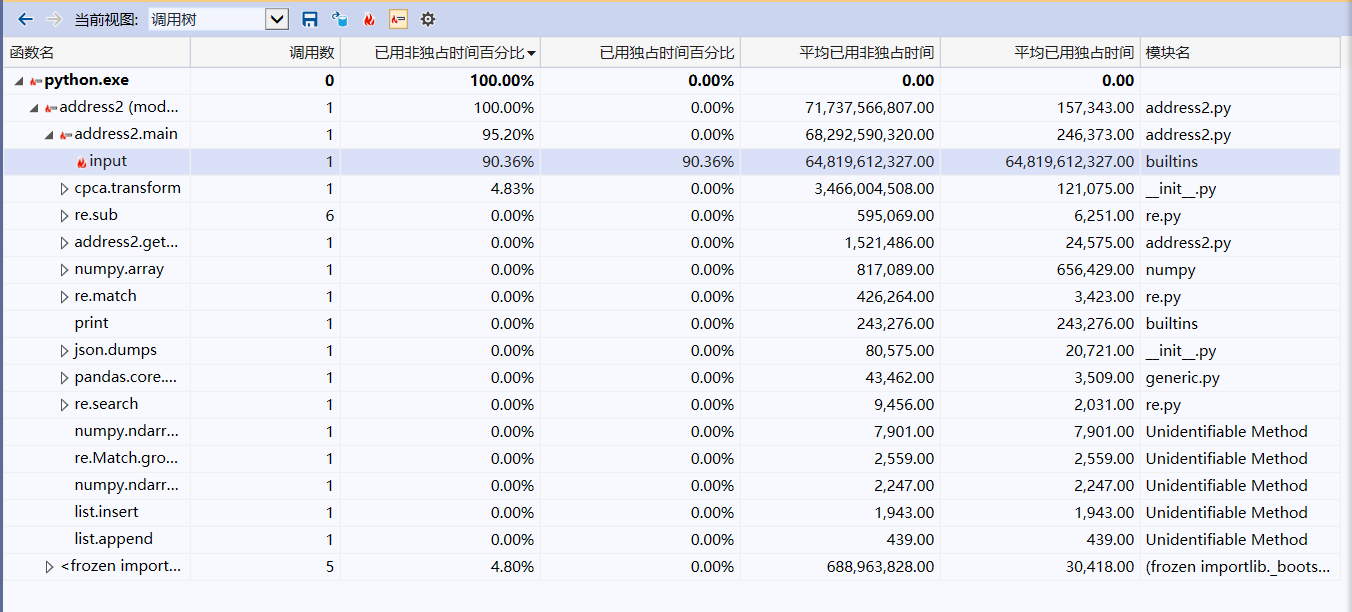
消耗最大的是input函数。
关于分离省市区,https://blog.csdn.net/qq_33256688/article/details/79445792
四、代码说明
1.获取手机号
def get_findAll_mobiles(text):
"""
:param text: 文本
:return: 返回手机号列表
"""
mobiles = re.findall(r"1\d{10}", text)
return mobiles
def main():
content = input()#content是一整行,moblies【0】是电话号码
moblies=get_findAll_mobiles(text=content)#
2.删除字符串中姓名、电话号码
content=re.sub(moblies[0],'',content,1)
content=re.sub(name,'',content,1)
content=re.sub(',','',content,1)
3.用cpca库分离地址,并把DataFrame转换成ndarray再转成list
b=[]
b.append(content)
df = cpca.transform(b, cut=False)
df1=np.array(df)
df2=df.values.flatten()
df3=df2.tolist()
4.用正则表达式提取出镇乡街道、巷路街。
lgcon=df3[3]
temp = re.match('.+?(?:镇|乡|街道)',lgcon)
if temp != None :
str4 = re.search('.+?(?:镇|乡|街道)',lgcon).group()
lgcon = re.sub('.+?(?:镇|乡|街道)','',lgcon)
else :
str4=''
str5=lgcon
df3[3] = str4
df3.insert(4,str5)
#print (str4)
#print(lgcon)
if test == 2:
temp=re.match('.+?(?:巷|路|街)',lgcon)
if temp != None:
str5 = re.search('.+?(?:巷|路|街)',lgcon).group()
lgcon=re.sub('.+?(?:巷|路|街)','',lgcon)
else:
str5=''
df3[4]=str5#路
temp=re.match('.+?(?:号)',lgcon)
if temp != None :
str6 = re.search('.+?(?:号)',lgcon).group()
lgcon = re.sub('.+?(?:号)','',lgcon)
str7 = lgcon
else :
str6 = ''
五、异常处理
jieba分词并不能百分之百保证分词的正确性,在分词错误的情况下会造成奇怪的结果,比如下面:
location_str = ["浙江省杭州市下城区青云街40号3楼"]
import cpca
df = cpca.transform(location_str)
df
输出结果为:
省 市 区 地址
0 浙江省 杭州市 城区 下城区青云街40号3楼
这种诡异的结果是因为jieba本身就将词给分错了,于是改为全文匹配。

六、心路历程与收获
从未有过项目经历。这次的作业拓宽了我的眼界。我明白了,一切从零开始,甚至从未学过一门语言,也是可以边学边查资料边完成作业的。虽然一开始看到题目的时候心里只有恐惧。一步步下来,会发现自己还是有学到很多东西的,比如自己很欠缺的自学能力。这次的作业也让我深刻体会到和其他同学的差距,希望在今后的团队合作中能不拖大家的后腿,慢慢进步!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号